
以下の問題の記述形式です。
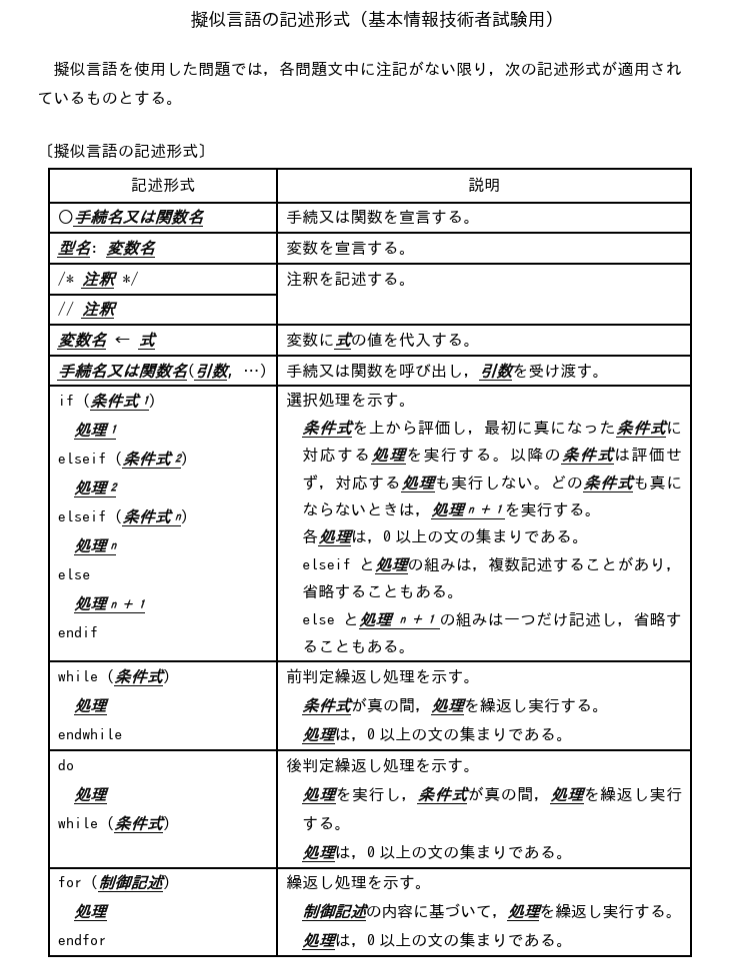

基本情報技術者試験(科目B)の「擬似言語」の形式に基づいた、初学者向けの練習問題です。
上記資料にある記述ルール(配列の添字は1から始まるなど)に準拠し、それぞれの解答、解説、そしてJavaで書いた場合のコードを併記します。
解答解説はアコーディオン形式でクリックにより展開できます。
1. 初級
第1問:変数の演算と代入
【問題】
次のプログラムを実行したとき、出力される ans の値はいくつか。
整数型: a ← 5
整数型: b ← 3
整数型: ans ← a × b + a
ans を出力
【解答】
20
【解説】
基本的な変数の代入と演算の問題です。
aに 5、bに 3 が代入されます。a × bは5 × 3 = 15です。- それに
a(つまり 5) を足すので、15 + 5 = 20となります。 - 結果として
ansに 20 が代入され、出力されます。
【Javaコード】
public class Main {
public static void main(String[] args) {
int a = 5;
int b = 3;
int ans = a * b + a;
System.out.println(ans);
}
}第2問:条件分岐(if文)
【問題】
次のプログラムを実行したとき、出力される文字列は何か。
整数型: score ← 75
文字列型: result ← "不合格"
if (score ≥ 80)
result ← "優"
elseif (score ≥ 60)
result ← "良"
else
result ← "不可"
endif
result を出力【解答】
良
【解説】
条件分岐(if-elseif-else)の流れを追う問題です 1。
- 最初の条件
score ≥ 80(75は80以上か?)は False なので、次のelseifに進みます。 - 次の条件
score ≥ 60(75は60以上か?)は True です。 - 対応する処理
result ← "良"が実行されます。 - 条件が成立したため、以降の
elseは無視され、endifに抜けます。
【Javaコード】
public class Main {
public static void main(String[] args) {
int score = 75;
String result = "不合格";
if (score >= 80) {
result = "優";
} else if (score >= 60) {
result = "良";
} else {
result = "不可";
}
System.out.println(result);
}
}第3問:繰り返し処理(while文)
【問題】
次のプログラムを実行したとき、出力される count の値はいくつか。
整数型: i ← 1
整数型: count ← 0
while (i ≤ 10)
count ← count + i
i ← i + 3
endwhile
count を出力【解答】
22
【解説】
while ループによる繰り返し加算です 2。
- 1回目:
i=1 (条件:真)。count= 0+1 = 1。iは 1+3 = 4 になります。 - 2回目:
i=4 (条件:真)。count= 1+4 = 5。iは 4+3 = 7 になります。 - 3回目:
i=7 (条件:真)。count= 5+7 = 12。iは 7+3 = 10 になります。 - 4回目:
i=10 (条件:真)。count= 12+10 = 22。iは 10+3 = 13 になります。 - 5回目:
i=13 (条件:偽)。ループを終了します。
【Javaコード】
public class Main {
public static void main(String[] args) {
int i = 1;
int count = 0;
while (i <= 10) {
count = count + i;
i = i + 3;
}
System.out.println(count);
}
}第4問:配列とfor文(重要:添字の違い)
【問題】
次のプログラムを実行したとき、出力される total の値はいくつか。
※試験の仕様に基づき、配列の要素番号は1から始まるものとする。
整数型の配列: nums ← {10, 20, 30, 40, 50}
整数型: total ← 0
整数型: k
for (k を 1 から 3 まで 1 ずつ増やす)
total ← total + nums[k]
endfor
total を出力注意点:
科目Bの擬似言語では配列の添字(インデックス)が 1 から始まりますが、Javaでは 0 から始まります。Javaコードに変換する際は添字をずらす必要があります。
【解答】
60
【解説】
配列の先頭から3つの要素を足し合わせる処理です。
k=1 のとき、nums[1]は 10。total= 0 + 10 = 10。k=2 のとき、nums[2]は 20。total= 10 + 20 = 30。- k=3 のとき、nums[3] は 30。total = 30 + 30 = 60。ループ終了。
【Javaコード】
public class Main {
public static void main(String[] args) {
int[] nums = {10, 20, 30, 40, 50};
int total = 0;
// Javaの配列は0番目から始まるため、
// 擬似言語の「1から3まで」は「0から2まで」に対応します。
for (int k = 0; k < 3; k++) {
total = total + nums[k];
}
System.out.println(total);
}
}第5問:合計と平均を算出する
【問題】
次のプログラムを実行したとき、出力される average の値はいくつか。
※除算の結果は小数を含む数値として扱う。
整数型の配列: scores ← {70, 80, 90, 60, 100}
整数型: total ← 0
実数型: average
整数型: i
for (i を 1 から 5 まで 1 ずつ増やす)
total ← total + scores[i]
endfor
average ← total / 5
average を出力【解答】
80
【解説】
このアルゴリズムは、まず5つの試験点数の合計を求め、それを人数で割ることで平均を出しています。
出力: 計算された 80 が average として出力されます。
合計の算出(for文の中身): i=1: total = 0 + 70 = 70 i=2: total = 70 + 80 = 150 i=3: total = 150 + 90 = 240 i=4: total = 240 + 60 = 300 i=5: total = 300 + 100 = 400
平均の算出: 繰り返しが終了した後、total は 400 となっています。 これを要素数の 5 で割ります。 400 / 5 = 80
【Javaコード】
public class Main {
public static void main(String[] args) {
int[] scores = {70, 80, 90, 60, 100};
int total = 0;
for (int i = 0; i < scores.length; i++) {
total = total + scores[i];
}
// 合計を実数(double)にキャストしてから割ることで、正確な平均を得られます
double average = (double) total / scores.length;
System.out.println(average);
}
}第6問:最大値探索
【問題】
次のプログラムを実行したとき、出力される max_value の値はいくつか。
整数型の配列: data ← {15, 42, 7, 31, 24}
整数型: max_value
整数型: i
max_value ← data[1]
for (i を 2 から 5 まで 1 ずつ増やす)
if (data[i] > max_value)
max_value ← data[i]
endif
endfor
max_value を出力【解答】
42
【解説】
このプログラムは、最初に1番目の要素を「暫定の最大値」として保持し、残りの要素と比較していく手順をとっています。
- 初期化:max_value に data[1] の値である 15 を代入します。
- i=2のとき:data[2] は 42 です。 42 > 15 は真(true)なので、max_value を 42 に更新します。
- i=3のとき:data[3] は 7 です。 7 > 42 は偽(false)なので、max_value は 42 のままです。
- i=4のとき:data[4] は 31 です。 31 > 42 は偽なので、max_value は 42 のままです。
- i=5のとき:data[5] は 24 です。 24 > 42 は偽なので、max_value は 42 のままです。
繰り返しが終了したとき、max_value に保持されている値は 42 となります。
【Javaコード】
public class Main {
public static void main(String[] args) {
int[] data = {15, 42, 7, 31, 24};
// 最初の要素を暫定最大値とする
int maxValue = data[0];
// 2番目の要素(インデックス1)から順に比較する
for (int i = 1; i < data.length; i++) {
if (data[i] > maxValue) {
maxValue = data[i];
}
}
System.out.println(maxValue);
}
}第7問:FizzBuzz問題
【問題】
次のプログラムを実行したとき、最後に出力される内容は?
