
AIを作る作業は、まるで子供に勉強を教えて、試験に合格できるような力をつけさせるプロセスにそっくりです。でも、ただ教科書を読み込ませればいいというわけではありません。そこには、私たち人間もよく経験するような落とし穴がいくつも潜んでいるのです。
この章では、AI開発において避けては通れない「学習の壁」について、3つのポイントに絞って見ていきましょう。
第1章 AIが直面する学習の壁
AIにとっての学習とは、大量のデータの中から法則やパターンを見つけ出すことです。しかし、どんなに優秀なAIでも、データの与え方や設定を間違えると、とんちんかんな答えしか出せなくなってしまいます。
ここでは、その原因となる代表的な概念を学んでいきましょう。
汎化誤差と訓練誤差
みなさんは学生時代、定期テストの前日に過去問を丸暗記した経験はありませんか。
過去問(練習問題)では満点が取れるようになったとしましょう。でも、いざテスト本番を迎えて、少し数字や出題形式が変わっただけで「あれ、解けない!」と焦ってしまう。これは、本質的な解き方を理解せずに、答えだけを覚えてしまった典型的なパターンです。
AIの世界でも、これと全く同じことが起こります。
まず、手元にある練習用のデータ(訓練データ)に対する予測のズレを訓練誤差と呼びます。これは過去問の採点結果のようなものです。
一方で、AIがまだ見たことのない新しいデータ(テストデータ)に対する予測のズレを汎化誤差と呼びます。これが本番の試験結果です。
私たちがAIに求めているのは、練習問題の正答率ではありませんよね。未知のデータに対しても正しく予測できる能力、つまり汎化性能です。
開発の現場では、訓練誤差はとても小さいのに、汎化誤差が大きくなってしまう現象によく悩まされます。これを過学習(オーバーフィッティング)と言います。「練習番長」になってしまわないよう、AIがいかに「応用力」を身につけられるかが勝負なのです。
バイアスとバリアンス
さて、AIがうまく学習できない原因をもう少し深く掘り下げてみましょう。その原因は大きく2つの要素、バイアスとバリアンスに分解して考えることができます。
少し難しい言葉ですが、人間の性格に例えるとイメージしやすくなりますよ。
バイアス(思い込みの強さ)
バイアスとは、予測モデルが持っている「先入観」や「思い込み」の強さのことです。
もし、ある人が「世の中の鳥はすべて空を飛ぶものだ」という強い思い込み(高いバイアス)を持っていたらどうでしょうか。ペンギンやダチョウを見ても、正しく鳥だと認識できないかもしれません。
AIも同じで、バイアスが高すぎると、データの複雑なパターンを捉えきれず、大雑把な予測しかできなくなります。その結果、練習問題ですらあまり良い点が取れません。この状態を未学習(アンダーフィッティング)と呼びます。
バリアンス(影響の受けやすさ)
一方、バリアンスとは、データの変動に対する「敏感さ」や「ブレの大きさ」のことです。
今度は逆に、人の意見を何でもかんでも真に受けてしまう人を想像してみてください。「Aさんがこう言ったからこうだ」「でもBさんはこう言った」と、細かい情報に振り回されて、自分の意見がコロコロ変わってしまいますよね。
AIでバリアンスが高すぎると、練習データの重要な法則だけでなく、どうでもいい細かいノイズ(雑音)まで必死に覚えようとしてしまいます。その結果、データが少し変わるだけで予測結果が大きく暴れてしまうのです。これが先ほど説明した過学習の正体です。
あちらを立てればこちらが立たず
ここで厄介なのが、この2つはトレードオフの関係にあるということです。
思い込みをなくそうとしてモデルを複雑にすると、今度は敏感になりすぎてバリアンスが高くなります。逆に、安定させようと単純にすると、バイアスが高くなってしまいます。
バイアスとバリアンスの合計 
これが全体の誤差になります。いかにしてこの2つのバランスが良い「ちょうどいい塩梅」を見つけるか。それがエンジニアの腕の見せ所なのです。
次元の呪い
最後に、とても恐ろしい名前の課題を紹介しましょう。「次元の呪い」です。これは、データの項目(特徴量)が増えすぎることによって起こる問題です。
例えば、あなたが理想のパートナーを探しているとします。
条件が「優しい人」だけ(1次元)なら、すぐに見つかりそうですよね。
ここに「身長170cm以上」「年収〇〇万円」「趣味が合う」「料理が得意」……と条件(次元)をどんどん足していったらどうなるでしょうか。
条件が増えれば増えるほど、そのすべてを満たす人を見つけるのは指数関数的に難しくなり、途方もない人数の候補者(データ)が必要になりますよね。
AIもこれと同じです。データを詳しく分析しようとして項目を増やしすぎると、空間がスカスカになってしまい、学習に必要なデータ量が爆発的に増えてしまうのです。計算量も莫大になり、学習がうまくいかなくなってしまいます。
これが次元の呪いです。「データは詳しければ詳しいほど良い」とは限らない、というのが面白いところですね。
第1章では、AI学習における3つの大きな課題について解説しました。
- 汎化誤差と訓練誤差:練習だけでなく本番に強い「汎化性能」を目指すこと。
