
【E資格】AIは「確信」で動く?頻度確率・ベイズ確率と「ベイズの定理」
「確率」と聞くと、サイコロやコイン投げの計算を思い浮かべる方が多いと思います。
しかし、AI(特に機械学習)の世界では、確率は単なるギャンブルの計算ではなく、「データの不確実性」を扱ったり、「信念の度合い」を更新したりするための重要な言語なのです。
今回は、E資格の範囲である「確率・統計」の前半部分、特にAIの推論ロジックの基礎となる「条件付き確率」と「ベイズ則」について解説します。
1. 2つの「確率」:頻度とベイズ
まず、確率には大きく分けて2つの捉え方があることを知っておきましょう。
- 頻度確率(客観確率):「10本のうち1本が当たりのクジを引くとき、当たる確率は10%」というように、実際に発生した頻度に基づく考え方です 。
- ベイズ確率(主観確率):「今の症状から見て、インフルエンザである確率は40%くらいだろう」というように、その時点での情報に基づく信念の度合いを表す考え方です。
AI、特に「ベイズ統計」を用いる分野では、新しいデータ(証拠)を得るたびに、この「信念(確率)」を更新していくアプローチが非常に重要になります。
2. 条件付き確率と独立性
条件付き確率
ある事象 

例えば、「雨が降っている(条件)」ときに「交通事故に遭う」確率のようなものです。
数式では縦棒(バー)を使って次のように書きます。

これは、「 

独立な事象
もし、お互いの発生に因果関係がない(独立している)場合、同時確率は単純な掛け算になります。

ご提案いただいた通り、より実用的でイメージしやすい「スパムメール」と「コロナ検査(医療検査)」の2つの例に変更して、解説とコードを作成しました。
ベイズの定理の面白さである「直感と異なる結果(偽陽性のパラドックスなど)」がよく分かる内容になっています。
3. 逆転の発想!「ベイズ則」
ここが今回のハイライトです。
条件付き確率の定義を変形すると、「結果から原因を推測する」ための強力な公式、ベイズ則(ベイズの定理)が導かれます。

この公式が現代社会でどのように使われているのか、2つの代表的な例で見てみましょう。
例題1:そのメールは「スパム」か?
AIによる迷惑メールフィルターの仕組みです。「怪しい単語」が含まれているという結果から、そのメールがスパムであるという原因(確率)を推測します。
状況設定(仮定):
- 全受信メールのうち、20% がスパムメールです。 P(スパム)
- スパムメールには、80% の確率で「無料」という単語が含まれます。 P(無料|スパム)
- 普通のメールにも、5% の確率で「無料」という単語が含まれてしまいます。 P(無料|普通)



問題: 「無料」という単語が含まれているメールが届きました。これがスパムである確率は?
解き方:
- まず、「無料」という単語が含まれる全体の確率を計算します。 (スパムで「無料」がある場合 + 普通で「無料」がある場合) P(無料)
- このうち、スパムが原因である割合を求めます。 P(スパム|無料)


答え:80% 単にスパムである確率(20%)よりも、「無料」という証拠があることで確信度が大幅に上がりました。
例題2:陽性判定の真実(医療検査のパラドックス)
こちらは直感と計算結果が大きくズレやすい、非常に重要な例です。
状況設定(仮定):
- あるウイルスの感染者は、人口の 0.1% です。 P(感染)
- 検査の精度は高く、感染している人が受けると 99% 陽性になります。 P(陽性|感染)
- 感染していない人が受けても、1% の確率で誤って陽性が出てしまいます(偽陽性)。 P(陽性|未感染)



問題: 検査を受けたら「陽性」でした。本当に感染している確率は?
解き方:
- 陽性が出る全体の確率を計算します。 (本当に感染して陽性 + 未感染で誤って陽性) P(陽性)
- このうち、本当に感染している割合を求めます。 P(感染|陽性)