整数型: i
for (i を 1 から 15 まで 1 ずつ増やす)
if (i mod 15 = 0)
'FizzBuzz' を出力
elseif (i mod 3 = 0)
'Fizz' を出力
elseif (i mod 5 = 0)
'Buzz' を出力
else
i を出力
endif
endfor【解答】
FizzBuzz
【解説】
このアルゴリズムで最も重要なのは、最初の if (i mod 15 = 0) です。
- 判定の順序: もし最初に
i mod 3 = 0を判定してしまうと、15のときでも「Fizz」と出力されてしまい、それ以降のelseifが実行されなくなります。そのため、最も条件が厳しい(範囲が狭い)「15の倍数」から先に判定する必要があります。 - 15のときの挙動: iが15に達したとき、
15 mod 15は 0 なので、最初の条件が真(true)となり、「FizzBuzz」が出力されてその回のループの判定は終了します。
したがって、最後(i=15)の出力は「FizzBuzz」となります。
【Javaコード】
public class Main {
public static void main(String[] args) {
for (int i = 1; i <= 15; i++) {
if (i % 15 == 0) {
System.out.println("FizzBuzz");
} else if (i % 3 == 0) {
System.out.println("Fizz");
} else if (i % 5 == 0) {
System.out.println("Buzz");
} else {
System.out.println(i);
}
}
}
}第8問:関数の呼び出しと論理演算
【問題】
次のプログラム中の関数 checkValue(15) を呼び出したとき、戻り値として返される文字列は何か。
※演算子 mod は剰余(割り算の余り)を表す。
○文字列型: checkValue(整数型: n)
if ((n mod 3 = 0) and (n mod 5 = 0))
return "A"
elseif (n mod 3 = 0)
return "B"
else
return "C"
endif【解答】
"A"
【解説】
FizzBuzz問題のような論理演算です。引数 n は 15 です。
- 最初の条件
(n mod 3 = 0) and (n mod 5 = 0)を評価します。 15 mod 3は 0(割り切れる)。15 mod 5は 0(割り切れる)。- 両方とも成立(True)しているため、
and条件全体が真となり、return "A"が実行されます。
【Javaコード】
public class Main {
public static void main(String[] args) {
System.out.println(checkValue(15));
}
public static String checkValue(int n) {
// Javaでは「mod」の代わりに「%」、「and」の代わりに「&&」を使います
if ((n % 3 == 0) && (n % 5 == 0)) {
return "A";
} else if (n % 3 == 0) {
return "B";
} else {
return "C";
}
}
}
第9問:配列の要素の入れ替え
【問題】
次のプログラムを実行したとき、出力される配列 data の内容はどれか。
※ div は整数の割り算の商(小数点以下切り捨て)を表すものとする。
整数型の配列: data ← {1, 2, 3, 4, 5}
整数型: n ← dataの要素数
整数型: i, temp
for (i を 1 から (n ÷ 2) の商 まで 1 ずつ増やす)
/* 値の入れ替え */
temp ← data[i]
data[i] ← data[n - i + 1]
data[n - i + 1] ← temp
endfor
data の全要素を出力
【解答】
{5, 4, 3, 2, 1}
【解説】
配列の順序を逆転(リバース)させるアルゴリズムです。
nは 5 なので、ループは1から2(5÷2の商) まで実行されます。
- i = 1 のとき:
data[1](1) とdata[5 - 1 + 1]つまりdata[5](5) を交換します。- 配列は
{5, 2, 3, 4, 1}になります。
- 配列は
- i = 2 のとき:
data[2](2) とdata[5 - 2 + 1]つまりdata[4](4) を交換します。- 配列は
{5, 4, 3, 2, 1}になります。
- 配列は
- ループ終了。真ん中の
3は触られませんが、結果として配列全体が逆順になります。
【Javaコード】
import java.util.Arrays;
public class Main {
public static void main(String[] args) {
int[] data = {1, 2, 3, 4, 5};
int n = data.length;
int temp;
// Javaの添字は0〜(n-1)。
// 擬似言語の「iを1から n/2」は、Javaでは「iを0から n/2 - 1」まで等の調整が必要ですが、
// ここではロジックを分かりやすくJava風に書き直します。
// 左端(i)と右端(n-1-i)を交換します。
for (int i = 0; i < n / 2; i++) {
temp = data[i];
data[i] = data[n - 1 - i];
data[n - 1 - i] = temp;
}
System.out.println(Arrays.toString(data));
}
}第10問:配列の操作(シフト処理)
【問題】
次のプログラムを実行したとき、出力される配列 arr の内容はどれか。
整数型の配列: arr ← {1, 2, 3, 4, 5}
整数型: temp
整数型: i
temp ← arr[1]
for (i を 1 から arrの要素数 - 1 まで 1 ずつ増やす)
arr[i] ← arr[i + 1]
endfor
arr[arrの要素数] ← temp
arr を出力【解答】
{2, 3, 4, 5, 1}
【解説】
配列の要素を「左に1つ回転シフト」させる処理です。
- 先頭の
arr[1](値は1) をtempに退避します。 - ループ処理で、
i=1から4まで実行します。arr[1] ← arr[2](2が入る)arr[2] ← arr[3](3が入る)arr[3] ← arr[4](4が入る)arr[4] ← arr[5](5が入る)
- 最後に、末尾 arr[5] に退避しておいた temp (1) を入れます。結果、{2, 3, 4, 5, 1} となります。
【Javaコード】
import java.util.Arrays;
public class Main {
public static void main(String[] args) {
int[] arr = {1, 2, 3, 4, 5};
int temp = arr[0]; // 先頭を退避
for (int i = 0; i < arr.length - 1; i++) {
arr[i] = arr[i + 1];
}
arr[arr.length - 1] = temp; // 末尾に代入
System.out.println(Arrays.toString(arr));
}
}第11問:ネストされたループ(二重ループ)
【問題】
次のプログラムを実行したとき、出力される count の値はいくつか。
整数型: count ← 0
整数型: i, j
for (i を 1 から 3 まで 1 ずつ増やす)
for (j を 1 から i まで 1 ずつ増やす)
count ← count + 1
endfor
endfor
count を出力
【解答】
6
【解説】
内側のループの回数が、外側の変数 i に依存して変化します。
- i = 1 のとき: 内側のループ
jは 1 から 1 まで(1回)。count= 1。 - i = 2 のとき: 内側のループ
jは 1 から 2 まで(2回)。count= 1 + 2 = 3。 - i = 3 のとき: 内側のループ j は 1 から 3 まで(3回)。count = 3 + 3 = 6。合計でループが6回回るため、答えは6です。
【Javaコード】
public class Main {
public static void main(String[] args) {
int count = 0;
for (int i = 1; i <= 3; i++) {
for (int j = 1; j <= i; j++) {
count = count + 1;
}
}
System.out.println(count);
}
}第12問:2次元配列のアクセス
【問題】
次のプログラムを実行したとき、出力される sum の値はいくつか。
※{{...}, {...}} は2次元配列を表し、mat[行][列] でアクセスする。
整数型の配列: mat ← {{1, 2, 3},
{4, 5, 6},
{7, 8, 9}}
整数型: sum ← 0
整数型: i
for (i を 1 から 3 まで 1 ずつ増やす)
sum ← sum + mat[i][i]
endfor
sum を出力
【解答】
15
【解説】
正方形の行列(3x3)の対角線上の要素を足し合わせる処理です。
i=1:mat[1][1]は 1。sum= 0 + 1 = 1。i=2:mat[2][2]は 5。sum= 1 + 5 = 6。- i=3: mat[3][3] は 9。sum = 6 + 9 = 15。結果、15が出力されます。
【Javaコード】
public class Main {
public static void main(String[] args) {
int[][] mat = {{1, 2, 3}, {4, 5, 6}, {7, 8, 9}};
int sum = 0;
// Javaは0始まりなので、mat[i][i]でアクセスするために0から2まで回す
for (int i = 0; i < 3; i++) {
sum = sum + mat[i][i];
}
System.out.println(sum);
}
}第13問:2つの最小値の探索
【問題】
次のプログラムは、各文字の出現頻度を記録した配列から、最も頻度の低い2つの要素を組み合わせて新しい節(親ノード)を作る過程の一部である。
実行後、変数 min1_val と min2_val の値はいくつか。
<参考>
※上記アルゴリズムのうちの最も頻度の低い2つの要素を選択する部分に当たります
整数型の配列: freq ← {10, 2, 8, 5, 15}
整数型: min1_val ← 100 // 暫定最小値1
整数型: min2_val ← 100 // 暫定最小値2
整数型: i
for (i を 1 から 5 まで 1 ずつ増やす)
if (freq[i] < min1_val)
min2_val ← min1_val
min1_val ← freq[i]
elseif (freq[i] < min2_val)
min2_val ← freq[i]
endif
endfor
min1_val と min2_val を出力【解答】
min1_val = 2, min2_val = 5
【解説】このプログラムは、配列の中から「一番小さい値」と「二番目に小さい値」を効率よく探すアルゴリズムです。
- i=1: freq[1]は10。min1_val(100)より小さいため、min2=100, min1=10 となります。
- i=2: freq[2]は2。min1(10)より小さいため、min2=10, min1=2 となります。
- i=3: freq[3]は8。min1(2)より大きく、min2(10)より小さいため、min2=8 となります。
- i=4: freq[4]は5。min1(2)より大きく、min2(8)より小さいため、min2=5 となります。
- i=5: freq[5]は15。どちらよりも大きいため、変化しません。
最終的に、最も頻度の低い2つの値である「2」と「5」が抽出されました。ハフマン法では、この2つを合体させて「7」という頻度を持つ新しい節を作り、木を成長させていきます。
【Javaコード】
public class Main {
public static void main(String[] args) {
int[] freq = {10, 2, 8, 5, 15};
int min1 = Integer.MAX_VALUE;
int min2 = Integer.MAX_VALUE;
for (int f : freq) {
