
宝くじの当選と明日の天気、どっちが重大?情報量の意外な正体
みなさん、情報の価値ってどうやって決まると思いますか。
実は、情報の世界には情報の重さを測るための、とてもユニークな物差しがあるのです。
それが、今回から全5回にわたってお届けするエントロピーシリーズの第一歩、自己情報量です。
あなたは、友人から「明日は太陽が東から昇るよ」と言われたら、どう反応しますか。
きっと「何を当たり前のことを言っているんだ」と、少し呆れてしまいますよね。
では、逆に「明日は宝くじの一等に当選するよ」と言われたらどうでしょう。
心臓が飛び出るほど驚き、その言葉を何度も噛み締めるはずです。
この反応の違いは、一体どこから来るのでしょうか。
今回は、情報の価値を決める鍵となる、驚きの数値化について詳しく解説していきます。
驚きの大きさを数値にする:自己情報量とは
自己情報量とは、ある出来事が起こったときに、その情報がどれくらい珍しいか、あるいはどれくらい私たちを驚かせるか、という度合いを数値で表したものです。
専門用語では、ある出来事 

そして、その出来事が持っている自己情報量 

この式を見て、数学のログが出てきたからといって、ページを閉じないでくださいね。
ログは、掛け算を足し算に変換したり、非常に大きな数字を扱いやすくしたりするための、とっても便利な魔法の道具なのです。
確率が低いほど、情報の価値は高くなる
この式のポイントは、確率
例え話で考えてみましょう。
例えば、コイントスをして表が出る確率は 
一方で、サイコロを振って 

どちらが、結果を聞いたときに「へぇー、そうなんだ!」という驚きが大きいでしょうか。
当然、確率が低いサイコロの目ですよね。
情報理論では、めったに起きないことが起きたときほど、大きな情報が得られたと考えるのです。
もし、絶対に起きることが起きた場合、その確率は 
当たり前のことには、情報の価値はないということですね。
自己情報量を学ぶメリットとデメリット
この概念を理解すると、どんな良いことがあるのでしょうか。
具体的なメリット
自己情報量という尺度を持つ最大のメリットは、情報の希少性を客観的に評価できることです。
これにより、コンピュータは膨大なデータの中から、異常な数値や珍しいパターンを自動的に見つけ出すことができます。
スパムメールの検知や、工場の機械の故障予兆を見つける技術にも、この考え方が応用されているのですよ。
知っておくべきデメリット
一方で、注意点もあります。
自己情報量はあくまで確率的な珍しさだけを測るものです。
そのため、情報の意味や、人間にとっての重要性は無視されてしまいます。
例えば、「誰かの家の今日の献立」という極めて個人的で珍しいニュースがあったとしても、それが社会的に重要かどうかは、この数値だけでは判断できないのです。
情報の単位はビットで表す
自己情報量を計算したときの単位は、ビット(bit)を使います。
これはコンピュータでおなじみの単位ですよね。
コイントスで表が出るか裏が出るか、という選択肢が 
あなたは、 
これは、 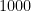
こうして数値化することで、情報の重さを誰にでもわかる形で共有できるようになるのです。
練習問題
第1問:サイコロの目
【問題】 イカサマのない普通の6面体サイコロを1回振ったとき、「1の目が出る」という事象が持つ自己情報量を求めなさい。 (必要であれば log2(3) = 1.58 を使用すること)
【解答】 約 2.58 bit
【解説】
- 1の目が出る確率は 1/6 です。
- 公式「自己情報量 = log2(1 / 確率)」に当てはめると、log2(6) となります。
- log2(6) は、log2(2 × 3) と分解できるので、log2(2) + log2(3) と計算できます。
- log2(2) は「2を何乗したら2になるか」なので 1 です。
- つまり、1 + 1.58 = 2.58 となり、答えは 2.58 bit です。
まとめと今後の学習の指針
今回は、情報の意外性を数値化する自己情報量について学びました。
最後に、今日の内容をおさらいしましょう。
- 情報の価値は、その出来事の珍しさ(確率の低さ)で決まる。
- 確率が低いほど、自己情報量は大きくなる。
- 単位はビット(bit)を使用し、数学的にはログを使って計算する。
さて、次に進むためのステップとして、まずは身の回りの出来事の確率を想像してみてください。
「明日の朝食がパンである確率」と「道端で四つ葉のクローバーを見つける確率」、どちらの情報量が大きいでしょうか。