- バイアスとバリアンス:思い込み(未学習)と敏感さ(過学習)のバランスを取ること。
- 次元の呪い:欲張って項目を増やしすぎると、学習が困難になること。
これらの壁を乗り越えて作られたAIモデルですが、果たして本当に実力があるのかどうか、どうやって確かめればいいのでしょうか。
第2章 その実力は本物?正しい検証手法
AIの性能を正しく評価するための大原則。それは「学習に使うデータ」と「テストに使うデータ」を完全に分けることです。
未知のデータ(汎化誤差)に対してどれだけ通用するかを知るためには、AIにとって「初見」のデータでテストをする必要があります。そのための分け方には、大きく分けて2つの流派があります。
ホールドアウト法
まず紹介するのは、一番シンプルで直感的な「ホールドアウト法」です。
これは、手元にある全データを、ある比率で「学習用」と「テスト用」の2つにパサッと分けてしまう方法です。
例えば、1000問の問題データがあるとします。
そのうちの800問(8割)をAIに渡して勉強させます。そして、残しておいた200問(2割)をテストとして出題し、正解率を測るのです。
メリットとデメリット
この方法の最大のメリットは、手軽さと速さです。
学習もテストも1回ずつ行えばいいので、計算時間が短くて済みます。「とりあえずざっくり性能を知りたい」というときに便利です。
しかし、デメリットもあります。それは、運に左右されやすいということです。
もし、たまたま分けられたテスト用の200問が、すごく簡単な問題ばかりだったらどうでしょう。実力がなくても良い点数が出てしまいますよね。逆に、学習用に回されたデータに偏りがあると、正しく学習できない可能性もあります。
データの分け方ひとつで評価が変わってしまう。これがホールドアウト法の弱点です。
k-分割交差検証
ホールドアウト法の「運任せ」な部分を解消し、もっと厳密に実力を測る方法が、「 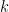
手順をイメージしてみましょう。
- まず、全データを
- そのうちの1つのグループを「テスト担当」に指名し、残りの4グループで学習を行います。
- テストを行い、成績を記録します。
- 次に、別のグループを「テスト担当」に変えて、残りで学習してテストします。
- これを、すべてのグループが1回ずつ「テスト担当」になるまで繰り返します。
5分割なら5回、10分割なら10回、学習とテストを繰り返すわけです。そして最後に、すべての回の成績の平均点を出します。これが最終的な評価になります。
メリットとデメリット
この方法のメリットは、評価の信頼性が非常に高いことです。
すべてのデータが必ず1回はテストとして使われるため、「たまたまテストが簡単だった」という偶然を排除できます。データが少ないときでも、無駄なくデータを活用できるのも強みです。
一方、デメリットは、時間がかかることです。
5分割なら5回、10分割なら10回もAIを一から学習させなければなりません。データが巨大で、1回の学習に何日もかかるようなAIの場合、この方法は計算コストがかかりすぎて現実的ではないこともあります。
どちらを選べばいいの?
では、初心者の私たちはどちらを使えばいいのでしょうか。
基本的には、データがたくさんあって学習に時間がかかるならホールドアウト法。
データが少なめで、時間の余裕があり、厳密に評価したいならk -分割交差検証。
このように使い分けるのが一般的です。
第2章では、AIの実力を測るための試験の「やり方」について学びました。
- ホールドアウト法:データをパサッと2つに分ける。速いけれど運に左右される。
- k -分割交差検証:データをグループ分けして、テスト役を交代しながら全員で回す。時間はかかるけれど、結果は信用できる。
さて、テストを実施したとして、返ってきた結果をどう見ればいいのでしょうか。「正解率90%」なら優秀と言えるのでしょうか?実は、そう単純ではないのです。
いよいよ最終章です。ここまで、AIが学習する際の「課題」と、実力を測る「テスト方法」について見てきました。
テストが終わったら、次に来るのは「成績発表」ですよね。でも、AIの世界では「100点満点中何点」という単純な数字だけでは、そのAIが本当に優秀かどうか判断できないことがあるのです。
例えば、病気を見つけるAIが「全員健康です!」と適当に答えても、たまたま健康な人ばかりの集団なら正解率は高くなってしまいます。でも、これでは見つけたい病気を見逃してしまいますよね。
第3章 AIの成績表を読み解く性能指標
AIの評価において、まず基本となるのが「混同行列」という考え方です。名前は少しややこしいですが、中身はとてもシンプルです。
すべての基本「混同行列」
AIが「〇(ポジティブ)」と答えたか、「×(ネガティブ)」と答えたか。そして実際の正解が「〇」だったか、「×」だったか。この組み合わせは4通りしかありませんよね。
これを整理したものを混同行列と呼びます。ここでは、健康診断(病気=〇、健康=×)を例に考えてみましょう。
- TP(True Positive): 病気の人を、正しく「病気(〇)」と当てた。(大正解!)