if (f < min1) {
min2 = min1;
min1 = f;
} else if (f < min2) {
min2 = f;
}
}
System.out.println("最小1: " + min1 + ", 最小2: " + min2);
}
}2. 中級
第14問:バブルソート(隣接交換法)の一部
【問題】
次のプログラムは、配列を昇順に整列するバブルソートである。
外側のループ(変数 i)が 1回終了した時点 で、配列 nums の内容はどのように変化しているか。
<参考>
整数型の配列: nums ← {4, 2, 5, 1, 3}
整数型: i, j, temp
/* 末尾から先頭に向かって順に比較・交換を行う */
for (i を 1 から numsの要素数 - 1 まで 1 ずつ増やす)
for (j を numsの要素数 から i + 1 まで 1 ずつ減らす)
if (nums[j] < nums[j - 1])
/* 交換処理 */
temp ← nums[j]
nums[j] ← nums[j - 1]
nums[j - 1] ← temp
endif
endfor
endfor
nums を出力【解答】
{1, 4, 2, 5, 3}
【解説】
バブルソートのこの実装は、後ろから前へ向かって小さい値を「泡のように」浮かび上がらせる方式です。
- i = 1 のループ(先頭 nums[1] を確定させるパス)
- j = 5: nums[5] (3) と nums[4] (1) を比較。3 > 1 なので交換しない。
- j = 4: nums[4] (1) と nums[3] (5) を比較。1 < 5 なので交換。配列は
{4, 2, 1, 5, 3}。 - j = 3: nums[3] (1) と nums[2] (2) を比較。1 < 2 なので交換。配列は
{4, 1, 2, 5, 3}。 - j = 2: nums[2] (1) と nums[1] (4) を比較。1 < 4 なので交換。配列は
{1, 4, 2, 5, 3}。
- 結果
- 最も小さい値 1 が先頭に移動し、残りの並びは交換過程の結果に従います。
【Javaコード】
import java.util.Arrays;
public class Main {
public static void main(String[] args) {
int[] nums = {4, 2, 5, 1, 3};
// 外側のループ1回分 (i=0に対応)
for (int j = nums.length - 1; j > 0; j--) {
if (nums[j] < nums[j - 1]) {
int temp = nums[j];
nums[j] = nums[j - 1];
nums[j - 1] = temp;
}
}
System.out.println(Arrays.toString(nums));
}
}第15問:選択ソート(アルゴリズムの穴埋め)
【問題】
次のプログラムは、配列 data を昇順に並べ替える(ソートする)ものである。
プログラムを実行して正しくソートするために、 [ 空欄 ] に入れるべき適切な式はどれか。
<参考>
整数型の配列: data ← {4, 3, 1, 5, 2}
整数型: i, j, minIndex, temp
for (i を 1 から dataの要素数 - 1 まで 1 ずつ増やす)
minIndex ← i
/* 未ソート部分から最小値の位置を探す */
for (j を i + 1 から dataの要素数 まで 1 ずつ増やす)
if ( [ 空欄 ] )
minIndex ← j
endif
endfor
/* 値の交換 */
temp ← data[i]
data[i] ← data[minIndex]
data[minIndex] ← temp
endfor【解答】
data[j] < data[minIndex]
【解説】
選択ソート(Selection Sort)のアルゴリズムです。
- 外側のループ
iは、ソート済み位置の境界を決めます。 - 内側のループ
jで、i以降の範囲(未ソート部分)から「最小値」を探します。 - 現在の暫定的な最小値
data[minIndex]よりも、さらに小さい値data[j]が見つかった場合、minIndexをjに更新する必要があります。 - したがって、条件式は「新しい値の方が小さいか?」を問う
data[j] < data[minIndex]となります。
【Javaコード】
import java.util.Arrays;
public class Main {
public static void main(String[] args) {
int[] data = {4, 3, 1, 5, 2};
int minIndex, temp;
for (int i = 0; i < data.length - 1; i++) {
minIndex = i;
for (int j = i + 1; j < data.length; j++) {
// Javaは0始まりですがロジックは同じ
if (data[j] < data[minIndex]) {
minIndex = j;
}
}
// 交換
temp = data[i];
data[i] = data[minIndex];
data[minIndex] = temp;
}
System.out.println(Arrays.toString(data));
}
}第16問:挿入ソート
【問題】
次のプログラムは、配列を昇順に整列する挿入ソートの途中経過である。
変数 i が 3 のときのループ処理が終了した直後、配列 cards の内容はどれか。
<参考>
整数型の配列: cards ← {10, 5, 8, 3, 6}
整数型: i, j, temp
/* 2番目の要素から順に、適切な位置に挿入していく */
for (i を 2 から cardsの要素数 まで 1 ずつ増やす)
temp ← cards[i]
j ← i - 1
while (j ≥ 1 and cards[j] > temp)
cards[j + 1] ← cards[j]
j ← j - 1
endwhile
cards[j + 1] ← temp
endfor【解答】
{5, 8, 10, 3, 6}
【解説】
挿入ソートは、左側の「整列済み部分」に対して、新しい要素を適切な場所に差し込むアルゴリズムです。
- i = 2 のとき(値 5 の処理):
- 10 と 5 を比較し、5 を先頭に挿入。
- 配列は
{5, 10, 8, 3, 6}となる。
- i = 3 のとき(値 8 の処理):
- 整列済み部分
{5, 10}に対して、8 を適切な場所に挿入します。 - 10 > 8 なので、10 を右にずらす。
- 5 < 8 なので、5 の後ろ(10があった場所)に 8 を入れる。
- 配列は
{5, 8, 10, 3, 6}となる。 - ※後ろの
3, 6はまだ手付かずです。
- 整列済み部分
【Javaコード】
import java.util.Arrays;
public class Main {
public static void main(String[] args) {
int[] cards = {10, 5, 8, 3, 6};
// Javaでは i=1 が擬似言語の i=2 に相当
for (int i = 1; i <= 2; i++) { // i=2(3番目の要素)まで実行
int temp = cards[i];
int j = i - 1;
while (j >= 0 && cards[j] > temp) {
cards[j + 1] = cards[j];
j--;
}
cards[j + 1] = temp;
}
System.out.println(Arrays.toString(cards));
}
}第17問:2分探索(バイナリサーチ)
【問題】
次のプログラムは、昇順に整列された配列 data から、引数 target と等しい値を持つ要素を探し、その添字を返す関数 binarySearch である。
binarySearch({10, 20, 30, 40, 50, 60, 70}, 20) を呼び出したとき、変数 middle に代入される値の変化として正しいものはどれか。
※ ÷ は小数点以下を切り捨てる除算とする。
<参考>
○整数型: binarySearch(整数型の配列: data, 整数型: target)
整数型: low ← 1
整数型: high ← dataの要素数
整数型: middle
while (low ≤ high)
middle ← (low + high) ÷ 2
if (data[middle] = target)
return middle
elseif (data[middle] < target)
low ← middle + 1
else
high ← middle - 1
endif
endwhile
return -1
【解答】
4 → 2
【解説】
探索範囲を半分に絞り込んでいく過程をトレースします。
- 初期状態:
low = 1,high = 7
- 1回目のループ:
middle←(1 + 7) ÷ 2= 4data[4]は40。40 > 20(target) なので、else節へ。high←4 - 1= 3。
- 2回目のループ:
low = 1,high = 3middle←(1 + 3) ÷ 2= 2data[2]は20。- 20 = 20 (target) なので、return middle (2) で終了。よって、middle の値は 4 → 2 と変化します。
【Javaコード】
public class Main {
public static void main(String[] args) {
int[] data = {10, 20, 30, 40, 50, 60, 70};
System.out.println(binarySearch(data, 20));
}
public static int binarySearch(int[] data, int target) {
int low = 0; // Javaは0始まり
int high = data.length - 1;
int middle;
while (low <= high) {
middle = (low + high) / 2;
System.out.println("middle: " + middle); // 変化を確認
if (data[middle] == target) {
return middle;
} else if (data[middle] < target) {
low = middle + 1;
} else {
high = middle - 1;
}
}
return -1;
}
}第18問:スタック的な処理(LIFO)
【問題】
次のプログラムを実行したとき、出力される値はいくつか。
※関数 push は配列の末尾に要素を追加し、関数 pop は配列の末尾の要素を取り出して削除し、その値を返すものとする。
<参考>
整数型の配列: stack ← {}
push(stack, 10)
push(stack, 20)
整数型: a ← pop(stack)
push(stack, 30)
push(stack, 40)
整数型: b ← pop(stack)
整数型: c ← pop(stack)
(a + b - c) を出力【解答】
30
【解説】
スタック(後入れ先出し:LIFO)の動作を確認する問題です。
stack:{10}stack:{10, 20}a ← pop(stack): 末尾の 20 を取り出す。a = 20。stack:{10}stack:{10, 30}stack:{10, 30, 40}b ← pop(stack): 末尾の 40 を取り出す。b = 40。stack:{10, 30}c ← pop(stack): 末尾の 30 を取り出す。c = 30。stack:{10}- 計算:
a + b - c=20 + 40 - 30= 30
【Javaコード】
Javaでは java.util.Stack クラスなどを使用するほうが簡単ですが、ここでは ArrayList を使って動作を模倣します。
import java.util.ArrayList;
import java.util.List;
public class Main {
public static void main(String[] args) {
List<Integer> stack = new ArrayList<>();
stack.add(10); // push
stack.add(20); // push
int a = stack.remove(stack.size() - 1); // pop