答え:約9% 驚くべきことに、99%精度の検査で陽性が出ても、実際に感染している確率は10%以下なのです。 これは元の感染者数(0.1%)が非常に少ないため、「誤って陽性になった健康な人」の人数の方が、「正しく陽性になった感染者」よりも多くなってしまうために起こります。 ベイズ則は、こうした「直感の罠」を見抜くためにも役立ちます。
4. Pythonでベイズ推定を実装しよう
では、これら2つのケースをPythonで計算してみましょう。
汎用的な関数を作っておけば、どんな状況でも確率を計算できます。
def bayes_theorem(p_a, p_b_given_a, p_b_given_not_a):
"""
ベイズの定理を用いて P(A|B) を計算する関数
Parameters:
p_a : P(A) - 事象A(原因)の事前確率
p_b_given_a : P(B|A) - 原因Aがある時に結果Bが起きる確率
p_b_given_not_a : P(B|Not A) - 原因Aがない時に結果Bが起きてしまう確率
"""
# 原因Aではない確率 P(Not A)
p_not_a = 1 - p_a
# 全体で結果Bが起きる確率 P(B)
# P(B) = P(B|A)*P(A) + P(B|Not A)*P(Not A)
p_b = (p_b_given_a * p_a) + (p_b_given_not_a * p_not_a)
# 事後確率 P(A|B)
p_a_given_b = (p_b_given_a * p_a) / p_b
return p_a_given_b
# --- ケース1:スパムメール判定 ---
# P(スパム) = 0.2
# P(無料|スパム) = 0.8
# P(無料|普通) = 0.05
prob_spam = bayes_theorem(0.2, 0.8, 0.05)
print(f"【スパム判定】「無料」と書かれたメールがスパムである確率: {prob_spam:.1%}")
# --- ケース2:感染症検査 ---
# P(感染) = 0.001 (0.1%)
# P(陽性|感染) = 0.99
# P(陽性|未感染) = 0.01 (偽陽性率)
prob_infected = bayes_theorem(0.001, 0.99, 0.01)
print(f"【医療検査】陽性判定が出て、本当に感染している確率: {prob_infected:.1%}")図解で解説

左のグラフ(スパム判定):
- 緑色の部分(分子)が大きく、赤色の部分(ノイズ)が小さいです。
- 「無料」という単語が含まれているメール全体(棒の高さ)のうち、大部分が本当にスパム(緑)であることがわかります。だから確率は80%と高くなります。
右のグラフ(医療検査):
- 赤色の部分(偽陽性)が非常に大きく、緑色の部分(真陽性・分子)がごくわずかです。
- これは、元々の感染者($P(A)=0.001$)が圧倒的に少ないため、わずか1%の誤診($P(B|\text{Not }A)=0.01$)であっても、健康な人の誤診の絶対数の方が多くなってしまうことを示しています。
- 結果として、「陽性」という結果が出ても、その中身のほとんどは間違い(赤色)であるため、確率は9%と低くなります。
実行結果の解説
このコードを実行すると、以下の結果が得られます。
- スパム判定:80.0%
- 医療検査:9.0%
Pythonを使うことで、例えば「もし検査の誤診率が0.1%まで下がったら、確率はどう変わるか?」といったシミュレーションも一瞬で行えるようになります。
今後の学習の指針
今回は、確率の基礎と、AIの推論エンジンの核となる「ベイズ則」について学びました。
- 条件付き確率: ある条件下での確率。
- ベイズ則: 結果から原因の確率を逆算する魔法の杖。
次回は、確率・統計の後半戦、「統計的指標」と「確率分布」について解説します。
「期待値」「分散」といったデータの形を表す言葉や、「ガウス分布(正規分布)」などのAIモデルで必ず登場する分布の形について、図解イメージとともに攻略していきましょう。
【第2回】データの「形」と「中心」を知る!期待値・分散と確率分布
前回は「確率の考え方」として、ベイズ則を使って結果から原因を推論する方法を学びました。
今回は、E資格の確率・統計分野の後半戦、「統計的指標」と「確率分布」について解説します。
AIエンジニアにとって、データは単なる数字の羅列ではありません。
「このデータは平均的にどのあたりにあるのか?(期待値)」
「どれくらいバラついているのか?(分散)」
「どんな形をしているのか?(確率分布)」
これらを把握することが、データを正しく扱い、モデルを設計するための第一歩となります。
今回は、これらの重要な概念を、数式とPythonコードを交えて直感的に理解していきましょう。
1. 確率変数と確率分布
まず、統計学の主役となる言葉の定義をおさらいします。
- 確率変数(Random Variable):サイコロの出目のように、確率によって値が決まる変数のことです。事象そのものを指すこともあります 。
- 確率分布(Probability Distribution):その確率変数が、どの値をどれくらいの確率でとるかを表したものです。離散値であれば表に、連続値であればグラフ(関数)で示されます 。
2. データを要約する指標:期待値と分散
データの「特徴」を一言で表すために、以下の指標が使われます。
期待値(Expected Value)
その分布において、確率変数がとる「平均的な値」や「ありえそうな値」のことです。記号では 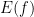
計算はシンプルで、「値 

