
AI学習の登竜門!線形回帰と正則化をマスターして予測の達人になる
いよいよ第1章、機械学習の基本中の基本である線形回帰のセクションに入ります。機械学習の学習を進める上で、ここは避けては通れない、いわば基礎体力をつける場所です。
あなたは、過去のデータから未来を予想したいと思ったことはありませんか?「昨日の気温がこうだったから、今日のソフトクリームの売上はこれくらいかな?」といった予測を、数学の力でスマートに解決するのがこの章の主役です。
線形回帰とは何か?
線形回帰とは、ある数値(説明変数)をもとに、別の数値(目的変数)を予測するための手法です。グラフの上に点がいくつか散らばっている様子を想像してみてください。その点の間を一番きれいに通り抜ける「理想の一本線」を引くことが、線形回帰のゴールです。
中学生で習った一次関数の式を覚えていますか?

この 

多重共線性という落とし穴
線形回帰を使いこなす上で、必ず知っておかなければならない専門用語が「多重共線性(マルチコ)」です。
これは、予測に使いたいデータ同士が、お互いに似すぎている状態を指します。
例えば、中古車の価格を予想したいときに、説明変数として「走行距離(キロメートル)」と「走行距離(マイル)」の両方を入れたらどうなるでしょうか?どちらも同じ意味ですよね。
このように、似た情報を同時にモデルに詰め込むと、コンピュータは「どちらの数値を重視すればいいんだ!」と混乱してしまい、計算結果がめちゃくちゃになってしまいます。料理に例えるなら、レシピに「塩」と「食塩」が別々に書かれていて、両方大量に入れてしまうような失敗のことです。
モデルの暴走を抑えるL1・L2正則化
機械学習には「過学習」という恐ろしい現象があります。これは、手元にある練習用データにだけ完璧に合わせようとしすぎて、本番のデータで全く役に立たなくなる状態です。
これを防ぐためのブレーキが「正則化」です。
Lasso回帰(L1正則化)
Lasso(ラッソ)回帰は、不要なデータの影響力をバッサリと 
たくさんの項目の中から、本当に予測に役立つものだけを残すため、データの「断捨離」をしてくれる優秀なクリーナーのような存在です。
Ridge回帰(L2正則化)
Ridge(リッジ)回帰は、すべての項目の影響力をバランスよく、少しずつ小さくする手法です。
特定のデータが大きな顔をして予測を支配しないように、全体をマイルドに調整します。チーム全員の個性を活かしつつ、誰か一人が暴走しないように調整するリーダーのような役割ですね。
線形回帰のメリットとデメリット
ここで、線形回帰の性格を整理しておきましょう。
メリット
- 計算が非常に高速で、大量のデータも扱いやすい。
- 「なぜその予測になったのか」が人間にも理解しやすい(解釈性が高い)。
デメリット
- 複雑なカーブを描くようなデータには対応できない(直線しか引けないため)。
- 外れ値(極端に異常なデータ)に引っ張られやすい。
第1章のまとめと次のステップ
線形回帰は、シンプルでありながら、正則化を組み合わせることで非常に強力な武器になります。
- 直線を引いて予測する。
- 似たデータ同士の衝突(多重共線性)に気をつける。
- 正則化(Lasso・Ridge)でモデルの暴走を抑える。
この3点を理解できれば、あなたはもう予測モデルの基礎をマスターしたも同然です!
第1章で学んだ線形回帰は「家賃」や「売上」といった連続した数値を当てるのが得意でした。しかし、世の中には「合格か不合格か」「このメールは迷惑メールか否か」といった、白黒はっきりつけたい場面がたくさんありますよね。
そんな「分類」の課題を解決してくれるのが、ロジスティック回帰です。
ロジスティック回帰とは?名前の秘密
名前に「回帰」と付いているので少し混乱するかもしれませんが、実はこれ、分類のためのアルゴリズムなんです。
線形回帰が引いた一本の直線は、どこまでも突き進んでしまいます。しかし、確率は 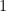


