
アルゴリズムの改善(分割統治法)
 山崎講師
山崎講師ここでは、アルゴリズムの改善により高速化を目指す方法について解説します。
例として、挿入ソートとその応用であるシェルソートを取り上げます。また、再帰処理を使ったクイックソートやマージソートにも触れたあと、データ構造のヒープを使ったヒープソートを解説します。
挿入ソート
挿入ソート 【Insertion Sort】は、ソートアルゴリズムの一つです。整列された部分配列を順に増やしながら、未整列の部分配列の各要素を、整列された部分配列に適切な位置に挿入して行くことからこの名前があります。
具体的には、まず先頭から2つの要素を比較し、必要に応じて入れ替えます。その後、3つ目の要素を2つ目の要素と比較し、必要に応じて入れ替えます。これを配列の最後の要素まで繰り返し、最終的に整列された配列を得ることができます。
講師の説明を受けてあなたが他者にこのアルゴリズムを説明する準備を以下にしなさい。
| 5, 8, 3, 2 | 55, 34, 89, 13, 21 |
<サンプルプログラム>
import java.util.Arrays;
public class InsertionSort {
public static void main(String[] args) {
int[] data = { 5, 8, 3, 2 };
System.out.println("0回目の走査: " + Arrays.toString(data));
for (int i = 1; i < data.length; ++i) {
int key = data[i];
int j = i - 1;
while (j >= 0 && data[j] > key) {
data[j + 1] = data[j];
j = j - 1;
}
data[j + 1] = key;
System.out.println(i + "回目の走査: " + Arrays.toString(data));
}
}
}<実行結果>
| 0回目の走査: [5, 8, 3, 2] 1回目の走査: [5, 8, 3, 2] 2回目の走査: [3, 5, 8, 2] 3回目の走査: [2, 3, 5, 8] |
挿入ソートは、安定で実装が容易であるという特徴を持っています。しかし、配列の要素数が大きい場合や、逆順に並んだデータをソートする場合には、実行時間が長くなる傾向があります。また、最悪の場合の時間計算量が O(n^2) であるため、大きなデータセットを扱う場合には、他の高速なソートアルゴリズム、例えば次のシェルソートを使用することをお薦めします。
シェルソート
シェルソートは、挿入ソートを改良したアルゴリズムです。
挿入ソートは逆順に並んだデータをソートすることが苦手でした。しかし、ある程度並んでいる状態では高速なソートです。この点に着目したアルゴリズムがシェルソートです。具体的には、配列の要素を複数のグループに分割して、それぞれのグループに対して挿入ソートを適用します。
シェルソートは、「飛び飛びの列を繰り返しソートして、配列を大まかに整列された状態に近づけていく」ことにより、挿入ソートの長所を活かしたものである。
アルゴリズムの概略は次のとおりである。Wikipedia
- 適当な間隔 ℎ
を決める(hの決め方については後述)
- 間隔 ℎ
- 間隔 ℎ
- ℎ=1
になったら、最後に挿入ソートを適用して終了
講師の説明を受けてあなたが他者にこのアルゴリズムを説明する準備を以下にしなさい。
| 5, 8, 3, 2 | 55, 34, 89, 13, 21 |
<サンプルプログラム>
import java.util.Arrays;
public class ShellSort {
public static void main(String[] args) {
int[] data = { 5, 8, 3, 2 };
System.out.println(Arrays.toString(data) + " :整列前");
int n = data.length;
for (int gap = n / 2; gap > 0; gap /= 2) {
// ギャップの値に基づいて挿入ソートを実行
for (int i = gap; i < n; i += 1) {
int temp = data[i];
int j;
// ギャップを考慮して要素を並び替える
for (j = i; j >= gap && data[j - gap] > temp; j -= gap) {
data[j] = data[j - gap];
}
data[j] = temp;
}
System.out.println(Arrays.toString(data) + " :gap " + gap + " の途中経過");
}
System.out.println(Arrays.toString(data) + " :整列後");
}
}<出力結果>
| [5, 8, 3, 2] :整列前 [3, 2, 5, 8] :gap 2 の途中経過 [2, 3, 5, 8] :gap 1 の途中経過 [2, 3, 5, 8] :整列後 |
シェルソートには分割統治の考え方が反映されています。分割統治は、大きな問題を小さな複数の部分問題に分割し、それぞれを個別に解決することで全体の問題を解決する手法です。
シェルソートは、配列の要素を一定の間隔【gap】でグループに分割し、それぞれのグループに対して挿入ソートを適用することで、グループごとの小さな部分問題に分割しています。そして、ギャップを徐々に狭めながら、各グループのソートを繰り返すことで、最終的に全体の配列がソートされるのでした。
