
AI時代の「数学」をPythonで始めよう!線形代数の第一歩
こんにちは。ゆうせいです。
いよいよ今日から、Pythonを使って「線形代数(せんけいだいすう)」という数学の分野を一緒に探検していきましょう!
「え、数学? しかも線形代数って... なんだか難しそう」
そう感じたかもしれませんね。
たしかに、大学の数学の授業で出てくるような、難しい記号や数式ばかりを想像してしまうかもしれません。
ですが、心配は無用です!
このシリーズの第1章であるこの記事では、難しい計算は一切しません。
まずは、「線形代数って、そもそも何?」「なんでそれをPythonで学ぶの?」という、一番大事な「スタート地点」を、分かりやすい言葉で解き明かしていきます。
線形代数って、結局なに?
では、さっそくですが、「線形代数」という言葉を分解してみましょう。
「線形」と「代数」ですね。
まず「代数」とは何でしょう?
これは、中学・高校の数学で触れた「文字式」のことだと思ってください。
例えば xや yを使って方程式を解いたりしましたよね。数字の代わりに文字(記号)を使って、ものごとの関係性を扱う分野が「代数」です。
では、今回の主役である「線形」とは何でしょうか?
「線形」とは、すごく簡単に言うと「まっすぐ」という意味です。
グラフに書いたときに、ぐにゃぐにゃ曲がった曲線ではなく、ビシッと引かれた「直線」になるような、単純な関係性を表します。
つまり「線形代数」とは、「まっすぐ(線形)」で「単純な関係性」を、「文字(代数)」を使って扱うための数学、というイメージを持ってみてください。
「それだけ? でも、それがAIとか写真加工にどう繋がるの?」
良い質問ですね!
ここで、とても大事な「例え話」をします。
あなたが今、スマホでモノクロの写真を撮ったと想像してください。
その写真、コンピュータの中ではどうなっていると思いますか?
実は、それは単なる「数字の表」なんです。
写真をものすごく細かく「マス目」に区切って、その一つ一つのマス(ピクセルと言います)に、「どれくらい黒いか(または白いか)」を数字で割り当てています。
例えば「0 = 真っ黒」「255 = 真っ白」のように。
数万、数百万個の数字が並んだ「巨大な表」。それが写真の正体です。
もし、この写真全体を「少し明るく」したい場合、どうしますか?
手作業で何万個もの数字を一つずつ「+10」していくのは... 想像するだけで気が遠くなりますよね。
ここで線形代数の出番です!
線形代数は、こういった「数字がたくさん集まった表(これを行列と言います)」全体を、まるで「一つのもの」として扱えるようにする魔法の道具なんです。
「写真(という巨大な表) + 10」
こんな風に、たくさんの数字の集まりを「まるごと」操作するためのルールや技術、それが線形代数のパワフルなところです。
なぜ「Python」で学ぶの? コンピュータに計算させるメリット
さて、先ほどの写真の例で、なんとなくイメージが湧いたかもしれません。
線形代数が扱うのは「たくさんの数字の集まり」です。
もし、これをすべて「手計算」でやろうとしたら、どうなるでしょう?
例えば、3マス x 3マスの表(9個の数字)くらいなら、紙と鉛筆でも頑張れるかもしれません。
でも、実際の写真データは1000マス x 1000マス(100万個の数字)だったりします。
これを手計算するのは、絶対に不可能です!
そこで登場するのが、コンピュータ、特に「Python(パイソン)」というプログラミング言語です。
Pythonがなぜ良いのでしょうか?
それは、Pythonには「Numpy(ナンパイ)」という、線形代数の計算をめちゃくちゃ高速に、そして簡単に実行してくれる「魔法の道具箱(ライブラリと呼ばれます)」が用意されているからです。
Numpyを使えば、さっきの「100万個の数字すべてに10を足す」なんていう命令も、たった一行で、しかも一瞬で終わらせてくれます。
私たちが学ぶべきことは、面倒な手計算の方法を暗記することではありません。
「こういうことがしたい」(例:写真を明るくしたい)という目的を、Python (Numpy) が理解できる言葉(コード)で「指示」してあげること、ただそれだけです。
人間は「概念」を理解することに集中し、面倒な計算はすべてコンピュータに任せる。
これが、現代においてPythonで線形代数を学ぶ最大のメリットです!