stack.add(30); // push
stack.add(40); // push
int b = stack.remove(stack.size() - 1); // pop
int c = stack.remove(stack.size() - 1); // pop
System.out.println(a + b - c);
}
}第19問:キュー的な処理(FIFO)
【問題】
次のプログラムを実行したとき、出力される値はいくつか。
※関数 enqueue は配列の末尾に要素を追加し、関数 dequeue は配列の先頭の要素を取り出して削除し、その値を返すものとする。
<参考>
整数型の配列: queue ← {}
enqueue(queue, 50)
enqueue(queue, 60)
整数型: a ← dequeue(queue)
enqueue(queue, 70)
enqueue(queue, 80)
整数型: b ← dequeue(queue)
整数型: c ← dequeue(queue)
(a + b - c) を出力【解答】
40
【解説】
キュー(先入れ先出し:FIFO - First In, First Out)の動作を確認する問題です。 スタックとは異なり、追加した順にデータが取り出されます。
queue: {50}queue: {50, 60}a ← dequeue(queue): 先頭の 50 を取り出す。a = 50。queue: {60}queue: {60, 70}queue: {60, 70, 80}b ← dequeue(queue): 先頭の 60 を取り出す。b = 60。queue: {70, 80}c ← dequeue(queue): 先頭の 70 を取り出す。c = 70。queue: {80}
計算: a + b - c = 50 + 60 - 70 = 40
【Javaコード】
Javaでは java.util.Queue インターフェースと ArrayDeque クラスなどを使用するのが一般的ですが、前問のスタックと同様に ArrayList を使って先頭要素(インデックス0)を削除することで動作を模倣します。
import java.util.ArrayList;
import java.util.List;
public class Main {
public static void main(String[] args) {
List<Integer> queue = new ArrayList<>();
queue.add(50); // enqueue (末尾に追加)
queue.add(60); // enqueue
int a = queue.remove(0); // dequeue (先頭の要素を取り出して削除)
queue.add(70); // enqueue
queue.add(80); // enqueue
int b = queue.remove(0); // dequeue
int c = queue.remove(0); // dequeue
System.out.println(a + b - c);
}
}第20問:優先度付きキュー
【問題】
空の優先度付きキューに対して、次の操作を順に行ったとき、最後に出力される値はいくつか。
なお、enqueue(v) は値 v を追加し、dequeue() は現在の中で最も小さい値を取り出して返す操作とする。
<参考>
enqueue(30)
enqueue(10)
enqueue(20)
dequeue() を実行(出力はしない)
enqueue(15)
dequeue() を実行し、その値を出力【解答】
15
【解説】
操作ごとのキューの状態(中身の集合)を追っていきます。
- enqueue(30):キュー内は {30}
- enqueue(10):キュー内は {10, 30}
- enqueue(20):キュー内は {10, 20, 30}
- dequeue():現在最小の 10 が取り出されます。キュー内は {20, 30} になります。
- enqueue(15):キュー内は {15, 20, 30}
- dequeue():現在最小の 15 が取り出され、これが出力されます。
入れた順番(30→10→20→15)ではなく、その時点での「最小値」が常に選ばれるのがポイントです。
【Javaコード】
import java.util.PriorityQueue;
public class Main {
public static void main(String[] args) {
// JavaのPriorityQueueはデフォルトで昇順(小さい順)
PriorityQueue<Integer> pq = new PriorityQueue<>();
pq.enqueue(30);
pq.enqueue(10);
pq.enqueue(20);
pq.poll(); // dequeueに相当(10が削除される)
pq.enqueue(15);
System.out.println(pq.poll()); // 15が出力される
}
}第21問:逆ポーランド記法(後置記法)
【問題】
次のプログラムは、逆ポーランド記法で書かれた配列 tokens を計算するものである。
tokens が {"3", "4", "+", "2", "*"} のとき、出力される結果はいくつか。
※ isDigit は数値かどうかを判定する関数、pop はスタックから取り出す、push は入れる処理とする。
<参考>
文字列型の配列: tokens ← {"3", "4", "+", "2", "*"}
整数型のスタック: stack ← {}
整数型: a, b, i
for (i を 1 から tokensの要素数 まで 1 ずつ増やす)
if (tokens[i] が数値である)
push(stack, tokens[i]を整数に変換)
else
b ← pop(stack)
a ← pop(stack)
if (tokens[i] = "+") push(stack, a + b)
elseif (tokens[i] = "*") push(stack, a * b)
endif
endif
endfor
pop(stack) を出力
【解答】
14
【解説】
逆ポーランド記法では、数値はスタックに積み、演算子が出たら数値を2つ取り出して計算し、結果を戻します。数式で表すと (3 + 4) * 2 です。
"3": スタック[3]"4": スタック[3, 4]"+": 4, 3 を取り出し、3 + 4 = 7をプッシュ。 スタック[7]"2": スタック[7, 2]"*": 2, 7 を取り出し、7 * 2 = 14をプッシュ。 スタック[14]- 最後にポップして 14 が出力されます。
【Javaコード】
import java.util.Stack;
public class Main {
public static void main(String[] args) {
String[] tokens = {"3", "4", "+", "2", "*"};
Stack<Integer> stack = new Stack<>();
for (String token : tokens) {
if (token.matches("\\d+")) {
stack.push(Integer.parseInt(token));
} else {
int b = stack.pop();
int a = stack.pop();
if (token.equals("+")) stack.push(a + b);
else if (token.equals("*")) stack.push(a * b);
}
}
System.out.println(stack.pop());
}
}第22問:単方向リストの操作
【問題】
次のプログラムは、単方向リストの先頭から2番目の要素を削除する処理である。
リストの構造は [Head] -> [A] -> [B] -> [C] となっており、Head.next は要素Aを指している。
プログラム実行後のリストの並びとして正しいものはどれか。
<参考>
クラス ListElement
メンバ変数 val: 文字列型
メンバ変数 next: ListElement型
○手続名: deleteSecond(ListElement: head)
ListElement: p1
ListElement: p2
/* p1は1番目の要素(A)を指す */
p1 ← head.next
/* p2は2番目の要素(B)を指す */
p2 ← p1.next
/* リンクのつなぎ替え */
p1.next ← p2.next【解答】
[Head] -> [A] -> [C]
【解説】
単方向リストの削除操作のトレースです。
- 初期状態:
Head -> A -> B -> C p1 ← head.next:p1は A を指します。p2 ← p1.next:p1(A) の次は B なので、p2は B を指します。p1.next ← p2.next:p2(B) のnextは C です。p1(A) のnextを C に書き換えます。
- 結果、A の次は直接 C を指すようになり、B はリストから外れます。
Head -> A -> C
【Javaコード】
class ListElement {
String val;
ListElement next;
ListElement(String val) { this.val = val; }
}
public class Main {
public static void main(String[] args) {
// リストの構築: Head -> A -> B -> C
ListElement head = new ListElement("Head");
ListElement a = new ListElement("A");
ListElement b = new ListElement("B");
ListElement c = new ListElement("C");
head.next = a;
a.next = b;
b.next = c;
// 削除処理
ListElement p1 = head.next; // A
ListElement p2 = p1.next; // B
p1.next = p2.next; // A -> C
// 結果確認
System.out.println(head.next.val + " -> " + head.next.next.val);
}
}第23問:双方向リスト(ノードの削除)
【問題】
次のプログラムは、配列を用いて実装された双方向リストから、要素 20 を削除する処理である。
処理終了後、要素 10 の「次の要素」を指す next 配列の値はいくつになっているか。
※ prev は前の要素の添字、next は次の要素の添字を表す。
<参考>
/* インデックス: 1 2 3 */
/* 値(data): 10, 20, 30 */
整数型の配列: next ← {2, 3, -1}
整数型の配列: prev ← {-1, 1, 2}
整数型: deleteIdx ← 2 /* 削除する要素(20)の添字 */
整数型: p ← prev[deleteIdx] /* 1 (10の場所) */
整数型: n ← next[deleteIdx] /* 3 (30の場所) */
/* 削除処理:ポインタの付け替え */
if (p ≠ -1)
next[p] ← n
endif
if (n ≠ -1)
prev[n] ← p
endif
next[1] を出力
【解答】
3
【解説】
双方向リストの削除操作では、削除するノードの前後のノードを直接つなぎ合わせます。
- 初期状態:
- ノード1(10)の次は ノード2(20)。 (
next[1] = 2) - ノード2(20)の次は ノード3(30)。
- ノード3(30)の前は ノード2(20)。
- ノード1(10)の次は ノード2(20)。 (
- 削除対象:
deleteIdx = 2(値20)。- 前のノード
pは 1。 - 次のノード
nは 3。
- 前のノード
- 付け替え:
next[p] ← n: 「前のノード(1)の次」を、「次のノード(3)」に書き換えます。- つまり
next[1]が 3 になります。 prev[n] ← p: 「次のノード(3)の前」を、「前のノード(1)」に書き換えます。
- 結果:
next[1]の値は 3 です。これでリストは 10 → 30 と繋がりました。
【Javaコード】
public class Main {
public static void main(String[] args) {
// インデックス0は使わず、1,2,3を使用すると仮定
int[] next = {0, 2, 3, -1};