専門用語を高校生レベルで解説!
ロジスティック回帰を支える3つの重要なキーワードを見ていきましょう。
シグモイド関数
これが先ほどお話しした「魔法の関数」の正体です。グラフにすると、アルファベットの「S」のような形をしています。
非常に大きな数値を入れると 
ロジットとオッズ比
「オッズ」という言葉は、競馬などのギャンブルで聞いたことがあるかもしれませんね。
オッズとは「ある事象が起こる確率」と「起こらない確率」の比のことです。
オッズ = 起こる確率 ÷ 起こらない確率
より簡潔に書けば、Odds = p / (1 - p)
このオッズを対数( 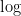
ソフトマックス関数
ロジスティック回帰が「AかBか」の2択なのに対し、3つ以上のグループ(例えば、犬・猫・うさぎ)に分けたいときに登場するのが「ソフトマックス関数」です。
それぞれのグループである確率を出し、その合計がぴったり
メリットとデメリット
ロジスティック回帰の個性を把握しておきましょう。
メリット
- 結果が「確率」で出るため、判断の自信満々度がわかる。
- 計算が軽快で、実務でも非常に多用される。
デメリット
- データが直線(あるいは平面)でスパッと分けられないような、複雑な境界線を持つ場合には太刀打ちできない。
学習の指針
第2章、お疲れ様でした!「確率は
- シグモイド関数で数値を確率に変える。
- オッズやロジットは、計算を楽にするための工夫。
- 3つ以上の分類にはソフトマックス関数を使う。
この流れを理解できれば完璧です!
いよいよ最終章、第3章のサポートベクターマシン(SVM)について解説しますね。
これまで学んだ手法よりも少し「強気」で、境界線の引き方にこだわり抜くアルゴリズムです。複雑なデータが入り混じった状態でも、見事に白黒つけるその実力を見ていきましょう。
サポートベクターマシンとは?
サポートベクターマシンは、日本語で言うなら「境界線から最も近いデータ点(サポートベクター)との距離を最大にするマシン」です。
例えば、机の上に「赤いリンゴ」と「青いリンゴ」が並んでいるとします。その間に仕切りの板を立てるとき、どちらかのリンゴにぶつかりそうなギリギリの場所に立てるよりも、両方からできるだけ離れた真ん中に立てたほうが、後から新しいリンゴが置かれたときも正しく分類できそうですよね。この「余裕(マージン)」を最大化するのがSVMの最大の特徴です。
専門用語を高校生レベルで解説!
SVMを使いこなすための3つの重要な概念を紹介します。
ハードマージンとソフトマージン
データの分け方には、2つのスタンスがあります。
- ハードマージン絶対に1つのミスも許さないスタンスです。すべてのデータを完璧に分類しようとしますが、1つでも変なデータ(外れ値)が混じると、境界線が無理に歪んでしまう弱点があります。
- ソフトマージン「多少のミスはあってもいいから、全体としてきれいに分けよう」という柔軟なスタンスです。現実のデータはノイズが多いので、こちらのほうがよく使われます。
カーネル法
これがSVMの「魔法」です。
例えば、真ん中に赤い玉があり、その周りを青い玉が囲んでいるようなデータがあるとします。これ、直線一本では絶対に分けられませんよね?
そこで「カーネル法」を使います。これは、平面にあるデータを「高い次元(立体)」に放り投げる技術です。すると、今まで重なっていたデータに高さの違いが生まれ、今まで引けなかった「境界の板」をスパッと差し込めるようになります。
メリットとデメリット
メリット
- データの次元(項目の数)が多くても、非常に高い精度で分類できる。
- カーネル法のおかげで、直線で分けられない複雑な形にも対応できる。
デメリット
- 学習データが数十万件を超えるような大規模データになると、計算が非常に重くなる。
- 内部で何が起きているのか(なぜその境界線になったのか)を人間が理解するのが少し難しい。
今後の学習の指針
全3章、本当にお疲れ様でした!線形回帰、ロジスティック回帰、そしてSVM。これらは機械学習の「三種の神器」とも言える重要な技術です。これからの学習をより深めるためのアドバイスを最後に贈ります。
- 理論の次は「実装」へ理論がわかったら、次はPythonなどのプログラミング言語を使って、実際にモデルを動かしてみましょう。
- 評価指標を学ぶ「予測が当たった!」だけでなく、どれくらい正確なのかを測る「正解率」や「適合率」といった指標を学ぶと、さらにE検定合格へ近づきます。
- 数式に慣れる今回は言葉で説明しましたが、少しずつ
(シグマ)や行列を使った数式にも挑戦してみてください。
この3つの章の内容を誰かに説明できるようになれば、あなたの基礎はもう盤石です。自信を持って次のステップへ進んでくださいね!