準備運動:PythonとNumpyのセットアップ
「よーし、じゃあそのPythonとNumpyを準備しなきゃ!」
...と意気込むと、最初の「環境構築(かんきょうこうちく)」という壁にぶつかることがあります。
自分のパソコンで動くように設定するのが、意外と初心者には難しいのです。
ですが、安心してください。
今は、その面倒な作業をすべてスキップできる、素晴らしいサービスがあります。
その名も「Google Colaboratory(グーグル・コラボラトリー)」です。
(よく「Colab(コラボ)」と呼ばれます)
これはGoogleが提供しているサービスで、Webブラウザ(いつもインターネットを見ているソフト)さえあれば、Googleのアカウント(Gmailなど)を使って、すぐにPythonを動かすことができます。
素晴らしいことに、Pythonも、先ほど紹介した「Numpy」も、最初からすべて使える状態になっています。
面倒なインストール作業は一切不要!
あなたは、Google Colabを開いて、すぐに学習をスタートできるのです。
第1章のまとめ
お疲れ様でした!
まずはウォーミングアップ完了です。
- 線形代数とは?「まっすぐ」な関係を扱う数学で、「数字の表(行列)」をまるごと操作する技術。
- なぜPython (Numpy)?人間は「何がしたいか」に集中し、面倒な「手計算」はコンピュータに任せるため。
- 準備は?「Google Colab」を使えば、今すぐゼロ円でスタートできる!
これで、線形代数を学ぶ「理由」と「道具」が揃いました。
次回、第2章では、いよいよ線形代数の主役である「ベクトル」と「行列」という「数字の箱」を、実際にPython (Numpy) を使って作ってみましょう!
お楽しみに。
Pythonでデータを「箱」に入れる魔法 - ベクトルと行列の世界
こんにちは。ゆうせいです。
第1章では、「なぜ線形代数をPythonで学ぶのか?」というお話をしましたね。
面倒な計算はコンピュータに任せて、私たちは「何をしたいか」という本質を理解しよう!という内容でした。
さて、第2章の今回は、いよいよ線形代数の主役が登場します。
それは、データを効率よく扱うための「魔法の箱」...
そう、「ベクトル」と「行列(ぎょうれつ)」です!
「名前は聞いたことあるけど、一体なんなの?」
大丈夫です。この2つが何者で、どうやってPythonで作り出すのかを、一緒に見ていきましょう!
「ベクトル」って何?
まず、「ベクトル」から始めましょう。
みなさんは「ベクトル」と聞くと、何を想像しますか?
物理の授業で出てきた「向きと大きさを持つ矢印」を思い出すかもしれません。
それも正解です!
ですが、データサイエンスやプログラミングの世界では、もう少し広く「いくつかの数字が、順番に並んだ『かたまり』」のことをベクトルと呼びます。
例えば、ある人の「身長」と「体重」をセットで扱いたいとき。
[170, 65]
このように、カンマで区切ってカッコでくくった数字の並び。これがベクトルです。
「あれ? ただ数字が並んでるだけ?」
はい、見た目はそれだけです。
でも、この「セットにする」というのが重要なんです。
(専門用語解説:「スカラー」との違いは?)
ここで「スカラー」という言葉も覚えておきましょう。
「スカラー」とは、単なる「1個」の数字のことです。
例えば「気温25度」の「25」だけならスカラーです。
それに対して「ベクトル」は、複数の数字の「集まり」です。
「今日の天気データ」として [25, 60] (気温25度、湿度60%)とセットにした瞬間に、それはベクトルになります。
スカラーは「点」、ベクトルは「矢印」や「座標」と考えると分かりやすいかもしれませんね。
Python (Numpy) でベクトルを作ってみよう!
では、この「ベクトル」という箱を、Pythonで作ってみましょう!
ここで、第1章でお話しした魔法の道具箱、「Numpy(ナンパイ)」を使います。
まず、PythonのプログラムでNumpyを使えるように、「おまじない」の言葉を書きます。
これは、Numpyを使うときは必ず最初に書くものだと思ってください。
import numpy as np
(これは、「numpyという道具箱を、これからは np というあだ名で呼びますよ」という宣言です)
この1行を書いたら、さっそくベクトルを作ってみます。
例えば、[1, 2, 3] というベクトルを作ってみましょう。
import numpy as np
# [1, 2, 3] というベクトルを作る
my_vector = np.array([1, 2, 3])
# 中身を見てみる
print(my_vector)
これを実行すると、[1 2 3] と表示されるはずです。
たったこれだけ!
np.array() という命令を使って、カッコ [] で囲んだ数字のリストを渡すだけ。
簡単だと思いませんか?
このようにNumpyで作ったベクトルのことを、Numpyの用語では「1次元配列(1-dimensional array)」と呼びます。
「配列」とは「ものがズラッと並んだもの」という意味ですね。
「行列」って何?
ベクトルが「数字の1列の並び」だと分かりました。
では、次なる主役「行列(ぎょうれつ)」とは何でしょうか?