- TN(True Negative): 健康な人を、正しく「健康(×)」と判定した。(正解!)
- FP(False Positive): 健康な人なのに、間違って「病気(〇)」と判定した。(誤検知/オオカミ少年)
- FN(False Negative): 病気の人なのに、間違って「健康(×)」と判定した。(見逃し/一番危険!)
この4つの数字を使って、色々な角度からAIの成績を計算していきます。
正解率(Accuracy)
これが一番なじみ深い指標です。テスト全体のうち、どれくらい正解したかを表します。
正解率 
「精度90%!」と言われたら、通常はこれを指します。しかし、先ほど言ったように、データに偏りがある(例:99人が健康で1人だけ病気)場合、全員を「健康」と答えるだけで正解率99%が出てしまいます。そのため、これだけを鵜呑みにするのは危険です。
適合率(Precision)
これは、AIが「〇だ!」と予測した中で、本当に〇だった割合です。「AIの自信の確からしさ」とも言えます。
適合率
例えば、スパムメールのフィルターを想像してください。大事なメールを間違って「スパム(〇)」と判定して捨ててしまったら困りますよね。こういうときは、FP(誤検知)を減らしたいので、この適合率を重視します。「嘘をつかない確率」と言い換えてもいいでしょう。
再現率(Recall)
こちらは、実際に「〇」であるもの全体のうち、AIがどれだけ見つけ出せたかという割合です。「取りこぼしのなさ」を表します。
再現率
がん検診や災害検知システムなどでは、何より怖いのは「見逃し(FN)」です。多少間違って警報を鳴らしてもいいから、危険なものは絶対に見つけてほしい。そんなときは、この再現率を重視します。
F値(F-measure)
実は、適合率と再現率はシーソーのような関係(トレードオフ)にあります。
「絶対に見逃さないぞ(再現率アップ)」と基準を甘くすれば、間違い(誤検知)も増えて適合率は下がります。逆に「確実なときしか言わないぞ(適合率アップ)」と慎重になれば、見逃しが増えて再現率は下がります。
そこで、この2つのバランスを総合的に見るための指標が「F値」です。
F値 
両方の数値が高いときだけ、F値も高くなります。バランスの取れた優秀なAIを目指すなら、この値を目標にします。
その他の重要な指標
少し発展的な内容ですが、以下の指標もよく使われます。
ROC曲線とAUC
AIが「〇か×か」を決める基準(閾値)を少しずつ変えていったとき、性能がどう変化するかをグラフにしたものをROC曲線と言います。
そのグラフの下側の面積をAUCと呼びます。この面積が1に近いほど(グラフが左上に膨らむほど)、どんな基準でも安定して高性能なAIであると言えます。逆に0.5だと、コイン投げ(ランダム)と同じレベルです。
IoUとmAP(画像認識)
写真の中に写っている物体を見つける(物体検出)ときは、計算がもう少し複雑になります。
- IoU(Intersection over Union): 正解の枠と、AIが予測した枠がどれくらい重なっているかを表す指標です。「場所の正確さ」を測ります。
- mAP(mean Average Precision): 複数の種類の物体(犬、猫、車など)を検出する際の、平均的な精度の高さを示す総合得点です。
まとめと今後の学習指針
全3回にわたり、E検定の重要分野である「機械学習の基礎」について解説してきました。お疲れ様でした。
最後に、これまでの内容を振り返りつつ、これから皆さんがどう学習を進めていけばよいか、指針を示して締めくくりたいと思います。
- 用語のイメージを持つ「バイアス」「バリアンス」「適合率」「再現率」など、似たような言葉がたくさん出てきましたね。これらを丸暗記するのではなく、「頑固な人」「オオカミ少年」のように、自分の言葉でイメージできるようにしてください。
- 数式アレルギーを克服する今回紹介したF値などの計算式は、試験でも必ず出題されます。複雑に見えますが、やっていることは四則演算だけです。実際に手で書いて計算してみることで、定着率がグッと上がります。
- Pythonで動かしてみる理論がわかったら、次はプログラミング言語「Python」を使って、実際にこれらの計算をコンピュータにやらせてみましょう。Scikit-learnというライブラリを使えば、今回学んだ検証手法や指標計算は、ほんの数行のコードで実現できます。「あ、これ記事で読んだやつだ!」と繋がった瞬間、学習は一気に楽しくなります。
AIの技術は日進月歩ですが、今回学んだ「学習・評価」の基礎は、どんなに新しい技術が出ても変わらない土台となる部分です。
この土台をしっかり固めた皆さんなら、きっとE検定合格、そしてその先のエンジニアとしての活躍も間違いありません。