予測不能なワクワクを数値化!シャノンエントロピーの不思議
前回は、たった一つの出来事が持つ驚きの大きさ、自己情報量についてお話ししました。
でも、私たちの日常はたった一つの出来事だけで成り立っているわけではありませんよね。
例えば、今日の天気は晴れか、曇りか、それとも雨か。
こうしたいくつかの選択肢が組み合わさった全体の状態が、どれくらい「予測しにくいか」を知りたくありませんか?
今回は、情報理論の生みの親であるクロード・シャノンが提唱した、シャノンエントロピーという概念を詳しく紐解いていきましょう。
期待される驚きの平均値:シャノンエントロピーとは
シャノンエントロピーとは、あるシステム全体で、平均してどれくらいの情報(驚き)が得られるかを表す指標です。
一言で言うと、その場の「ザワつき具合」や「デタラメさ」の平均値のことですね。
専門用語では、複数の事象が起こる確率をそれぞれ 


少し難しそうに見えますが、意味はシンプルです。
それぞれの出来事が持つ「自己情報量」に、その出来事が起こる「確率」を掛け合わせて、全部足し合わせているだけなのです。
つまり、平均的な驚きのスコアを出しているということですね!
コインとサイコロ、どちらがエントロピーが高い?
ここで、あなたに質問です。
表か裏かしかないコインを振るのと、1から6まで出るサイコロを振るのとでは、どちらが「次に何が出るか」予想しにくいでしょうか。
答えは、サイコロですよね。
選択肢が多ければ多いほど、そしてそれぞれの選択肢が同じくらいの確率で起こるほど、次に何が起こるか予測がつきにくくなります。
この「予測のつかなさ」こそが、エントロピーが高い状態なのです。
もし、すべての目が均等に出る理想的なサイコロなら、そのエントロピーは最大になります。
逆に、どの面を振っても必ず「1」が出る魔法のサイコロがあったらどうでしょう。
結果は分かりきっているので、驚きはゼロ、つまりエントロピーは
シャノンエントロピーを理解するメリットとデメリット
この平均値を計算できるようになると、どんな世界が見えてくるのでしょうか。
具体的なメリット
シャノンエントロピーの最大のメリットは、データの「圧縮限界」がわかることです。
私たちがスマホで写真を送ったり、動画を見たりできるのは、データをギュッと小さく圧縮しているからですよね。
エントロピーを計算すると、「このデータはこれ以上小さくすると中身が壊れてしまう」という限界ラインが科学的に判明するのです。
まさに、現代のインターネット社会を支える土台となる知識ですね。
知っておくべきデメリット
デメリットとしては、あくまで「平均値」であるため、個別の極端な事例を見落とす可能性があることです。
全体のエントロピーが低くても、その中に一つだけ強烈な自己情報量を持つ出来事が隠れているかもしれません。
分析する際は、全体の平均(エントロピー)と個別の驚き(自己情報量)の両方を見る視点が大切です。
部屋の片付けとエントロピーの関係
エントロピーはよく「乱雑さ」と訳されます。
あなたの部屋を想像してみてください。
本が本棚に、服がクローゼットにきっちり収まっている状態は、どこに何があるかすぐわかるので、エントロピーが低い状態です。
逆に、床に本や服が散乱していると、どこから何が出てくるか分かりません。
これはエントロピーが高い状態です。
情報の世界でも同じです。
データが規則正しく並んでいればエントロピーは低く、バラバラで不規則であればエントロピーは高くなるのです。
第1問:コイントスのエントロピー
【問題】 表と裏がそれぞれ確率 1/2 で出る「公平なコイン」を1回投げるとします。この試行のシャノンエントロピーを求めなさい。
【解答】 1.0 bit
【解説】
- 表が出る時の情報量:log2(2) = 1 bit
- 裏が出る時の情報量:log2(2) = 1 bit
- 平均(エントロピー):(1/2 × 1 bit) + (1/2 × 1 bit) = 1.0 bit
- 1回のコイントスで、ちょうど 1 bit 分の「不確かさ」が解消されることを意味します。
第2問:曲がったコイン(不均質な確率)
【問題】 ある曲がったコインがあり、表が出る確率が 1/4、裏が出る確率が 3/4 であるとします。このコインを1回投げる時のエントロピーを求めなさい。 (log2(3) = 1.58 として計算してください)
【解答】 約 0.81 bit
【解説】
- 表の情報量:log2(4) = 2 bit
- 裏の情報量:log2(4/3) = log2(4) - log2(3) = 2 - 1.58 = 0.42 bit
- エントロピー:(1/4 × 2) + (3/4 × 0.42) = 0.5 + 0.315 = 0.815 bit
- 確率が偏っている(裏が出やすいとわかっている)ため、公平なコイン(1.0 bit)よりも不確かさが低くなります。
第3問:4つの選択肢
【問題】 A, B, C, D の 4 つの選択肢があり、それぞれの出現確率が以下のようになっています。このときのエントロピーを求めなさい。
A:1/2
B:1/4
C:1/8
D:1/8
【解答】 1.75 bit
【解説】
- Aの情報量:log2(2) = 1 bit
- Bの情報量:log2(4) = 2 bit
- Cの情報量:log2(8) = 3 bit
- Dの情報量:log2(8) = 3 bit
- エントロピー: (1/2 × 1) + (1/4 × 2) + (1/8 × 3) + (1/8 × 3) = 0.5 + 0.5 + 0.375 + 0.375 = 1.75 bit
- もし 4 つの確率がすべて 1/4(均等)ならエントロピーは 2.0 bit になりますが、偏りがあるためそれより小さくなります。
まとめと今後の学習の指針
今回は、情報全体の予測しにくさを測るシャノンエントロピーについて解説しました。
ポイントを振り返りましょう。
- シャノンエントロピーは、自己情報量の平均値である。
- 選択肢が等確率でバラバラであるほど、エントロピーは高くなる。
- データの圧縮限界を知るための重要な指標である。
学習の指針として、次は「条件」が加わったときにエントロピーがどう変化するかを考えてみてください。
例えば、「外が暗い」という条件を知ったとき、「今の天気が雨である確率」の驚きはどう変わるでしょうか。
関係性を読み解け!同時エントロピーと条件付きエントロピーの密な関係
前回までは、ひとつの事象、あるいはひとつのシステムの中での乱雑さを考えてきました。
でも、現実の世界では複数の出来事がお互いに影響し合っていますよね。
例えば、「空が曇っている」ことと「雨が降る」ことは、無関係ではありません。
今回は、そんな複数の事象がセットになったときの不確かさを測る、同時エントロピーという考え方をご紹介します。
情報のパズルが組み合わさっていく感覚を、一緒に楽しんでいきましょう!
2つ合わせてどれだけザワつく?:同時エントロピー
同時エントロピーとは、2つの出来事 