もう想像がついているかもしれませんね。
行列とは、「ベクトルが、さらにいくつか集まって『表』になったもの」です。
そう、まさにエクセルのシートや、学校のクラスの成績一覧表のような「タテとヨコ」に数字が並んだもの、それが「行列」です。
第1章で例に出した、写真のピクセル(画素)データも、数字がタテ・ヨコにびっしり並んだ「行列」の代表例ですね。
例えば、2人の生徒の「身長」と「体重」をまとめた表を考えてみましょう。
- Aさん: [170, 65]
- Bさん: [155, 50]
この2つのベクトルを、そのまま合体させて...
[[170, 65],
[155, 50]]
このように2段に重ねたもの。これが行列です!
(専門用語解説:「行」と「列」を間違えないで!)
行列を扱うとき、絶対に知っておかないといけない言葉が2つあります。
それは「行(ぎょう)」と「列(れつ)」です。
- 行:横方向の並びのことです。(Aさんのデータ、Bさんのデータ)
- 列:縦方向の並びのことです。(身長のデータ、体重のデータ)
この例の行列は、「2行2列」の行列と呼びます。
(横に2段、縦に2列だからですね)
この「行」と「列」は、今後ずっと使いますから、しっかり覚えてくださいね!
Python (Numpy) で行列を作ってみよう!
行列の作り方も、Numpyを使えばベクトルのときとほとんど同じです。
先ほどの「2行2列」の行列を作ってみましょう。
作り方は「ベクトルのリスト(配列)」を、さらに np.array() で囲むイメージです。
import numpy as np
# [[170, 65], [155, 50]] という行列を作る
my_matrix = np.array([[170, 65], [155, 50]])
# 中身を見てみる
print(my_matrix)
これを実行すると、
[[170 65]
[155 50]]
このように、ちゃんと「表」の形で表示されます。
これも簡単ですね!
Numpyの用語では、このような行列のことを「2次元配列(2-dimensional array)」と呼びます。
タテ(行)とヨコ(列)という「2つの次元」を持つからですね。
(ちなみに、ベクトルは「1次元配列」でした。ヨコに並んでいるだけ、という1つの次元しか持たないからです)
第2章のまとめ
お疲れ様でした!
今日は、線形代数が扱う「データを入れる箱」について学びました。
- スカラー:ただの1個の数字。(例:25)
- ベクトル(1次元配列):数字が1列に並んだ「かたまり」。(例:[170, 65])
- 行列(2次元配列):ベクトルがいくつか集まって「表」になったもの。(例:[[170, 65], [155, 50]])
そして、これらはすべてPython (Numpy) の np.array() という命令で簡単に作れることも分かりましたね。
「箱」の作り方がわかったら、次は何をしたくなりますか?
そう、その「箱」を使って、何か計算をしてみたくなりますよね!
次回、第3章では、いよいよこれらのベクトルや行列を「動かす」方法、つまり「四則演算(足し算や掛け算)」について学んでいきます。
お楽しみに!
Numpyでラクラク計算!ベクトルと行列を「動かす」四則演算
こんにちは。ゆうせいです。
第2章では、線形代数の主役である「ベクトル(1次元配列)」と「行列(2次元配列)」という、データを入れる「箱」の作り方を学びましたね。
np.array() を使って、Numpyで自由に箱を作れるようになったかと思います。
さて、箱を作ったからには、その箱を使って何かしたいですよね?
そこで第3章の今回は、いよいよこれらのベクトルや行列を「動かしてみます」。
つまり、足したり、引いたり、掛けたりする「演算」のルールを、Python (Numpy) のコードと一緒に見ていきましょう!
一番カンタン! 足し算と引き算
まずは一番直感的で簡単な、足し算と引き算です。
行列やベクトルの足し算・引き算には、一つだけルールがあります。
それは、「同じ形(サイズ)どうしでないと計算できない」ということです。
例えば、 2行2列の行列A と 2行2列の行列B があるとします。
この2つを足す場合、Numpyは「それぞれの同じ位置にある要素」どうしを足し算します。
- Aの「1行目・1列目」 + Bの「1行目・1列目」
- Aの「1行目・2列目」 + Bの「1行目・2列目」
- ...
という具合です。
まるで、同じ形のExcelシートを2枚ピッタリ重ねて、同じセルの数字を足していくようなイメージですね。
Python (Numpy) での書き方は、驚くほど簡単です。
普通に + や - を使うだけ!
import numpy as np
# 2x2の行列A
A = np.array([[1, 2], [3, 4]])
# 2x2の行列B
B = np.array([[10, 20], [30, 40]])
# 足し算
print("A + B =")
print(A + B)
# 引き算
print("A - B =")
print(A - B)
これを実行すると、こうなります。
A + B =
[[11 22]
[33 44]]
A - B =
[[-9 -18]
[-27 -36]]
ちゃんと、同じ位置の要素どうしが計算されていますね!