グループに分割することで、配列を小さな部分問題に分割し、それぞれを個別に解決することで、全体の問題である配列のソートを解決しています。
同様に分割統治の考え方を使い、さらに再帰処理と組み合わせているのがクイックソートやマージソートです。以下の問題で再帰処理について復習しておいてください。
練習問題
基本情報技術者試験 平成28年春期 午前問7

マージソート
マージソートは、分割統治法に基づくアルゴリズムで、効率的なソートアルゴリズムの1つです。マージソートは、分割統治法を用いた安定なソートアルゴリズムです。以下に手順を説明します。
基本的な手順は以下の通りである。
Wikipedia
- データ列を分割する(通常、二等分する)
- 分割された各データ列で、含まれるデータが1個ならそれを返し、2個以上ならステップ1から3を再帰的に適用してマージソートする
- 二つのソートされたデータ列(1個であればそれ自身)をマージする
以上がマージソートの手順です。マージソートはデータ列を再帰的に分割し、ソート済みのサブシーケンスをマージすることで最終的なソート結果を得ます。安定性と一貫した性能が特徴です。マージソートの計算量は、最悪の場合でもO(n log n)であり、安定的なソートアルゴリズムの1つとして広く利用されています。
マージソートの主な欠点は、追加のメモリスペースを必要とすることです。マージソートは、データの分割と結合を繰り返すため、追加の配列やリストが必要になります。これにより、ソートするデータのサイズが大きくなると、追加のメモリ使用量も増えます。この追加のメモリスペースの問題を解消するのが次のクイックソートです。
講師の説明を受けてあなたが他者にこのアルゴリズムを説明する準備を以下にしなさい。
| 5, 8, 3, 2 | 55, 34, 89, 13, 21 |
<サンプルプログラム>
import java.util.Arrays;
public class MergeSort {
private static int cnt;//マージ回数をカウントするための変数
public static void main(String[] args) {
int[] data = { 5, 8, 3, 2 };
mergeSort(data, 0, data.length - 1);
}
public static void mergeSort(int[] arr, int left, int right) {
if (left < right) {
int mid = (left + right) / 2;
// 左半分をソート
mergeSort(arr, left, mid);
// 右半分をソート
mergeSort(arr, mid + 1, right);
// 2つのソート済み配列をマージ
merge(arr, left, mid, right);
System.out.println(++cnt + " 回目のマージ結果: " + Arrays.toString(arr)); // 途中経過を表示
}
}
public static void merge(int[] arr, int left, int mid, int right) {
// 左半分の配列を一時的な配列にコピー
int[] leftArr = new int[mid - left + 1];
for (int i = 0; i < leftArr.length; i++) {
leftArr[i] = arr[left + i];
}
// 右半分の配列を一時的な配列にコピー
int[] rightArr = new int[right - mid];
for (int i = 0; i < rightArr.length; i++) {
rightArr[i] = arr[mid + 1 + i];
}
int i = 0; // 左半分の配列のカウンタ
int j = 0; // 右半分の配列のカウンタ
int k = left; // マージする配列のカウンタ
// 左半分と右半分を比較し、小さい方から順に配列に追加
while (i < leftArr.length && j < rightArr.length) {
if (leftArr[i] <= rightArr[j]) {
arr[k] = leftArr[i];
i++;
} else {
arr[k] = rightArr[j];
j++;
}
k++;
}
// 左半分の配列に要素が残っている場合、配列に追加
while (i < leftArr.length) {
arr[k] = leftArr[i];
i++;
k++;
}
// 右半分の配列に要素が残っている場合、配列に追加
while (j < rightArr.length) {
arr[k] = rightArr[j];
j++;
k++;
}
}
}<出力結果>
| 1 回目のマージ結果: [5, 8, 3, 2] 2 回目のマージ結果: [5, 8, 2, 3] 3 回目のマージ結果: [2, 3, 5, 8] |
クイックソート
クイックソートは、分割統治法を利用してリストをソートするアルゴリズムです。平均的なケースでは高速にソートすることができます。