同時エントロピー 

この式を日本語で読み解いていきましょう。
は、事象
と事象
が同時に起こる確率を表します。
は、情報の大きさを計算するための対数です。
は、すべてのパターンを合計するという意味の記号です。
つまり、すべての組み合わせについて「その確率」と「その時の驚き(対数)」を掛け合わせ、全部足し合わせたものが同時エントロピーなのです!
例えば、
この
もし
しかし、お互いに関係がある場合は、単純な足し算にはならないのが面白いところです!
第1問:2枚の独立なコイン
【問題】 表と裏が 1/2 ずつで出るコインが2枚(コインA、コインB)あります。この2枚を同時に投げた時の結合エントロピー H(A, B) を求めなさい。
【解答】 2.0 bit
【解説】
- 起こりうるパターンは「表表」「表裏」「裏表」「裏裏」の4通り。
- 各パターンの確率は 1/2 × 1/2 = 1/4 です。
- 各パターンの情報量は log2(4) = 2 bit です。
- エントロピー = (1/4 × 2) + (1/4 × 2) + (1/4 × 2) + (1/4 × 2) = 2.0 bit
- ポイント:2つの事象が完全に独立(無関係)なら、個別のエントロピーを足したもの(1 bit + 1 bit)と一致します。
ヒントをもらうとスッキリする:条件付きエントロピー
ここで、さらに一歩進んで条件付きエントロピーについて考えてみましょう。
これは、ある情報
条件付きエントロピー 