データを一気に拡大・縮小!「スカラー倍」
次は「スカラー倍」です。
「スカラー」という言葉、覚えていますか?
第2章でやりましたね。スカラーとは「単なる1個の数字」のことでした。
「スカラー倍」とは、行列(またはベクトル)の「すべての要素」を、ある1個の数字(スカラー)で掛け算することを言います。
第1章で「写真(という行列)の明るさを一斉に変える」という話をしましたが、あれがまさにスカラー倍のイメージです。
これもNumpyなら超簡単。
普通に * (アスタリスク) を使って、行列に1個の数字を掛けるだけです。
import numpy as np
A = np.array([[1, 2], [3, 4]])
# 行列Aを「10倍」してみる
print("A * 10 =")
print(A * 10)
実行結果:
A * 10 =
[[10 20]
[30 40]]
一瞬で、すべての要素が10倍されました!
最大の山場?「行列の積」
さあ、ここが第3章のハイライトであり、線形代数が少し難しく感じられる最初のポイント、「行列の積(せき)」です。
ここで注意してほしいことがあります!
先ほどの足し算やスカラー倍と違い、「行列」と「行列」の掛け算は、単純に「同じ位置の要素どうしを掛ける」のとは、まったく違う特別な計算ルールになっているんです。
「え、なんでそんな面倒なルールがあるの?」
それは、この「行列の積」という操作が、AIや3Dグラフィックスなどで「データを変形させる(回転させたり、拡大縮小したりする)」という、とても重要な役割を持っているからです。
手計算の方法は、ここではあえて説明しません。
なぜなら、Numpyが全部やってくれるからです!
私たちは、「行列の積」を実行したいときに、Numpyのどの命令を使えばいいかだけ知っていればOKです。
その命令とは np.dot() です。(ドット、と読みます)
import numpy as np
A = np.array([[1, 2], [3, 4]])
B = np.array([[5, 6], [7, 8]])
# 行列A と 行列B の「積」を計算する
print("np.dot(A, B) =")
print(np.dot(A, B))
実行結果:
np.dot(A, B) =
[[19 22]
[43 50]]
[[1 * 5 + 2 * 7, 1 * 6 + 2 * 8], [3 * 5 + 4 * 7, 3 * 6 + 4 * 8]] という複雑な計算(今は覚えなくてOK!)の結果が、一瞬で出てきました。
!超重要:初心者がハマるワナ!
もし、
np.dot(A, B)ではなく、A * Bと書いてしまったらどうなるでしょう?A * B は、Numpyでは「同じ位置の要素どうしを掛ける」計算になってしまいます。
これは数学的な「行列の積」とは別物です!
行列どうしの掛け算(積)をしたい時は、必ず np.dot() を使う!
これだけは、しっかり覚えてくださいね。
知っておくと便利!特別な行列たち
最後に、これからの計算でよく登場する「特別な行列」を2つ紹介します。
1. 転置行列(てんちぎょうれつ)
「転置」とは、行列の「行」と「列」を、そっくり入れ替える操作のことです。
(2行3列の行列は、転置すると3行2列になります)
Numpyでは、行列のあとに .T (ピリオドとT) を付けるだけで、一瞬で転置できます。
import numpy as np
A = np.array([[1, 2, 3], [4, 5, 6]]) # 2行3列
print("A =")
print(A)
print("A.T = (Aの転置)")
print(A.T) # 3行2列になる
実行結果:
A =
[[1 2 3]
[4 5 6]]
A.T = (Aの転置)
[[1 4]
[2 5]
[3 6]]
タテとヨコが入れ替わりましたね!
2. 単位行列(たんいぎょうれつ)
「単位行列」とは、普通の数字でいう「1」のような存在です。
普通の計算では、どんな数字に「1」を掛けても、答えは変わりませんよね?(例: 5 x 1 = 5)
行列の世界にも、それと同じ役割の行列があり、それを「単位行列」と呼びます。
特徴は、対角線上に「1」が並び、それ以外はすべて「0」であることです。
Numpyでは np.eye() (アイ = 目) という命令で作れます。
import numpy as np
# 3x3の単位行列を作る
I = np.eye(3)
print("I =")
print(I)実行結果:
I =
[[1. 0. 0.]
[0. 1. 0.]
[0. 0. 1.]]
(1. のように . が付いているのは「小数」という意味ですが、今は気にしなくてOKです)
第3章のまとめ
お疲れ様でした!
今日は、行列を「動かす」基本的な方法を学びました。
- 足し算・引き算:
A + B(形が同じである必要あり) - スカラー倍:
A * 10(全要素が10倍される) - 行列の積:
np.dot(A, B)(特別な計算ルール。A * Bとは違う!) - 転置行列:
A.T(行と列を入れ替える) - 単位行列:
np.eye(3)(掛け算しても相手を変えない、数字の「1」のような行列)
特に「行列の積」が、手計算とは比べ物にならないほどNumpyで簡単に実行できることが分かったと思います。
さて、道具は揃いました。
次回、第4章では、これらの計算ルールを使って、中学・高校時代に苦戦したかもしれない「連立方程式」を、行列を使って超スマートに解く方法に挑戦します!