int[] prev = {0, -1, 1, 2};
int deleteIdx = 2;
int p = prev[deleteIdx]; // 1
int n = next[deleteIdx]; // 3
if (p != -1) next[p] = n;
if (n != -1) prev[n] = p;
System.out.println(next[1]);
}
}
第24問:再帰関数(再帰呼び出し)
【問題】
次のプログラム中の関数 sigma(3) を呼び出したとき、戻り値はいくつか。
<参考>
○整数型: sigma(整数型: n)
if (n = 0)
return 0
endif
return n + sigma(n - 1)
【解答】
6
【解説】
自分自身を呼び出す「再帰関数」の問題です 3。
sigma(n) は 1からnまでの和を求める関数として動作します。
sigma(3)呼び出し: 返り値は3 + sigma(2)sigma(2)呼び出し: 返り値は2 + sigma(1)sigma(1)呼び出し: 返り値は1 + sigma(0)- sigma(0) 呼び出し: 条件 n=0 に合致し、0 を返す。これらを積み上げると、3 + (2 + (1 + 0)) = 6 となります。
【Javaコード】
public class Main {
public static void main(String[] args) {
System.out.println(sigma(3));
}
public static int sigma(int n) {
if (n == 0) {
return 0;
}
return n + sigma(n - 1);
}
}第25問:再帰関数(ユークリッドの互除法)
【問題】
次のプログラム中の関数 calc(24, 9) を呼び出したとき、戻り値はいくつか。
※ mod は剰余を表す。
<参考>
○整数型: calc(整数型: a, 整数型: b)
if (b = 0)
return a
endif
return calc(b, a mod b)【解答】
3
【解説】
これは最大公約数(GCD)を求める「ユークリッドの互除法」の実装です。
calc(24, 9)呼び出し。b(9) は 0 でない。24 mod 9= 6calc(9, 6)を呼び出す。
calc(9, 6)呼び出し。b(6) は 0 でない。9 mod 6= 3calc(6, 3)を呼び出す。
calc(6, 3)呼び出し。b(3) は 0 でない。6 mod 3= 0calc(3, 0)を呼び出す。
calc(3, 0)呼び出し。bは 0 である。a(つまり 3) を返す。
【Javaコード】
public class Main {
public static void main(String[] args) {
System.out.println(calc(24, 9));
}
public static int calc(int a, int b) {
if (b == 0) {
return a;
}
return calc(b, a % b);
}
}第26問:2分木の巡回(再帰)
【問題】
次のプログラムは、2分木を巡回してノードの値を出力する関数 traverse である。
下図の構造を持つ木に対して traverse(Node1) を実行したとき、出力される順番はどれか。
※ nil は子が何もないことを表す。
<参考>
[木の構造]
1
/ \
2 3
/
4クラス Node
メンバ変数 val: 整数型
メンバ変数 left: Node型
メンバ変数 right: Node型
○手続名: traverse(Node: n)
if (n = nil)
return
endif
traverse(n.left)
n.val を出力
traverse(n.right)
【解答】
4, 2, 1, 3
【解説】
これは「通りがけ順(In-order)」の巡回アルゴリズムです。
処理順序:左の部分木 → 自分 → 右の部分木
traverse(1)開始traverse(1.left)つまりtraverse(2)を呼び出し。traverse(2.left)つまりtraverse(4)を呼び出し。traverse(4.left)は nil なのでリターン。- 4 を出力。
traverse(4.right)は nil なのでリターン。
traverse(4)終了。- 2 を出力。
traverse(2.right)は nil なのでリターン。
traverse(2)終了。- 1 を出力。
traverse(1.right)つまりtraverse(3)を呼び出し。traverse(3.left)は nil なのでリターン。- 3 を出力。
traverse(3.right)は nil なのでリターン。
- 出力順序は 4 → 2 → 1 → 3 となります。
【Javaコード】
class Node {
int val;
Node left, right;
Node(int val) { this.val = val; }
}
public class Main {
public static void main(String[] args) {
Node n1 = new Node(1);
Node n2 = new Node(2);
Node n3 = new Node(3);
Node n4 = new Node(4);
n1.left = n2; n1.right = n3;
n2.left = n4;
traverse(n1);
}
static void traverse(Node n) {
if (n == null) return;
traverse(n.left);
System.out.println(n.val);
traverse(n.right);
}
}第27問:2分探索木
【問題】
次のプログラムは、2分探索木から目的の値 target を探す処理である。 target が 7 のとき、比較されるノードの値を順に答えよ。
なお、ノードの構造は left(左の子)、right(右の子)、value(自身の値)を持つものとする。
<参考>
[2分探索木の状態]
根の値:10
10の左の子:5、右の子:15
5の左の子:3、右の子:8
8の左の子:7、右の子:なし整数型: target ← 7
Node: current ← 根のノード
while (current ≠ 未定義)
current.value を出力
if (current.value = target)
ループを終了
elseif (target < current.value)
current ← current.left
else
current ← current.right
endif
endwhile【解答】
10, 5, 8, 7
【解説】
根から順番に、ルールの通りに枝分かれを進んでいきます。
- 1回目:現在の値(current.value)は 10 です。 target(7) < 10 なので、左の子(値:5)へ進みます。
- 2回目:現在の値は 5 です。 target(7) > 5 なので、右の子(値:8)へ進みます。
- 3回目:現在の値は 8 です。 target(7) < 8 なので、左の子(値:7)へ進みます。
- 4回目:現在の値は 7 です。 target(7) = 7 となり、探索が成功して終了します。
【Javaコード】
class Node {
int value;
Node left, right;
Node(int val) { this.value = val; }
}
public class Main {
public static void main(String[] args) {
// 木の構築(簡易版)
Node root = new Node(10);
root.left = new Node(5);
root.right = new Node(15);
root.left.right = new Node(8);
root.left.right.left = new Node(7);
int target = 7;
Node current = root;
while (current != null) {
System.out.println(current.value);
if (current.value == target) break;
current = (target < current.value) ? current.left : current.right;
}
}
}第28問:グラフ走査(深さ優先探索・再帰)
【問題】
次のプログラムは、ノード1からスタートして、接続されているノードを「深さ優先探索 (DFS)」で順に訪問するものである。
visit(1) を呼び出したとき、出力される数値の順序はどれか。
※ adj は隣接リストを表し、adj[1] はノード1から行けるノードのリストである。
<参考>
配列の配列: adj ← {
{}, /* index 0: 未使用 */
{2, 3}, /* index 1: 1から2と3へ */
{4}, /* index 2: 2から4へ */
{}, /* index 3: 行き先なし */
{} /* index 4: 行き先なし */
}
○visit(整数型: n)
n を出力
整数型: i
for (i を 1 から adj[n]の要素数 まで 1 ずつ増やす)
visit(adj[n][i])
endfor【解答】
1 → 2 → 4 → 3
【解説】
深さ優先探索(DFS)は、行けるところまで奥へ進み、行き止まりになったら戻る(バックトラック)アルゴリズムです。
- visit(1) 呼び出し。 1 を出力。
- 隣接リスト
adj[1]は{2, 3}。まずは先頭の 2 へ進む。
- 隣接リスト
- visit(2) 呼び出し。 2 を出力。
- 隣接リスト
adj[2]は{4}。 4 へ進む。
- 隣接リスト
- visit(4) 呼び出し。 4 を出力。
- 隣接リスト
adj[4]は空。関数終了し、visit(2)へ戻る。 visit(2)もこれ以上行く場所がないので終了し、visit(1)へ戻る。
- 隣接リスト
- visit(1) の続き
- さきほどは 2 へ行ったので、次は 3 へ進む。
- visit(3) 呼び出し。 3 を出力。
- 隣接リスト
adj[3]は空。関数終了。
- 隣接リスト
結果、順序は 1, 2, 4, 3 となります。
【Javaコード】
public class Main {
static int[][] adj = {
{},
{2, 3},
{4},
{},
{}
};
public static void main(String[] args) {
visit(1);
}
public static void visit(int n) {
System.out.println(n);
for (int neighbor : adj[n]) {
visit(neighbor);
}
}
}第29問:幅優先探索(BFS)
【問題】
次のプログラムは、キューを用いてグラフを「幅優先探索 (BFS)」するものである。
ノード1から開始したとき、ノードが訪問(出力)される順序として正しいものはどれか。
※ adj は隣接リストを表す。
<参考>
配列の配列: adj ← {
{}, /* 0: 未使用 */
{2, 3}, /* 1: 1から2, 3へ */
{4, 5}, /* 2: 2から4, 5へ */
{6}, /* 3: 3から6へ */
{}, {}, {} /* 4, 5, 6: 行き先なし */
}
整数型のキュー: queue ← {}
enqueue(queue, 1) /* 開始ノード */
while (queue が空でない)
整数型: n ← dequeue(queue)
n を出力
整数型: i
for (i を 1 から adj[n]の要素数 まで 1 ずつ増やす)
enqueue(queue, adj[n][i])
endfor
endwhile
【解答】
1 → 2 → 3 → 4 → 5 → 6
【解説】
深さ優先探索(DFS)とは異なり、幅優先探索(BFS)は「近いところ」から順に、同じ深さの兄弟を全て訪問してから次へ進みます。
- キュー:
{1}。 1を取り出し出力。子2, 3を追加。 キュー:{2, 3} - 2を取り出し出力。子
4, 5を追加。 キュー:{3, 4, 5} - 3を取り出し出力。子
6を追加。 キュー:{4, 5, 6} - 4を取り出し出力。子なし。 キュー:
{5, 6} - 5を取り出し出力。子なし。 キュー:
{6} - 6を取り出し出力。子なし。 キュー: {}順序は 1, 2, 3, 4, 5, 6 となります。
【Javaコード】
import java.util.LinkedList;