または、同時エントロピーを使って次のように書くこともできます。

専門用語の解説:条件付き確率
数式の中に 
例えば、
第1問:関係性からの推論
【問題】
ある天気 X(晴れ、雨)と、ある人の傘の所持 Y(持っている、いない)の関係を調べました。
- Xのエントロピー H() = 0.8 bit
- X が決まった時の Y の条件付きエントロピー H(Y|X) = 0.3 bit
- このときの結合エントロピー H(X, Y) を求めなさい。
【解答】
1.1 bit
【解説】
- 結合エントロピーには「H(X, Y) = H(X) + H(Y|X)」という便利な関係式があります。
- これは「まず Xの不確かさがあり、その上でXを知ってもなお残るYの不確かさを足せば、全体の不確かさになる」という意味です。
- 計算: 0.8 + 0.3 = 1.1 bit
カンニングとヒントの例え
あなたは、箱の中に何が入っているか当てるクイズに挑戦していると想像してください。
最初は全く見当がつかず、エントロピーは最大です。
でも、誰かが「それは赤いものです」というヒント(情報
すると、答え(
この「ヒントを聞いた後に残ったモヤモヤの量」こそが、条件付きエントロピーなのです。
ヒントが強力であればあるほど、条件付きエントロピーは小さくなります。
もし、ヒントを聞いた瞬間に答えが確信に変わるなら、不確かさは
数学的には、以下の関係が成り立ちます。

全体の不確かさは、「まず
メリットとデメリット
この概念を使いこなすと、どのような視点が手に入るのでしょうか。
具体的なメリット
同時エントロピーや条件付きエントロピーを理解すると、データ間の関連性の強さを精密に測定できるようになります。
例えば、スマホの文字入力の予測変換を思い浮かべてください。
「お疲れ」という文字が打たれたという条件(
これを利用することで、システムはより賢く、効率的な予測ができるようになるのです。
知っておくべきデメリット
デメリットとしては、計算が複雑になりやすい点です。
扱う事象の種類(変数)が増えれば増えるほど、それぞれの組み合わせの確率を把握しなければならず、膨大な計算資源が必要になります。
そのため、実用的なシーンでは、どの情報を条件として選ぶかというセンスが問われます。
まとめと今後の学習の指針
今回は、複数の情報の重なり合いを測る手法を学びました。
- 同時エントロピーは、
- 条件付きエントロピーは、ヒントを得た後に残る不確かさ。
- 情報が得られると、不確かさ(エントロピー)は減少する。
学習の指針として、次は「情報のおかげで、どれだけ不確かさが減ったか」という減少量そのものに注目してみましょう。
この減少量こそが、私たちが本当に知りたかった情報の価値そのものになります。
情報の「重なり」を抜き出せ!相互情報量でつながりを見える化する
前回は、ヒント(条件)をもらうと不確かさが減る、というお話をしましたね。
今回は、その「減った分」にスポットライトを当ててみましょう。
ある情報を知ることで、別の情報についてどれだけ詳しくなれたのか。
その共通部分の大きさを測るのが、今回の主役である相互情報量です。
あなたは、誰かの目を見ただけで「あ、この人怒ってるな」と察したことはありませんか?
「目つき」という情報から「感情」という情報を読み取れたとき、そこには大きな相互情報量が存在しているのです!
情報の共通項:相互情報量とは
相互情報量とは、2つの事象
記号では 
もっと噛み砕いて言うと、「

ここで、 

つまり、この引き算の結果は「ヒントのおかげで解消されたモヤモヤの量」そのものなのです。
集合図で相互情報量をイメージしてみよう
2つの円が重なっている集合図を考えてみましょう。
- 左の円全体が確率変数 のエントロピー H(X)
- 右の円全体が確率変数 のエントロピー H(Y) を表しています。