お楽しみに。
あの面倒な計算がスッキリ!連立方程式を行列で解く「逆行列」
こんにちは。ゆうせいです。
第3章では、Numpyを使って行列の足し算や掛け算(特に np.dot() が重要でしたね!)といった「演算」の方法を学びました。
道具の使い方はバッチリですね!
さて、計算ルールを学んだら、それを使って何か「意味のあること」をしたくなりますよね?
そこで第4章の今回は、私たちが中学・高校で(もしかすると少し苦戦したかもしれない)「連立方程式」を、行列を使って超スマートに解く方法をご紹介します。
これぞ、線形代数のパワーが実感できる、最初のハイライトです!
懐かしの「連立方程式」、覚えてますか?
こんな問題、見覚えがありませんか?
「2x + y = 4」
「x + 3y = 7」
「このときの x と yの値を求めなさい」
昔は「代入法」とか「加減法」とか言って、片方の式を y = .. の形に変形してもう片方に入れたり、式どうしを足したり引いたりして、 x や y を一つずつ消していく... という、ちょっと面倒なパズルを解いていましたよね。
もちろん、それでも解けます。
でも、もしこれが x, y, zの3つになったら?
a, b, c, d, e の5つだったら...?
考えるだけで頭が痛くなりそうです。
線形代数は、この連立方程式を、もっと「機械的」に、そして「美しく」解くための道具を提供してくれます。
連立方程式を「行列の言葉」で書き直す
カギは、この連立方程式を、第2章・第3章で学んだ「行列」と「ベクトル」の形に書き換えることです。
先ほどの2つの式を、よーく見てください。
登場人物は、「x と y に掛かっている数字(係数)」、「x と y という変数」、「イコールの右側にある数字」の3グループに分けられますよね。
- 係数のグループA:[[2, 1], [1, 3]]
- 変数のグループx:[[x], [y]]
- 結果のグループb:[[4], [7]]
さあ、ここで第3章で学んだ「行列の積(np.dot())」を思い出してください。
もし、係数A と 変数x の行列の積 np.dot(A, x) を計算したら、どうなりますか?
[[2*x + 1*y],
[1*x + 3*y]]
...あれ?
これって、元の連立方程式の「左側」とまったく同じ形だと思いませんか?
つまり、あの連立方程式は、
A $\cdot$ x = b
(行列A と ベクトルx の積が、ベクトルb に等しい)
という、たった1行の「行列の方程式」で表現できてしまうんです!
カギは、この連立方程式を、第2章・第3章で学んだ「行列」と「ベクトル」の形に書き換えることです。 先ほどの2つの式を、よーく見てください。 登場人物は、「
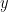
係数のグループ 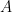

変数のグループ 

結果のグループ 

さあ、ここで第3章で学んだ「行列の積(


...あれ? これって、元の連立方程式の「左側」とまったく同じ形だと思いませんか? つまり、あの連立方程式は、

(行列
割り算の代わり?「逆行列」という魔法
この形まで来れば、ゴールはもうすぐです。 私たちが知りたいのは 
言い換えると、「
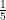
行列の世界にも、これとそっくりな考え方があります。 それが「逆行列(ぎゃくぎょうれつ)」です!
「逆行列」とは、元の行列 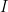
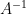

この逆行列 

やりました! つまり、私たちが欲しかった答え

という計算で求められることが分かりました。
Pythonにおまかせ!一発で解を求める
「ちょっと待って! 逆行列 A^{-1} とか、どうやって計算するの? そっちの方が面倒くさそう!」
その通りです。
逆行列を手計算で求めるのは、連立方程式をそのまま解くより、何倍も何十倍も面倒です。
ですが、思い出してください。私たちは何のためにPython (Numpy) を使っているんでしたっけ?
そう、「面倒な計算は、すべてコンピュータに任せるため」ですよね!
Numpyには、この A \cdot x = b の形の方程式を、一発で解いてくれる超便利な命令が用意されています。
それは np.linalg.solve() です!
(linalg は "Linear Algebra" = 線形代数の略、solve は「解く」です。そのまんまですね!)
使い方は、信じられないほど簡単です。
import numpy as np
# 係数行列 A
A = np.array([[2, 1], [1, 3]])
# 結果のベクトル b
# (Numpyは賢いので、[4, 7]と1次元で書いてもOK)
b = np.array([4, 7])
# これだけで、連立方程式 A * x = b を解いてくれる!
x = np.linalg.solve(A, b)
print("解 (xとyの値) =")
print(x)これを実行すると、どうなるでしょう?