以下は、クイックソートの基本的なアルゴリズムです。なお、今回はピボットとして左端の要素を選択していますが、中央の要素などそれ以外の要素を選択する方法もあります。なお、【pivot】とはコンパスなどの「回転軸」のことです。ピボットを軸として小さいデータと大きいデータを回転させるためこの名前があります。
クイックソートは以下の手順で行われる。
Wikipedia
- ピボットの選択:適当な値(ピボット(英語版)という)を境界値として選択する
- 配列の分割:ピボット未満の要素を配列の先頭側に集め、ピボット未満の要素のみを含む区間とそれ以外に分割する
- 再帰:分割された区間に対し、再びピボットの選択と分割を行う
- ソート終了:分割区間が整列済みなら再帰を打ち切る
以上がクイックソートの手順です。クイックソートは分割統治法を利用しており、ピボットを基準にデータを分割しながら再帰的にソートを進めることで高速なソートが実現されます。マージソートと違い、追加の配列を必要としませんのでスペース効率も高いです。
クイックソートのアルゴリズムを大まかに理解したかどうかを以下の問題でチェックしてください。
基本情報技術者試験 平成30年秋期 午前問6

講師の説明を受けてあなたが他者にこのアルゴリズムを説明する準備を以下にしなさい。
| 5, 8, 3, 2 | 55, 34, 89, 13, 21 |
<サンプルプログラム>
import java.util.Arrays;
public class QuickSort {
public static void main(String[] args) {
int[] data = { 5, 8, 3, 2 };
System.out.println("整列前: " + Arrays.toString(data));
quickSort(data, 0, data.length - 1);
System.out.println("整列後: " + Arrays.toString(data));
}
// クイックソートのメイン関数
public static void quickSort(int[] data, int low, int high) {
if (low < high) {
// ピボットの位置を取得
int pivotIndex = partition(data, low, high);
// ピボットの左側を再帰的にソート
quickSort(data, low, pivotIndex - 1);
// ピボットの右側を再帰的にソート
quickSort(data, pivotIndex + 1, high);
}
}
// パーティション関数
public static int partition(int[] data, int low, int high) {
// ピボットを左端に設定
int pivot = data[low];
// ピボットより小さい要素を左側に配置するためのインデックス
int i = low + 1;
for (int j = low + 1; j <= high; j++) {
if (data[j] < pivot) {
// 要素を交換して、小さい要素を左側に配置
swap(data, i, j);
i++;
}
}
// ピボットを正しい位置に配置
swap(data, low, i - 1);
return i - 1; // ピボットの位置を返す
}
// 要素を交換する関数
public static void swap(int[] data, int i, int j) {
int temp = data[i];
data[i] = data[j];
data[j] = temp;
}
}<出力結果>
| 整列前: [5, 8, 3, 2] 整列後: [2, 3, 5, 8] |
ヒープソート
ヒープソート【Heap Sort】は、ソートアルゴリズムの一種です。ヒープソートは、特に大規模なデータセットを効率的にソートするために使用されます。
ヒープソートでは、二分ヒープ【Binary Heap】と呼ばれるデータ構造を利用します。二分ヒープは、完全二分木(完全に埋まっている木構造で、最後のレベルを除いて左から右に詰められている)です。親と2つの子という同じ構造が繰り返されるため再帰と相性が良いです。ヒープは以下の性質を持ちます:
- 最大ヒープ(Max Heap)または最小ヒープ(Min Heap)という2つのバリエーションがあります。最大ヒープでは、親ノードの値が子ノードの値よりも大きくなるように、最小ヒープでは逆に親ノードの値が子ノードの値よりも小さくなるようにヒープが構築されます。
- 最大ヒープの場合、親ノードの値はその子ノードの値よりも常に大きくなります。つまり、任意のノードの値はその子ノードの値以下となります。最小ヒープの場合も同様ですが、親ノードの値はその子ノードの値よりも常に小さくなります。
- 二分ヒープは、一般的には配列を使用して表現されます。配列のインデックスを利用してヒープの各ノードを参照することができます。親ノードのインデックスと子ノードのインデックスの関係は、特定の計算式に従います。例えば、親ノードのインデックスがiの場合、左の子ノードのインデックスは2i+1、右の子ノードのインデックスは2i+2となります。
- ヒープソートでは、最初に与えられたデータ列をヒープとして構築します。その後、ヒープの最大(または最小)値を取り出してソート済みの部分列に追加します。ヒープから値を取り出した後は、ヒープの再構築が必要であり、再びヒープの性質を満たすように調整されます。この過程を繰り返し、全体がソートされるまで続けます。