重なっていない部分
- 左の円のうち、重なっていない部分は H(X∣Y)
→ 「 を知ってもなお残る の不確かさ」 - 右の円のうち、重なっていない部分は H(Y∣X)
→ 「 を知ってもなお残る の不確かさ」
重なっている中心部分
2つの円が重なっている 中央の領域が、
相互情報量 I(X;Y)です。
これは
「 と が共通して持っている情報量」
「一方を知ることで、他方についてどれだけ不確かさが減るか」
を表しています。
重なりの大きさが意味するもの
- 重なりが 大きい
→ と の関係が強く、一方を知ると他方をよく予測できる - 重なりが 小さい(または 0)
→ と はほぼ独立で、片方を知っても役に立たない
図と数式の対応(確認)
この関係が、そのまま 集合図の「全体 − 非重複部分 = 重なり部分」として視覚的に表現されています。
重なりが大きければ大きいほど、一方を知ることで他方を予測しやすくなります。
相互情報量を学ぶメリットとデメリット
この重なりを知ることで、どんな便利なことがあるのでしょうか。
具体的なメリット
相互情報量の素晴らしい点は、どんなに複雑な関係性でも「つながりの強さ」を測れることです。
学校で習う相関係数は、基本的には直線的な関係しか測れません。
しかし、相互情報量を使えば、非線形(折れ曲がったり、複雑に絡み合ったりしている関係)なデータのつながりもバッチリ捉えることができます。
これは、がん細胞の遺伝子解析や、株価の予測など、一筋縄ではいかない分野で非常に重宝されています。
知っておくべきデメリット
デメリットとしては、計算に必要なデータの量です。
「重なり」を正確に測るためには、
データが少なすぎると、たまたま起きた偶然を「強い結びつきだ!」と勘違いしてしまう、過学習のような状態に陥ることがあります。
練習問題
第1問:包含関係から求める
【問題】
ある通信システムにおいて、送信データXと受信データYのエントロピーが以下のように分かっています。このときの相互情報量 I(X;Y)を求めなさい。
- 送信側のエントロピー H(X) = 2.0 bit
- 受信側のエントロピー H(Y) = 2.0 bit
- 全体の結合エントロピー H(X, Y) = 3.5 bit
【解答】
0.5 bit
【解説】
- 相互情報量は、2つの円の合計から全体の面積を引いた「はみ出した重なり分」として計算できます。
- 式: I(X;Y) = H(X) + H(Y) - H(X, Y)
- 計算: 2.0 + 2.0 - 3.5 = 0.5
- つまり、受信データ Yを見ることで、送信データ X について 0.5 bit 分の情報を得られたことになります。
第2問:ノイズのある通信路(条件付きエントロピー)
【問題】
送信者が 0 または 1 を等確率(1/2 ずつ)で送ります。しかし、通信路にノイズがあるため、受信者がデータ Y を受け取っても、送信データ Xにはまだ 0.2bit 分の不確かさが残ってしまいました。この通信によって得られた相互情報量 I(X;Y)を求めなさい。
【解答】
0.8 bit
【解説】
- 送信前の不確かさ(送信エントロピー)は、確率 1/2 なので H(X) = 1.0 bit です。
- 受信した後の不確かさ(条件付きエントロピー)は、H(X|Y) = 0.2 bit です。
- 相互情報量は「もともとの不確かさ」から「知った後に残った不確かさ」を引いたものです。
- 式: I(X;Y) = H(X) - H(X|Y)
- 計算: 1.0 - 0.2 = 0.8 bit
通信の限界:チャンネル容量
少しだけ発展的なお話をしましょう。
私たちが電話やインターネットで情報を送るとき、そこには必ずノイズ(雑音)が混じります。
送信側が送ったメッセージ
これを専門用語でチャンネル容量と呼びます。
シャノンがこの理論を確立したおかげで、今の私たちの快適なネット環境があると言っても過言ではありません!
まとめと今後の学習の指針
今回は、情報の橋渡し役である相互情報量について学びました。
- 相互情報量は、2つの情報の「重なり」や「共通点」を測る。
- 一方を知ることで、もう一方がどれだけ予測しやすくなったかを示す。
- 相関関係よりも広範囲な「つながり」を捉えることができる。
予測のズレを修正せよ!クロスエントロピーでAIを賢くする秘密
ここまで、情報の驚き、平均的な乱雑さ、情報の重なりについて学んできましたね。
最後を締めくくるテーマは、クロスエントロピーです。
あなたは、天気予報で「降水確率 0 % 」と言われたのに、外に出たら土砂降りだった…なんて経験はありませんか?
この「自分の予想」と「現実」のギャップ。
これを数値化して、正解へと導くためのコンパスがクロスエントロピーなのです!
理想と現実の距離を測る:クロスエントロピーとは
クロスエントロピーとは、ある出来事に対して自分が想定している「予測の確率分布」が、実際の「真の確率分布」とどれくらいズレているかを測る指標です。
専門用語では、真の確率を 