解 (xとyの値) =
[1. 2.]
...出ました!
これは [x の値, y の値] というベクトルを意味しています。
つまり、「x = 1」「y = 2」という答えを、Numpyが一瞬で叩き出してくれたのです!


確かに合っていますね!
第4章のまとめ
お疲れ様でした!
今回は、線形代数の強力な「応用例」を体験しました。
- 連立方程式は、A $\cdot$ x = b という行列の方程式で書ける。
- この方程式は、「逆行列」 $A^{-1}$ を使えば、x = $A^{-1} \cdot$ b として解ける。
- でも、逆行列の手計算は地獄...。
- だからPython (Numpy) を使う!
np.linalg.solve(A, b)と書くだけで、一瞬で答えxが手に入る!
どんなに複雑な連立方程式も、この np.linalg.solve() に放り込んでしまえば、コンピュータが正確に解いてくれます。
これが、数学の理論とプログラミングが組み合わさったときの、すさまじいパワーです。
さて、方程式が解けるようになりました。
次回、第5章では、いよいよ線形代数の「ラスボス」とも言える、AIやデータ分析の「本質」に迫る、超重要概念「固有値(こゆうち)」と「固有ベクトル(こゆうべくとる)」に挑戦します!
お楽しみに。
データの「本質」を見抜く力 - 固有値と固有ベクトルというラスボス
こんにちは。ゆうせいです。
ついに、このテキストの「ラスボス」とも言える章にたどり着きました!
第4章では、np.linalg.solve() を使って、面倒な連立方程式をPythonに解かせる方法を学びましたね。
今回、第5章で扱うのは、AIやデータサイエンスの世界で最も重要と言っても過言ではない、「固有値(こゆうち)」と「固有ベクトル(こゆうべくとる)」です。
「...名前からして、もう難しそう」
「ついに意味が分からない言葉が出てきた...」
大丈夫です!
この2つが「何者」で、「なぜAIや顔認識で大活躍しているのか」、その「本質的なイメージ」を掴むことが目標です。
複雑な数式はNumpyに任せて、私たちはその「心」を理解しにいきましょう!
固有値と固有ベクトルって、聞いたことありますか?
この2つの言葉は、行列と非常に深い関係があります。
まずは、この2つが「ペア」で使われる、ということを知っておいてください。
(専門用語解説:行列の「本当の姿」を暴くペア)
第3章で、行列は「データを変形させる(回転させたり、拡大縮小したりする)」役割がある、という話を少ししました。
例えば、ある行列Aは、「データを反時計回りに90度回転させる」という「性質」を持っているかもしれません。
ここで、行列Aに、いろんな方向のベクトルを掛け算(np.dot(A, v))してみることを想像してください。
ほとんどのベクトルは、元の方向とは「違う方向」にビュンと飛ばされてしまいます。
...ですが!
その行列Aにとって、ごく一部に「特別な方向」のベクトルが存在します。
その「特別なベクトル」にAを作用させても、なんと「方向が変わらない」のです!
ただ、そのベクトルの「大きさ(長さ)」だけが、ビュッと伸びたり、キュッと縮んだりするだけ...。
この、行列Aにとって「特別な方向」を示し、掛け算しても方向が変わらないベクトルのことを、「固有ベクトル (Eigenvector)」と呼びます。
そして、その固有ベクトルの「大きさが何倍になったか」を示す、「伸び縮みの倍率」のことを、「固有値 (Eigenvalue)」と呼びます。
- 固有ベクトル:その行列が持つ「特別な方向性」。
- 固有値:その「特別な方向」に、どれだけの影響力(伸び縮み)があるか。
固有値が「大きい」ほど、その固有ベクトルが示す方向は、その行列にとって「重要」で「影響力が強い」方向であることを意味します。
一体なんの役に立つの?
「方向が変わらないのが、そんなに偉いの?」
「それが顔認識とどう繋がるの?」
素晴らしい疑問です!
固有値と固有ベクトルがスゴイのは、「データの『本質』や『最も重要な特徴』を見つけ出す」ことができるからです。
(例え話:顔認識(主成分分析)への応用)
第1章で、写真は「数字の巨大な行列」だという話をしました。
では、「人間の顔」の写真だけを1000枚集めてきたら、どうなるでしょう?
それらの「顔データ」には、何か共通する「特徴」がありそうですよね。
- 「目の位置」
- 「鼻の形」
- 「輪郭」
...などです。
ただ、これらの特徴は無数にあり、どれが「顔」を「顔たらしめている」最も重要な特徴なのか、パッと見ではわかりません。
ここで、固有値・固有ベクトルの出番です。
(正確には「主成分分析(PCA)」という手法を使います)
集めた1000枚の顔データを巨大な行列として扱い、その「固有値」と「固有ベクトル」を計算します。
すると、何が起こるか...