分散(Variance)
データの「散らばり具合」を表す指標です。
それぞれのデータが、期待値(平均)からどれくらい離れているかを2乗して、その平均をとったものです 。
![Var(f) = E[(f - E(f))^2]](https://s0.wp.com/latex.php?latex=Var%28f%29+%3D+E%5B%28f+-+E%28f%29%29%5E2%5D&bg=ffffff&fg=000&s=0&c=20201002)
標準偏差(Standard Deviation)
分散は計算の過程で値を2乗しているため、元のデータと単位が異なります(例:身長cmに対して分散は 
そこで、分散の平方根(ルート)をとって元の単位に戻したのが標準偏差( 

共分散(Covariance)
2つのデータ系列(例えば身長と体重)があるとき、それらの「傾向の違い」や「関係性」を表す指標です 。
- 正の値:似た傾向(片方が増えるともう片方も増える)
- 負の値:逆の傾向(片方が増えるともう片方は減る)
- ゼロ:関係性に乏しい
3. AIで頻出する「確率分布」
データの「形」には名前がついています。AIモデルを作る際は、扱うデータの性質に合わせて適切な分布を選びます。
① ベルヌーイ分布
- イメージ: コイントス 。
- 特徴: 「成功か失敗か」「裏か表か」のように、結果が2つしかない場合に使われます。裏と表が出る確率が等しくなくても扱えます 。
② マルチヌーイ(カテゴリカル)分布
- イメージ: サイコロ 。
- 特徴: 結果が3つ以上ある場合(例:1〜6の目)に使われます 。
③ 二項分布
- イメージ: コインを何回も投げる。
- 特徴: ベルヌーイ試行(コイントスなど)を
回繰り返したときに、成功する回数の分布です 。
④ ガウス分布(正規分布)
- イメージ: 釣鐘型のなだらかな山

- 特徴: 連続的な値をとる分布で、自然界や統計学で最も重要です。平均値
と分散
という2つのパラメータで形が決まります 。
Pythonで「分布」を可視化しよう
それでは、Pythonを使ってガウス分布(正規分布)を描画し、期待値や標準偏差がグラフのどこに対応するかを確認してみましょう。
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import norm
# パラメータ設定
mu = 0 # 期待値(平均):山の中心
sigma = 1 # 標準偏差:山の広がり具合
x = np.linspace(-4, 4, 100)
# ガウス分布の確率密度関数 (PDF) を計算
y = norm.pdf(x, mu, sigma)
# グラフ描画
plt.figure(figsize=(8, 5))
plt.plot(x, y, label=f'Gaussian (mean={mu}, std={sigma})', color='blue')
plt.fill_between(x, y, alpha=0.1, color='blue')
# 期待値と標準偏差の場所を図示
plt.axvline(x=mu, color='red', linestyle='--', label='Expected Value (Mean)')
plt.axvline(x=mu + sigma, color='green', linestyle=':', label='Mean + 1 Std Dev')
plt.axvline(x=mu - sigma, color='green', linestyle=':', label='Mean - 1 Std Dev')
plt.title('Gaussian Distribution Visualization')
plt.xlabel('x')
plt.ylabel('Probability Density')
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()このコードを実行すると、平均 
今後の学習の指針
今回は、統計の基礎指標と確率分布について学びました。
- 期待値と分散: データの特徴を数値化する基本ツール。
- 主要な確率分布: ベルヌーイ(2択)、マルチヌーイ(多択)、ガウス(連続)などをデータの性質に合わせて使い分ける。