ヒープソートの手順を説明します。
Wikipedia
- 未整列のリストから要素を取り出し、順にヒープに追加する。すべての要素を追加するまで繰り返し。
- ルート(最大値または最小値)を取り出し、整列済みリストに追加する。すべての要素を取り出すまで繰り返し。
データ構造のヒープを大まかに理解したかどうかを以下の問題でチェックしてください。
基本情報技術者平成20年秋期 午前問12
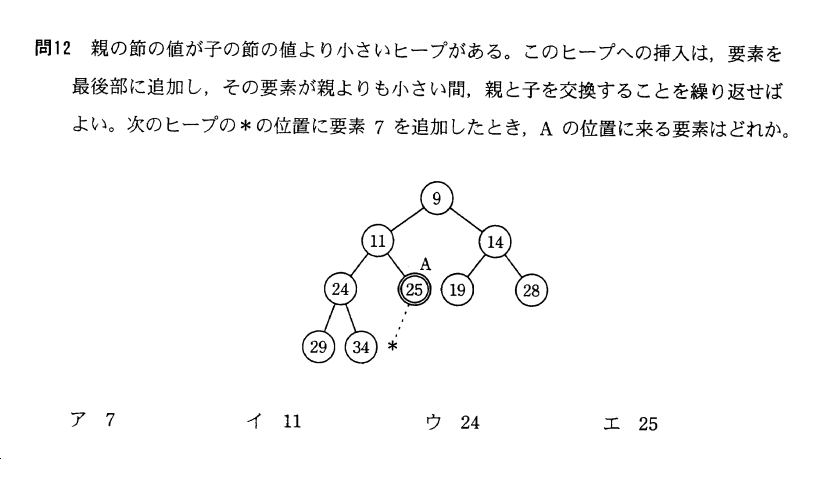
講師の説明を受けてあなたが他者にこのアルゴリズムを説明する準備を以下にしなさい。
import java.util.Arrays;
public class HeapSort {
private static int cnt;
public void heapSort(int arr[]) {
int n = arr.length;
// ヒープを構築する
for (int i = n / 2 - 1; i >= 0; i--)
heapify(arr, n, i);
// 配列の要素をヒープから1つずつ取り出してソートする
for (int i = n - 1; i > 0; i--) {
// 最大値を配列の末尾と交換する
int temp = arr[0];
arr[0] = arr[i];
arr[i] = temp;
// ヒープを再構築する
heapify(arr, i, 0);
System.out.println(Arrays.toString(arr) + " :" + ++cnt + "回目のヒープからの要素の取り出し"); // 途中経過を表示
}
}
// ヒープを構築するためのユーティリティメソッド
void heapify(int arr[], int n, int i) {
int largest = i; // 親ノードの位置
int left = 2 * i + 1; // 左の子ノードの位置
int right = 2 * i + 2; // 右の子ノードの位置
// 左の子ノードが親ノードより大きい場合
if (left < n && arr[left] > arr[largest])
largest = left;
// 右の子ノードが親ノードまたは左の子ノードより大きい場合
if (right < n && arr[right] > arr[largest])
largest = right;
// 最大値が親ノードでない場合、最大値と親ノードを交換し、再帰的にヒープを構築する
if (largest != i) {
int swap = arr[i];
arr[i] = arr[largest];
arr[largest] = swap;
heapify(arr, n, largest);
}
}
// テスト用のプログラム
public static void main(String args[]) {
int[] arr = { 5, 8, 3, 2 };
System.out.println(Arrays.toString(arr) + " :整列前");
HeapSort heapSort = new HeapSort();
heapSort.heapSort(arr);
}
}<出力結果>
| [5, 8, 3, 2] :整列前 [5, 2, 3, 8] :1回目のヒープからの要素の取り出し [3, 2, 5, 8] :2回目のヒープからの要素の取り出し [2, 3, 5, 8] :3回目のヒープからの要素の取り出し |
時間計算量
マージソート、クイックソート、ヒープソートの時間計算量はO(n log n)です。
O(n log n)のアルゴリズムは、全要素に対して処理を行う操作(統合またはマージ : n)と要素数を半分に分割する処理(分割 : log n)が組み合わさったものと言えます。
具体的な例として、マージソートやクイックソートを考えてみましょう。
マージソートでは、要素数を半分に分割して再帰的にソートを行い、最後にそれらをマージ(統合)する必要があります。要素数がnである場合、最初の分割操作ではn/2の要素数の2つの部分リストが得られます。その後、それぞれの部分リストに対して再帰的に同じ分割操作を繰り返し、最終的には1つの要素からなる部分リストが得られます。そして、それらを再び統合してソートされたリストを作成します。分割と統合の操作が繰り返されるため、計算量はO(n log n)となります。
クイックソートも同様に、要素数を分割し、それぞれの部分リストを再帰的にソートします。基準値(ピボット)を選び、リストを基準値より小さい要素のグループと大きい要素のグループに分割します。そして、それぞれのグループに対して再帰的に同じ操作を行い、最終的にはソートされたリストを得ます。分割操作が繰り返されるため、クイックソートの平均時間計算量はO(n log n)です。
投稿者プロフィール
- 代表取締役
-
セイ・コンサルティング・グループ株式会社代表取締役。
岐阜県出身。
海外放浪の末、2000年創業、2004年会社設立。
IT企業向け人材育成研修歴業界歴20年以上。
すべての無駄を省いた費用対効果の高い「筋肉質」な研修を提供します!
この記事に間違い等ありましたらぜひお知らせください。
学生時代は趣味と実益を兼ねてリゾートバイトにいそしむ。長野県白馬村に始まり、志賀高原でのスキーインストラクター、沖縄石垣島、北海道トマム。高じてオーストラリアのゴールドコーストでツアーガイドなど。現在は野菜作りにはまっている。