- 固有値が大きい順に、顔の「最も重要な特徴のパターン」が「固有ベクトル」として取り出せるのです!
- 1番目の固有ベクトル(固有値が最大):顔の「最も大雑把な特徴」(例:全体の明るさや輪郭)
- 2番目の固有ベクトル:次に重要な特徴(例:目や鼻の位置関係)
- 3番目の固有ベクトル:...
- ...
- 100番目の固有ベクトル(固有値が小さい):すごく細かい特徴(例:肌の小さなシミ、ノイズ)
このようにして取り出された「顔の基本的な特徴ベクトル」のことを、その名も「固有の顔 (Eigenface)」と呼びます。
つまり、固有値・固有ベクトルを調べることで、たくさんの顔データの中から「『顔らしさ』を構成するメインパーツ」だけを抽出できるのです!
これにより、少ないデータ量で顔を表現したり(データ圧縮)、新しい顔写真が「誰」なのかを比較したり(顔認証)することが可能になります。
Pythonで固有値・固有ベクトルを求めてみよう!
さあ、この「固有値・固有ベクトル」という、行列に隠された「本質」を暴く計算...
もちろん、手計算でやろうとすると、大学の試験問題レベルの難解さです。
ですが、私たちにはNumpyがありますね!
Numpyには、これを一発で計算してくれる命令 np.linalg.eig() が用意されています。
(eig は Eigenvalue / Eigenvector の略です)
import numpy as np
# 2x2の簡単な行列Aを作ってみます
A = np.array([[4, 2],
[1, 3]])
# これだけで、固有値と固有ベクトルが計算できる!
eigenvalues, eigenvectors = np.linalg.eig(A)
print("Aの固有値 (Eigenvalues) =")
print(eigenvalues)
print("\nAの固有ベクトル (Eigenvectors) =")
print(eigenvectors)これを実行すると、こうなります。
Aの固有値 (Eigenvalues) =
[5. 2.]
Aの固有ベクトル (Eigenvectors) =
[[ 0.89442719 -0.70710678]
[ 0.4472136 0.70710678]]
(ちょっと見慣れない小数が出てきますが、気にしないでください)
これは、
- この行列Aには、2つの「固有値」があります。それは「5」と「2」です。
- 「5」に対応する「固有ベクトル」(特別な方向)は、
[0.894..., 0.447...]という方向です。 - 「2」に対応する「固有ベクトル」は、
[-0.707..., 0.707...]という方向です。
という意味になります。
(eigenvectors の行列は、「列」ごとに1つの固有ベクトルが入っていることに注意してください)
このように、どんなに複雑な行列でも、np.linalg.eig(A) と唱えるだけで、その行列が持つ「本質的な方向(固有ベクトル)」と「その方向の重要度(固有値)」を、瞬時に抜き出すことができるのです!
第5章のまとめ
お疲れ様でした!
ついにラスボスを倒しました!
- 固有ベクトル:行列が持つ「特別な方向」。作用させても方向が変わらない。
- 固有値:固有ベトルの「伸び縮みの倍率」。その方向の「重要度」や「影響力」を示す。
- なんの役に立つ?:データの「本質」や「最も重要な特徴」を見つけ出すことができる。(例:顔認識の「固有の顔」)
- Pythonでは?:手計算は不可能!
np.linalg.eig(A)を使えば一瞬で求まる。
この「固有値・固有ベクトル」という考え方は、データ分析、AI、画像処理、検索エンジン(Googleのページランク!)、量子力学に至るまで、科学のあらゆる分野で使われている、超・超・強力なツールです。
これで、Pythonで学ぶ線形代数の「核」となる部分は、すべて学び終えました!
次回、いよいよ最終章となる第6章では、このテキスト全体を振り返り、皆さんが「次」に何を学ぶべきか、その「未来へのロードマップ」を示して締めくくりたいと思います。
最後まで、よろしくお願いします!
ここからが本番!線形代数を「武器」にするための未来ロードマップ
こんにちは。ゆうせいです。
ついに、この「Pythonで学ぶ線形代数」シリーズの最終章、第6章へようこそ!
第1章で「線形代数って何?」というところから始まり、第5章では「固有値」というラスボスまで、本当にお疲れ様でした。
ここまでたどり着いたあなたは、
- ベクトルや行列という「箱」の作り方 (
np.array) - その「箱」を動かす計算ルール (
+,np.dot) - 方程式を解く魔法 (
np.linalg.solve) - データの「本質」を見抜く力 (
np.linalg.eig)
これら線形代数の「核」となる部分を、すべてPython (Numpy) で実行できるようになったはずです。
もうあなたは、立派な「線形代数をコードで操れる人」です!