import java.util.Queue;
public class Main {
public static void main(String[] args) {
int[][] adj = {
{},
{2, 3},
{4, 5},
{6},
{}, {}, {}
};
Queue<Integer> queue = new LinkedList<>();
queue.add(1);
while (!queue.isEmpty()) {
int n = queue.poll();
System.out.println(n);
for (int neighbor : adj[n]) {
queue.add(neighbor);
}
}
}
}第30問:ヒープ構造(最大ヒープへの追加)
【問題】
次のプログラムは、配列 heap を「最大ヒープ(親は子より大きい)」として維持しながら要素を追加する関数 pushHeap である。
空のヒープに対し、データ 10, 30, 20, 5, 40 を順に追加した直後、配列 heap の先頭(根)の要素はいくつか。
<参考>
整数型の配列: heap ← {}
整数型: size ← 0
○pushHeap(整数型: val)
size ← size + 1
整数型: k ← size
heap[k] ← val
/* 親と比較して、親より大きければ交換(アップヒープ) */
while (k > 1 and heap[k] > heap[k ÷ 2])
整数型: parent ← k ÷ 2
整数型: temp ← heap[k]
heap[k] ← heap[parent]
heap[parent] ← temp
k ← parent
endwhile
【解答】
40
【解説】
最大ヒープでは、常に「最大の要素」が根(配列の先頭)に来ます。追加されるたびに親と比較して浮上していきます。
- push(10):
{10}。根は10。 - push(30): 末尾に追加
{10, 30}。30 > 10 なので交換。{30, 10}。根は30。 - push(20): 末尾に追加
{30, 10, 20}。20 < 30 (親) なのでそのまま。根は30。 - push(5): 末尾に追加
{30, 10, 20, 5}。5 < 10 (親) なのでそのまま。根は30。 - push(40): 末尾に追加
{30, 10, 20, 5, 40}。- 親(10)と比較: 40 > 10 なので交換 →
{30, 40, 20, 5, 10}。 - 親(30)と比較: 40 > 30 なので交換 →
{40, 30, 20, 5, 10}。 - 根まで到達したため終了。根は 40 です。
- 親(10)と比較: 40 > 10 なので交換 →
【Javaコード】
import java.util.ArrayList;
import java.util.List;
public class Main {
// 1始まりのインデックスを模倣するためにダミー要素を入れる
static List<Integer> heap = new ArrayList<>();
public static void main(String[] args) {
heap.add(0); // index 0 (dummy)
int[] data = {10, 30, 20, 5, 40};
for (int val : data) {
pushHeap(val);
}
System.out.println(heap.get(1)); // 根を出力
}
public static void pushHeap(int val) {
heap.add(val);
int k = heap.size() - 1;
while (k > 1 && heap.get(k) > heap.get(k / 2)) {
int parent = k / 2;
int temp = heap.get(k);
heap.set(k, heap.get(parent));
heap.set(parent, temp);
k = parent;
}
}
}第31問:ハッシュ法(オープンアドレス法)
【問題】
次のプログラムは、ハッシュ関数 h(x) = x mod 10 を用いてデータを配列 table に格納するものである。
衝突(コリジョン)が発生した場合は、格納位置を 1 つ後ろにずらす「オープンアドレス法(線形探索法)」を用いる。
データ 15, 25, 35 を順に格納した後、データ 35 が格納されている配列の添字(インデックス)はいくつか。
※配列の初期値はすべて -1(空)とする。
<参考>
整数型の配列: table ← {-1, -1, -1, ...} (要素数10)
整数型の配列: data ← {15, 25, 35}
整数型: i, pos
for (i を 1 から 3 まで 1 ずつ増やす)
pos ← data[i] mod 10
/* 空きが見つかるまで位置をずらす */
while (table[pos] ≠ -1)
pos ← (pos + 1) mod 10
endwhile
table[pos] ← data[i]
endfor
35 が格納された pos を出力
【解答】
7
【解説】
ハッシュ値の衝突処理をトレースする問題です。ハッシュ値はすべて x mod 10 で計算されます。
- 15 の格納:
- ハッシュ値:
15 mod 10 = 5。 table[5]は空なので、そこに 15 を格納します。
- ハッシュ値:
- 25 の格納:
- ハッシュ値:
25 mod 10 = 5。 table[5]には既に 15 があるため衝突します。posを 1 ずらして 6 にします。table[6]は空なので、そこに 25 を格納します。
- ハッシュ値:
- 35 の格納:
- ハッシュ値:
35 mod 10 = 5。 table[5](15) → 埋まっている。次は 6。table[6](25) → 埋まっている。次は 7。table[7]は空なので、そこに 35 を格納します。- 結果、7 が出力されます。
- ハッシュ値:
【Javaコード】
import java.util.Arrays;
public class Main {
public static void main(String[] args) {
int[] table = new int[10];
Arrays.fill(table, -1);
int[] data = {15, 25, 35};
int finalPos = -1;
for (int x : data) {
int pos = x % 10;
while (table[pos] != -1) {
pos = (pos + 1) % 10;
}
table[pos] = x;
if (x == 35) finalPos = pos;
}
System.out.println(finalPos);
}
}3. 上級
第32問:マージソート(併合処理)
【問題】
次のプログラムは、昇順に整列済みの2つの配列 arrA と arrB を、昇順を保ったまま1つの配列 arrC にまとめる(マージする)処理である。
プログラム実行直後、arrC の 4番目 の要素に格納されている値はいくつか。
<参考>
整数型の配列: arrA ← {2, 5, 9}
整数型の配列: arrB ← {1, 6, 8}
整数型の配列: arrC ← {} (要素数6の空配列)
整数型: a ← 1, b ← 1, c ← 1
while (a ≤ 3 and b ≤ 3)
if (arrA[a] < arrB[b])
arrC[c] ← arrA[a]
a ← a + 1
else
arrC[c] ← arrB[b]
b ← b + 1
endif
c ← c + 1
endwhile
/* 残りの要素をコピーする処理は省略 */
arrC[4] を出力
【解答】
6
【解説】
2つの配列の先頭同士を比較し、小さい方を採用していく処理です。
- 1回目:
A:2vsB:1。 1 (B) を採用。arrC={1},bが進む。 - 2回目:
A:2vsB:6。 2 (A) を採用。arrC={1, 2},aが進む。 - 3回目:
A:5vsB:6。 5 (A) を採用。arrC={1, 2, 5},aが進む。 - 4回目:
A:9vsB:6。 6 (B) を採用。arrC={1, 2, 5, 6},bが進む。- ここで
arrCの4番目の要素が決まりました。値は 6 です。
- ここで
【Javaコード】
public class Main {
public static void main(String[] args) {
int[] arrA = {2, 5, 9};
int[] arrB = {1, 6, 8};
int[] arrC = new int[6];
int a = 0, b = 0, c = 0;
// 擬似言語の1始まりを0始まりに読み替え
while (a < arrA.length && b < arrB.length) {
if (arrA[a] < arrB[b]) {
arrC[c++] = arrA[a++];
} else {
arrC[c++] = arrB[b++];
}
}
// Java配列は0から始まるため、4番目はインデックス3
System.out.println(arrC[3]);
}
}第33問:クイックソート(パーティション分割)
【問題】
次のプログラムは、クイックソートの一部である「パーティション分割」を行う関数 partition である。
配列 data の最後の要素を「基準値(ピボット)」とし、それより小さい値を左側、大きい値を右側に集める処理を行う。
プログラム実行直後、配列 data の内容はどのように変化しているか。
<参考>
整数型の配列: data ← {2, 6, 1, 7, 4}
整数型: pivot ← data[dataの要素数] /* ピボットは最後の 4 */
整数型: i ← 0 /* 小さい要素の境界線 */
整数型: j, temp
/* 1番目から (要素数-1) 番目まで走査 */
for (j を 1 から dataの要素数 - 1 まで 1 ずつ増やす)
if (data[j] < pivot)
i ← i + 1
/* data[i] と data[j] を交換 */
temp ← data[i]
data[i] ← data[j]
data[j] ← temp
endif
endfor
/* 最後にピボットを境界線の隣に移動 */
temp ← data[i + 1]
data[i + 1] ← data[dataの要素数]
data[dataの要素数] ← temp
data を出力
【解答】
{2, 1, 4, 7, 6}
【解説】
ピボット(4)より小さい値を配列の前方に詰め込み、最後にピボットをその境界に置く処理です。
- 初期状態:
i=0,pivot=4, 配列{2, 6, 1, 7, 4}。 - j=1:
2 < 4なので、iを1増やしてi=1。data[1](2) とdata[1](2) を交換(変化なし)。 - j=2:
6 > 4なので何もしない。 - j=3:
1 < 4なので、iを1増やしてi=2。data[2](6) とdata[3](1) を交換。配列は{2, 1, 6, 7, 4}。 - j=4:
7 > 4なので何もしない。 - ループ終了後: data[i+1] つまり data[3](6) と、末尾のピボット(4)を交換。配列は {2, 1, 4, 7, 6} となります。これで、4より左は小さく、右は大きくなりました。
【Javaコード】
import java.util.Arrays;
public class Main {
public static void main(String[] args) {
int[] data = {2, 6, 1, 7, 4};
int pivot = data[data.length - 1]; // pivot = 4
int i = -1; // Javaは0始まりなので、擬似言語の0に対応するのは-1
for (int j = 0; j < data.length - 1; j++) {
if (data[j] < pivot) {
i++;
int temp = data[i];
data[i] = data[j];
data[j] = temp;
}
}
// ピボットの移動
int temp = data[i + 1];
data[i + 1] = data[data.length - 1];
data[data.length - 1] = temp;
System.out.println(Arrays.toString(data));
}
}第34問:バケットを用いたビンソート
【問題】
次のプログラムを実行したとき、最終的な array の内容は?