数式は少し難しく見えるかもしれませんが、考え方はシンプルです。
「本当の正解(
AIはどうやって学んでいるの?
最近話題のAIや機械学習の多くは、このクロスエントロピーを最小にするように学習しています。
例えば、画像を見て「これは猫だ」と判定するAIを想像してください。
- AIが「これは 80 % の確率で犬だ!」と予測する。
- 現実は「 100 % 猫」である。
- この「犬だと思ったのに猫だった」というギャップ(クロスエントロピー)を計算する。
- その数値が小さくなるように、AIは自分の頭脳(パラメータ)を修正する。
このサイクルを繰り返すことで、AIはどんどん賢くなっていくわけですね!
クロスエントロピーを学ぶメリットとデメリット
この指標が現代のテクノロジーでなぜこれほど愛されているのでしょうか。
具体的なメリット
最大のメリットは、間違いの「度合い」を厳密に数値化できることです。
ただ「当たり」か「外れ」かだけでなく、「惜しい外れ」なのか「とんでもない大外れ」なのかを区別できます。
これにより、効率的で精度の高い学習が可能になります。
知っておくべきデメリット
デメリットとしては、予測した確率
そのため、実際のシステムでは、予測が極端になりすぎないように少しだけ数値を調整するなどの工夫が必要になります。
練習問題
第1問:2値分類(正解が100%の場合)
【問題】
ある画像が「猫」であるか「犬」であるかを判定するAIがあります。
- 真の状態 p: 猫である(猫:1.0、犬:0.0)
- AIの予測 q: 猫である確率 0.8、犬である確率 0.2このときのクロスエントロピーを求めなさい。(log2(0.8) = -0.32、log2(0.2) = -2.32 とします)
【解答】
0.32 bit
【解説】
- 公式は H(p, q) = -(p1 * log2(q1) + p2 * log2(q2)) です。
- p1=1.0、q1=0.8、 p2=0.0、q2=0.2 を代入します。
- -(1.0 * log2(0.8) + 0.0 * log2(0.2))
- -(1.0 * -0.32 + 0) = 0.32 bit
- ポイント: 正解の確率が 0 の項目(犬)は、AIがどんな予測をしても計算から消えます。いかに「正解の項目」に対して高い確率を出せたかが重要になります。
第2問:3値分類(予測が外れた場合)
【問題】
3つのクラス(A, B, C)の分類問題で、正解と予測が以下のようになりました。クロスエントロピーを求めなさい。
- 正解 p: クラスA(A: 1, B: 0, C: 0)
- 予測 q: A: 0.25, B: 0.5, C: 0.25
【解答】
2.0 bit
【解説】
- 正解がクラスAなので、計算対象は p(A) * log2(q(A)) の部分だけになります。
- -(1 * log2(0.25))
- 0.25 は 1/4 なので、log2(1/4) = -2 です。
- -(-2) = 2.0 bit
- 比較: 第1問(0.32 bit)に比べて、正解(A)への予測確率が低いため、ロス(クロスエントロピー)が大きくなっていることがわかります。
まとめとこれからの学習の指針
全5回にわたる情報理論の旅、お疲れ様でした!
エントロピーという概念が、私たちの生活や最新技術の裏側でいかに重要な役割を果たしているか、感じていただけたでしょうか。
今回のポイントを振り返ります。
- クロスエントロピーは、「予測」と「現実」のズレを測るもの。
- 数値が小さいほど、予測が正確であることを意味する。
- 機械学習やAIの学習効率を高めるために欠かせない道具である。
今後の学習の指針
エントロピーの基礎をマスターしたあなたへ、次のおすすめステップを提案します!
- カルバック・ライブラー情報量(KLダイバージェンス):クロスエントロピーと密接に関係する、「情報の距離」そのものを測る概念です。
- 機械学習の実装:Pythonなどのプログラミング言語を使って、実際にクロスエントロピーを使ってAIを訓練させてみましょう。
- 物理学のエントロピー:情報理論のエントロピーは、実は熱力学からヒントを得ています。物理の世界での「乱雑さ」と比較してみると、さらに世界が広がりますよ。