この最終章では、このテキストで得た知識を「点」から「線」へ、そして「武器」へと変えていくための、次なるステップ(学習の指針)をお話しします。
6-1. 次に何を学ぶべきか?
Numpyで線形代数の「部品」の作り方を学びました。
次は、その部品を使って「完成品」を作るステップに進みましょう!
1. 主成分分析 (PCA) への挑戦
第5章で「固有の顔 (Eigenface)」という例え話をしました。
あの「データの最も重要な特徴を抽出する」という強力なテクニックは、「主成分分析(しゅせいぶんぶんせき / PCA: Principal Component Analysis)」と呼ばれる、れっきとしたデータ分析手法です。
これは、まさに「固有値・固有ベクトル」の計算をそのまま応用したものです!
「なぜ固有値・固有ベクトルを学ぶのか?」という問いに対する、最も直接的でパワフルな答えの一つが、このPCAです。
たくさんの特徴(例えば、身長、体重、年齢、血圧...など)を持つデータを、PCAを使って「最も重要な2つか3つの特徴」にギュッと圧縮することで、 データをグラフで可視化したり、AIの学習を高速化したりできます。
2. 機械学習ライブラリ「Scikit-learn」との連携
Numpyが、線形代数の計算を実行する「高性能エンジン」だとすれば、「Scikit-learn(サイキット・ラーン)」は、そのエンジンを積んだ「AI・機械学習用の完成車」のようなライブラリです。
例えば、先ほど紹介した「PCA」を実行したい!と思ったとき、
Numpyだけでやろうとすると、固有値・固有ベクトルを計算して、データを並べ替えて...と、第5章で学んだことを全部自分で組み立てる必要があります。
しかし、Scikit-learnを使えば、
from sklearn.decomposition import PCA
pca = PCA(n_components=2) # 「2つの主な特徴」に圧縮
pca.fit_transform(my_data)
...と、たったこれだけのコードで、PCAの実行からデータの変換まで、すべてを自動でやってくれます!
Numpyで「なぜそうなるのか(固有値)」という理論の裏側を理解し、Scikit-learnで「どう使うのか」という実践的なテクニックを学ぶ。
この両輪が揃うことで、あなたのスキルは一気にジャンプアップしますよ!
6-2. 数学とプログラミング、両方楽しむための心構え
「やっぱり数学は難しい...」
「コードは書けるけど、理論が...」
多くの人がこのジレンマに陥ります。
大切な心構えは、「どっちから始めてもいいし、行ったり来たりしていい」ということです。
- コードが動けばOK!数学的な証明が完璧にわからなくても、まずは np.linalg.solve で連立方程式が解けた!という「動いた!」の感動を大切にしてください。動かしてから「なんで解けたんだろう?」と理論に戻るのも、立派な学習です。
- 理論が分かればOK!「固有値って、データの『本質』のことなんだな」というイメージが掴めたら、Numpyの np.linalg.eig が、まるで「本質を見抜く魔法の杖」のように見えてきませんか?
数学(理論)は「なぜ」を、プログラミング(実践)は「どうやって」を教えてくれます。
両方を行ったり来たりしながら、ジグソーパズルを埋めるように理解を深めていくのが、一番楽しくて効率的な学び方です!
6-3. おすすめの学習リソース紹介
最後に、この次にあなたが手にとってみると良いかもしれない「地図」の例をいくつか紹介します。
- 専門書や技術書「Pythonによるデータ分析入門(オライリーの本)」などは、NumpyやPandas(Excelの表のようなデータを扱うライブラリ)のバイブルです。
- オンライン学習プラットフォームUdemy, Coursera, Progate, Schooなど、動画で「機械学習」や「データサイエンス」の入門講座を見てみると、今日まで学んだ線形代数が、Scikit-learnと一緒に「動いている」姿を見ることができます。
- Kaggle(カグル)などのデータ分析コンペいきなり参加しなくても、「他の人がどうやってデータを分析しているか」のコード(ノートブックと呼ばれます)を眺めるだけでも、NumpyやScikit-learnの「実践的な使い方」の宝庫です。
最後のメッセージ
全6章の旅、本当にお疲れ様でした!
「線形代数」という、AIやデータサイエンスの「土台」を支える最も重要な柱の一つを、あなたは手に入れました。
もう、あなたは「なんだか難しそうな数学」と怖気付いていた、第1章のあなたではありません。
np.array も np.dot も np.linalg.eig も、すべてはあなたの「道具箱」に入っています。
ぜひ、その道具を使いこなし、データを読み解き、新しい何かを創り出す「次のステップ」へ進んでいってください。
あなたのこれからの学びを、心から応援しています!