<参考>
整数型の配列: array ← {3, 5, 2, 3, 1}
整数型の配列: bucket ← {0, 0, 0, 0, 0} // 1〜5の出現回数を記録
整数型: i, j, k
// ステップ1:出現回数を数える
for (i を 1 から 5 まで 1 ずつ増やす)
bucket[array[i]] ← bucket[array[i]] + 1
endfor
// ステップ2:バケツから戻す
k ← 1
for (i を 1 から 5 まで 1 ずつ増やす)
for (j を 1 から bucket[i] まで 1 ずつ増やす)
array[k] ← i
k ← k + 1
endfor
endfor
array を出力
【解答】
{1, 2, 3, 3, 5}
【解説】
このプログラムは「どの数字が何回出たか」をメモし、そのメモ通りに数字を書き戻しています。
- カウント処理: array を走査すると、bucket の中身は {1, 1, 2, 0, 1} になります(1が1回、2が1回、3が2回、4が0回、5が1回)。
- 書き戻し処理:
- i=1(数字の1): bucket[1]は1なので、array[1]に1を書き、kを2に進めます。
- i=2(数字の2): bucket[2]は1なので、array[2]に2を書き、kを3に進めます。
- i=3(数字の3): bucket[3]は2なので、array[3]とarray[4]に3を書き、kを5に進めます。
- i=4(数字の4): bucket[4]は0なので、何もしません。
- i=5(数字の5): bucket[5]は1なので、array[5]に5を書き、kを6に進めます。
結果として、小さい順に並んだ {1, 2, 3, 3, 5} が得られます。
【Javaコード】
public class Main {
public static void main(String[] args) {
int[] array = {3, 5, 2, 3, 1};
int[] bucket = new int[6]; // 1〜5を使用するためサイズ6を確保
// 出現回数をカウント
for (int value : array) {
bucket[value]++;
}
// 元の配列に書き戻す
int k = 0;
for (int i = 1; i <= 5; i++) {
while (bucket[i] > 0) {
array[k++] = i;
bucket[i]--;
}
}
for (int n : array) System.out.print(n + " ");
}
}第35問:バケット法による重複確認の最適化
【問題】
2重ループは、例えば「クラス全員(n人)が、自分以外全員(n-1人)と総当たりで握手する」ような処理です。人数が10倍になると、処理回数は100倍に膨れ上がります。
非効率な例:重複チェック(2重ループ)
配列の中に同じ数字があるか探すとき、全ての組み合わせを調べると計算量は $O(n^{2})$ となります。
整数型の配列: data ← {3, 1, 4, 1, 5}
論理型: has_duplicate ← false
整数型: i, j
for (i を 1 から 4 まで 1 ずつ増やす)
for (j を i + 1 から 5 まで 1 ずつ増やす)
if (data[i] = data[j])
has_duplicate ← true
endif
endfor
endfor2重ループを回避する代表的な手法は、「一度見た情報を記録しておく(メモ化・バケット)」という考え方です。
次のプログラムを実行したとき、出力される has_duplicate の値はいくつか。
※値の範囲は 1 から 9 とする。
整数型の配列: data ← {3, 1, 4, 1, 5}
整数型の配列: checked ← {0, 0, 0, 0, 0, 0, 0, 0, 0} // 1〜9の出現を記録
論理型: has_duplicate ← false
整数型: i, val
for (i を 1 から 5 まで 1 ずつ増やす)
val ← data[i]
if (checked[val] = 1)
has_duplicate ← true
else
checked[val] ← 1
endif
endfor
has_duplicate を出力【解答】
true
【解説】
このアルゴリズムは、2重ループを使わずに1回の走査($O(n)$)で重複を見つけています。
- i=1: data[1]は3。checked[3]は0なので、checked[3]を1に更新。
- i=2: data[2]は1。checked[1]は0なので、checked[1]を1に更新。
- i=3: data[3]は4。checked[4]は0なので、checked[4]を1に更新.
- i=4: data[4]は1。checked[1]はすでに1なので、has_duplicate を true に変更。
- ループ終了。
【Javaコード】
public class Main {
public static void main(String[] args) {
int[] data = {3, 1, 4, 1, 5};
// 出現した数字を記録する(1〜9を想定して10個の領域を確保)
boolean[] checked = new boolean[10];
boolean hasDuplicate = false;
for (int i = 0; i < data.length; i++) {
int val = data[i];
if (checked[val]) {
hasDuplicate = true;
break; // 重複が見つかった時点で終了
}
checked[val] = true;
}
System.out.println(hasDuplicate);
}
}第36問:文字列探索(力まかせ法)
【問題】
次のプログラムは、文字列 text の中に、パターン pattern が含まれているかを探す処理である。
match が true(発見)になったとき、pattern の先頭文字が一致した text 内の位置 i はいくつか。
<参考>
文字列型: text ← "BABABABC"
文字列型: pattern ← "ABC"
整数型: i, j
ブール型: match ← false
for (i を 1 から (textの文字数 - patternの文字数 + 1) まで 1 ずつ増やす)
match ← true
for (j を 1 から patternの文字数 まで 1 ずつ増やす)
if (text[i + j - 1] ≠ pattern[j])
match ← false
break /* 内側のループを抜ける */
endif
endfor
if (match = true)
break /* 外側のループを抜ける */
endif
endfor
i を出力
【解答】
6
【解説】
テキストの先頭から順に、パターンと一致するかを確認します。
- i=1 ("BAB..."): "B" vs "A" → 不一致。
- i=2 ("ABA..."): "A" vs "A"(一致), "B" vs "B"(一致), "A" vs "C"(不一致)。
- i=3 ("BAB..."): "B" vs "A" → 不一致。
- i=4 ("ABA..."): "A" vs "A"(一致), "B" vs "B"(一致), "A" vs "C"(不一致)。
- i=5 ("BAB..."): "B" vs "A" → 不一致。
- i=6 ("ABC"): "A" vs "A"(一致), "B" vs "B"(一致), "C" vs "C"(一致)。
- ここで
matchがtrueのままループを完走します。 - 答えは 6 です。
- ここで
【Javaコード】
public class Main {
public static void main(String[] args) {
String text = "BABABABC";
String pattern = "ABC";
int n = text.length();
int m = pattern.length();
boolean match = false;
int foundIndex = -1;
for (int i = 0; i <= n - m; i++) {
match = true;
for (int j = 0; j < m; j++) {
if (text.charAt(i + j) != pattern.charAt(j)) {
match = false;
break;
}
}
if (match) {
foundIndex = i + 1; // 1始まりに合わせる
break;
}
}
System.out.println(foundIndex);
}
}第37問:文字列の圧縮(ランレングス符号化の基本)
【問題】
次のプログラムを実行したとき、出力される文字列は何か。
※演算子 + は文字列の連結を表す。
<参考>
文字列型: s ← "AAABCCCC"
文字列型: res ← ""
整数型: count ← 1
整数型: i
for (i を 1 から sの文字数 - 1 まで 1 ずつ増やす)
if (s の i 文字目 = s の (i + 1) 文字目)
count ← count + 1
else
res ← res + s の i 文字目 + countを文字列にしたもの
count ← 1
endif
endfor
res ← res + s の 末尾の文字 + countを文字列にしたもの
res を出力【解答】
"A3B1C4"
【解説】
連続する文字を「文字+個数」の形式に変換するアルゴリズムです。
i=1('A'),i+1('A') → 一致。count=2。i=2('A'),i+1('A') → 一致。count=3。i=3('A'),i+1('B') → 不一致。resに "A3" を追加。count=1 にリセット。i=4('B'),i+1('C') → 不一致。resに "B1" を追加(現在は "A3B1")。count=1 にリセット。i=5('C'),i+1('C') → 一致。count=2。i=6('C'),i+1('C') → 一致。count=3。i=7('C'),i+1('C') → 一致。count=4。- ループ終了後、最後の文字とカウントを追加。res に "C4" を追加。結果は "A3B1C4" となります。
【Javaコード】
public class Main {
public static void main(String[] args) {
String s = "AAABCCCC";
String res = "";
int count = 1;
for (int i = 0; i < s.length() - 1; i++) {
if (s.charAt(i) == s.charAt(i + 1)) {
count++;
} else {
res = res + s.charAt(i) + count;
count = 1;
}
}
// 最後の部分を追加
res = res + s.charAt(s.length() - 1) + count;
System.out.println(res);
}
}第38問:文字列の置換
【問題】
次のプログラムを実行したとき、出力される target_str の内容は?