予測のズレを「距離」として測る!KLダイバージェンスの正体
エントロピーの旅を終えたあなたなら、きっとこの「KLダイバージェンス」という言葉も楽しく理解できるはずです。
前回学んだクロスエントロピーは、予測と現実のズレを測るものでしたね。
今回解説するKLダイバージェンス(カルバック・ライブラー情報量)は、そのズレの「純粋な距離」だけを抜き出したものなんです。
「自分の知識が、どれくらいアップデートされるべきか?」
その情報のギャップを測る魔法の物差しについて、詳しく見ていきましょう!
2つの分布の「似てなさ」を測る:KLダイバージェンスとは
KLダイバージェンスとは、ある確率分布
一言で言えば、情報の「格差」ですね。
専門用語では、以下の式で定義されます。

実はこれ、前回のクロスエントロピー 

つまり、「予測のハズレ具合(クロスエントロピー)」から「もともとその事象が持っている避けられない乱雑さ(エントロピー)」を引いた残りの部分です。
この残った部分こそが、あなたの「予測が甘かったせいで生じた余計なコスト」ということになります。
目的地までの「遠回り」に例えてみよう
あなたが目的地
最短ルートで行けば、エントロピー
でも、間違った地図
このとき、間違った地図のせいで「余計に歩かされた距離」が、KLダイバージェンスなのです。
KLダイバージェンスを学ぶメリットとデメリット
この少し複雑な指標を知ることで、どんな力が身につくのでしょうか。
具体的なメリット
KLダイバージェンスの最大のメリットは、2つの情報の「違い」をダイレクトに評価できることです。
AIの世界では、学習データとテストデータがどれくらい似ているかを調べたり、複雑な確率モデルを扱いやすいシンプルなモデルで近似(真似)させたりするときに大活躍します。
「どれくらい正確にコピーできているか」を測る最高のツールなんですね。
知っておくべきデメリット
注意点としては、これが「数学的な意味での距離」とは少し違うという点です。
一般的な距離(例えば A地点から B地点までの長さ)は、行きも帰りも同じですよね。
しかし、KLダイバージェンスは
「誰の視点でズレを測るか」によって結果が変わる、という不思議な性質があるのです。
練習問題
第1問:2択の予測のズレ
【問題】
ある事象の真の確率 $p$ と、予測の確率 $q$ が以下の通りです。D_{KL}(p||q) を求めなさい。
- 真の分布 p: [表: 1/2, 裏: 1/2]
- 予測の分布 q: [表: 1/4, 裏: 3/4](log2(3) = 1.58 とします)
【解答】
約 0.21 bit
【解説】
- 各項の (p * log2(p/q)) を計算します。
- 表の項: 1/2 * log2( (1/2) / (1/4) ) = 1/2 * log2(2) = 1/2 * 1 = 0.5
- 裏の項: 1/2 * log2( (1/2) / (3/4) ) = 1/2 * log2(2/3)
- log2(2/3) = log2(2) - log2(3) = 1 - 1.58 = -0.58
- 裏の項の計算: 1/2 * (-0.58) = -0.29
- 合計: 0.5 + (-0.29) = 0.21 bit
- 予測 q が真の分布 p からズレている分だけ、この値(コスト)が発生します。
第2問:完全に一致する場合
【問題】
真の分布 pと予測の分布 qが、どちらも [A: 0.8, B: 0.2] で完全に一致しています。このときの KLダイバージェンスを求めなさい。
【解答】 0 bit
【解説】
- 各項の p/q を計算すると、すべて 1 になります。
- log2(1) は 0 です。
- したがって、すべての項が 0 になり、合計も 0 です。
- ポイント: KLダイバージェンスは「距離」のような概念(正確には距離の性質をすべては満たしませんが)なので、一致していれば必ず 0 になります。また、決してマイナスになることはありません。
まとめと今後の学習の指針
今回は、情報のズレを純粋に数値化するKLダイバージェンスについて学びました。
- KLダイバージェンスは、2つの確率分布がどれくらい「離れているか」を測る。
- クロスエントロピーから、元のエントロピーを引いたものである。
- 予測の甘さによる「余計な情報量」を浮き彫りにする。
次のステップへの指針
ここまで来れば、情報理論の基礎はもう完璧です!
次のステップとして、以下のキーワードを調べてみるのはいかがでしょうか。
- 変分オートエンコーダ(VAE):KLダイバージェンスをフル活用して、新しい画像を生成するAIの仕組みです。
- ジェンセン・シャノン・ダイバージェンス:KLダイバージェンスの弱点だった「非対称性」を克服した、より使い勝手の良い距離の測り方です。