文字型の配列: target_str ← {'A', 'B', 'C', 'D', 'B', 'C'}
文字型の配列: search_word ← {'B', 'C'}
文字型: replace_char ← 'X'
整数型: i, j
整数型: len ← 6 (target_strの長さ)
for (i を 1 から len - 1 まで 1 ずつ増やす)
if (target_str[i] = search_word[1] かつ target_str[i+1] = search_word[2])
target_str[i] ← replace_char
// 次の文字を詰める処理(簡易化のため' 'を代入)
target_str[i+1] ← ' '
endif
endfor
target_str を出力【解答】
{'A', 'X', ' ', 'D', 'X', ' '}
【解説】このアルゴリズムは、配列を走査しながら「'B' の次に 'C' が来ているか」をセットで確認しています。
- i=1のとき:target_str[1]は 'A'。条件に合いません。
- i=2のとき:target_str[2]は 'B'、target_str[3]は 'C'。search_word と一致するため、target_str[2]を 'X' に書き換え、target_str[3]に空白 ' ' を入れます。
- i=3のとき:target_str[3]は ' '(書き換え済み)。条件に合いません。
- i=4のとき:target_str[4]は 'D'。条件に合いません。
- i=5のとき:target_str[5]は 'B'、target_str[6]は 'C'。一致するため、target_str[5]を 'X' に、target_str[6]を ' ' にします。
結果として、{'A', 'X', ' ', 'D', 'X', ' '} という形になります。
【Javaコード】
public class Main {
public static void main(String[] args) {
char[] targetStr = {'A', 'B', 'C', 'D', 'B', 'C'};
char[] searchWord = {'B', 'C'};
char replaceChar = 'X';
for (int i = 0; i < targetStr.length - 1; i++) {
// 現在の文字と次の文字が検索語と一致するか
if (targetStr[i] == searchWord[0] && targetStr[i+1] == searchWord[1]) {
targetStr[i] = replaceChar;
targetStr[i+1] = ' '; // 2文字目を空文字扱いに
}
}
System.out.println(new String(targetStr));
}
}第39問:ビット演算(シフト演算を用いた数値計算)
【問題】
次のプログラムを実行したとき、出力される value の値はいくつか。
<参考>
整数型: a ← 6
整数型: b ← 32
整数型: value
a ← a << 2
b ← b >> 3
value ← a + b
value を出力【解答】
28
【解説】
それぞれの変数がシフト演算によってどのように変化するかを、2進数の動きとともに確認します。
- a の計算(左シフト):a = 6 を2進数で表すと「110」です。これを左に2ビットシフト(a << 2)すると「11000」となります。10進数に戻すと 24。
- b の計算(右シフト):b = 32 を2進数で表すと「100000」です。これを右に3ビットシフト(b >> 3)すると「100」となります。10進数に戻すと 4 です。
- 合計の計算:value = 24 + 4 = 28 となります。
【Javaコード】
public class Main {
public static void main(String[] args) {
int a = 6;
int b = 32;
// 左に2ビットシフト(4倍)
a = a << 2;
// 右に3ビットシフト(1/8倍)
b = b >> 3;
int value = a + b;
System.out.println(value);
}
}第40問:ビット演算(論理積とシフト)
【問題】
次のプログラム中の関数 getBit(20, 3) を呼び出したとき、戻り値はいくつか。
※整数 20 の2進数表現は 10100 である。
※ << は左シフト、and はビットごとの論理積を表す。
<参考>
○整数型: getBit(整数型: val, 整数型: n)
整数型: mask ← 1
/* 1 を (n-1) ビット左にシフトする */
mask ← mask << (n - 1)
if ((val and mask) ≠ 0)
return 1
else
return 0
endif【解答】
1
【解説】
指定されたビット位置(下位からn番目)が 1 か 0 かを判定する処理です。
引数: val = 20 (10100), n = 3
maskの初期値は1(00001)。maskを3 - 1 = 2ビット左シフトします。00001<< 2 =00100(10進数で4)
valとmaskの論理積 (and) をとります。10100(20)00100(4)- and ↓
00100(4)
- 結果は 4 であり、0 ではないため、if 文が真となり 1 を返します。これは、下位から3番目のビットが立っていることを意味します。
【Javaコード】
public class Main {
public static void main(String[] args) {
System.out.println(getBit(20, 3));
}
static int getBit(int val, int n) {
int mask = 1;
mask = mask << (n - 1);
if ((val & mask) != 0) {
return 1;
} else {
return 0;
}
}
}第41問:ビット操作と論理演算(XOR)
【問題】
次のプログラムを実行したとき、出力される値はいくつか。
※ xor は排他的論理和を表し、2進数でビットごとに演算を行う。
<参考>
整数型: a ← 10
整数型: b ← 6
整数型: temp
/* 値の交換(XORスワップアルゴリズムの一部) */
temp ← a xor b
a ← temp
temp ← a xor b
/* ここでの temp の値を出力 */
temp を出力
【解答】
10
【解説】
ビット演算の性質を問う問題です。
10進数の10は2進数で 1010、6は 0110 です。
- 最初の
temp:1010(10) xor0110(6) =1100(12)。aに 12 が代入されます。
- 次の
temp:- 現在の
aは 12 (1100)。 bは変わらず 6 (0110)。1100(12) xor0110(6) =1010(10)。- 結果として、元の
aの値である 10 が出力されます。
- 現在の
【Javaコード】
public class Main {
public static void main(String[] args) {
int a = 10; // 1010
int b = 6; // 0110
int temp = a ^ b; // 1100 (12)
a = temp;
temp = a ^ b; // 1100 ^ 0110 = 1010 (10)
System.out.println(temp);
}
}第42問:パリティビットと誤り検出
【問題】
次のプログラムは、7ビットのデータに「偶数パリティビット」を付加して8ビットにする処理である。
入力データ data が 1011001 のとき、出力される parity の値(0 または 1)はいくつか。
※偶数パリティとは、データとパリティビットを合わせた「1」の個数が偶数になるようにする方式である。
<参考>
/* data は整数の配列として各ビットを表す {1, 0, 1, 1, 0, 0, 1} */
整数型の配列: data ← {1, 0, 1, 1, 0, 0, 1}
整数型: sum ← 0
整数型: k, parity
for (k を 1 から 7 まで 1 ずつ増やす)
sum ← sum + data[k]
endfor
if (sum mod 2 = 0)
parity ← 0
else
parity ← 1
endif
parity を出力【解答】
0
【解説】
偶数パリティでは、「1の総数」が偶数ならパリティビットは0、奇数なら1になります(そうすることで全体の1の数を偶数にするため)。
- 配列
dataの要素を合計します。1 + 0 + 1 + 1 + 0 + 0 + 1= 4
- 合計
sumは 4 です。 4 mod 2は 0(偶数)です。- 条件分岐
if (sum mod 2 = 0)が真となるため、parityには 0 が代入されます。
【Javaコード】
public class Main {
public static void main(String[] args) {
int[] data = {1, 0, 1, 1, 0, 0, 1};
int sum = 0;
for (int bit : data) {
sum += bit;
}
int parity;
if (sum % 2 == 0) {
parity = 0;
} else {
parity = 1;
}
System.out.println(parity);
}
}メモリの繋がり(ポインタ概念)や、自分自身を呼び出す複雑な処理を扱う段階です。
第43問:クラスとインスタンス(状態管理)
【問題】
次のプログラムを実行したとき、出力される値はいくつか。
クラス Counter
メンバ変数 count: 整数型
○Counter() /* コンストラクタ */
count ← 0
○add(整数型: n)
count ← count + n
○clear()
count ← 0
/* メイン処理 */
Counter: c1 ← Counter()
Counter: c2 ← Counter()
c1.add(5)
c2.add(10)
c1.add(3)
c2.clear()
c2.add(2)
(c1.count + c2.count) を出力【解答】
10
【解説】
オブジェクト指向における「インスタンスごとの独立性」を問う問題です。
c1 と c2 は別のメモリ領域を持つため、互いの count は干渉しません。
c1.add(5):c1.countは 5。c2.add(10):c2.countは 10。c1.add(3):c1.countは 5 + 3 = 8。c2.clear():c2.countは 0。c2.add(2):c2.countは 0 + 2 = 2。- 出力:
c1.count(8) +c2.count(2) = 10。
【Javaコード】
class Counter {
int count;
Counter() { count = 0; }
void add(int n) { count += n; }
void clear() { count = 0; }
}
public class Main {
public static void main(String[] args) {
Counter c1 = new Counter();
Counter c2 = new Counter();
c1.add(5);
c2.add(10);
c1.add(3);
c2.clear();
c2.add(2);
System.out.println(c1.count + c2.count);
}
}第44問:平面上の2点間の距離を求める
【問題】
次のプログラムを実行したとき、出力される distance の値はいくつか。 なお、sqrt(n) は $n$ の平方根を返す関数とする。
型: Point {
実数型: x
実数型: y
}
Point: p1 ← {x: 1.0, y: 1.0}
Point: p2 ← {x: 4.0, y: 5.0}
実数型: dx, dy, distance
dx ← p2.x - p1.x
dy ← p2.y - p1.y
distance ← sqrt(dx * dx + dy * dy)
distance を出力【解答】
5.0
【解説】
2点の座標から、直角三角形の各辺の長さを求めて計算します。
- 横方向の差(dx)の計算: p2.x(4.0) - p1.x(1.0) = 3.0
- 縦方向の差(dy)の計算: p2.y(5.0) - p1.y(1.0) = 4.0
- 2乗の和の計算: (3.0 * 3.0) + (4.0 * 4.0) = 9.0 + 16.0 = 25.0
- 平方根の計算: sqrt(25.0) = 5.0
よって、2点間の距離は 5.0 となります。
【Javaコード】
public class Main {
public static void main(String[] args) {
double x1 = 1.0, y1 = 1.0;
double x2 = 4.0, y2 = 5.0;
double dx = x2 - x1;
double dy = y2 - y1;
// Math.sqrtは平方根、Math.pow(n, 2)は2乗を求めます
double distance = Math.sqrt(dx * dx + dy * dy);
System.out.println(distance);
}
}効率化の極致や、数学的な知識、AI・セキュリティの基礎となる段階です。
第45問:ゲーム木の探索(ミニマックス法)
【問題】
次のプログラムは、ゲーム木のスコアを計算する再帰関数 minimax である。
minimax(0, true) を呼び出したとき、戻り値はいくつか。
※引数 isMax が true のときは自分の手番(最大値を選ぶ)、false のときは相手の手番(最小値を選ぶ)を表す。
<参考>
/* 木構造のデータ(葉のスコア)を配列で表現 */
/* index 0 は根。1,2 はその子。3,4,5,6 は葉 */
整数型の配列: scores ← {0, 0, 0, 5, 3, 8, 1}
○整数型: minimax(整数型: node, ブール型: isMax)
/* 葉ノード(これ以上子がない)なら値を返す */
if (node ≥ 3)
return scores[node]
endif
if (isMax = true)
/* 自分: 子ノード(左:2*node+1, 右:2*node+2)のうち大きい方を選ぶ */
return max(minimax(2 * node + 1, false), minimax(2 * node + 2, false))
else
/* 相手: 小さい方を選ぶ */
return min(minimax(2 * node + 1, true), minimax(2 * node + 2, true))
endif
【解答】
3
【解説】
自分はスコアを最大化、相手は最小化するように動くと仮定して、根(ルート)の値を求める問題です。
- 葉の値: ノード3=5, ノード4=3, ノード5=8, ノード6=1。
- ノード1(相手の番: node 3, 4 から最小を選択):
- min(5, 3) = 3
- ノード2(相手の番: node 5, 6 から最小を選択):
- min(8, 1) = 1
- ノード0(自分の番: node 1, 2 から最大を選択):
- max(3, 1) = 3
- したがって、戻り値は 3 です。
【Javaコード】
public class Main {
static int[] scores = {0, 0, 0, 5, 3, 8, 1}; // index 0~6
public static void main(String[] args) {
System.out.println(minimax(0, true));
}
public static int minimax(int node, boolean isMax) {
// 簡易的な判定:配列外なら終了とみなす等の処理が必要だが
// ここでは問題文の通りnode>=3で葉とする
if (node >= 3) {
return scores[node];
}
if (isMax) {
int left = minimax(2 * node + 1, false);
int right = minimax(2 * node + 2, false);
return Math.max(left, right);
} else {
int left = minimax(2 * node + 1, true);
int right = minimax(2 * node + 2, true);
return Math.min(left, right);
}
}
}