
~大量のデータをまとめて効率よく処理を行う~
なぜ、配列の理解が重要なのか、その理由
この記事では、当社の新人エンジニア研修の参考にC#を解説します。
前回は「開発者の三種の神器② 繰り返し」について学びました。コンピュータの力を実感できたかと思います。
今回は配列について解説します。プログラマーの三種の神器の最後の要素です。
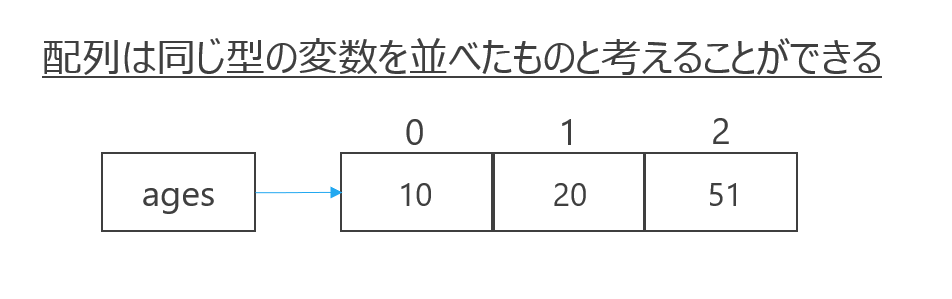
配列という言葉だけを見ると、なにやら得体のしれないものにも思えますが、簡単に言えば、大きな箱の中にいくつも小さな箱が入っていて、それぞれの箱に一つずつ情報が入るようになっているものです。たくさんの情報を、一つの変数に入れられるようになっているわけですね。
配列は、よく繰り返し処理と組み合わせて使われます。前章で、町内の子供たちにお菓子を配る処理の話が出てきましたが、ちょうどこの子供たちの情報を配列に入れておき、繰り返し処理で一人ずつ処理を行う、というような使われ方をするのです。
配列の中にある小さな箱には自動で名前が付くことになっており、その名前は、ゼロから始まる連番になります。なので、配列の中の最初の要素はゼロ番目の箱に、次の要素は1番目の箱に入っている、ということになります。この連番のことを、インデックス(又は添字:そえじ)と呼びます。
C#のような静的型付け言語の場合は、配列にも型があり、その配列にどんなデータ型の情報を入れるのかを、最初に宣言することになっています。
なので、配列を一言で表現すると、「同じ型の複数の要素を持つデータ構造」と言えます。
1. 配列の使い方
1) 配列を表す変数を宣言する
int[] ages;
int[]は「整数型(int)の配列」を表します。agesは「intの配列型」の変数名です(まだ要素は確保していない)。
データ型の後に、大括弧を書くことで、配列の意味になります。
2) 配列の要素を確保する
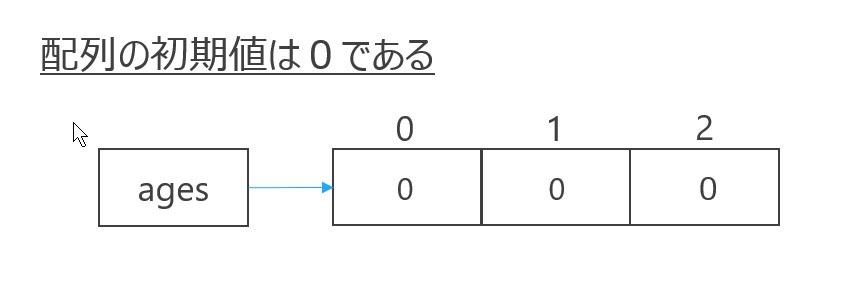
ages = new int[3];
new int[3]で「要素数3のint配列」をメモリ上に生成し、先頭のアドレスを返します。- この段階で
ages[0],ages[1],ages[2]が使えます(初期値は0)。
newという演算子が新しく出てきましたね。これはオブジェクトを新しくメモリ上に生成するときに使います。上記のコードは、int型の箱を三つ持つ配列をメモリ上に作り、その先頭アドレスをagesという変数に代入する、という処理です。
3) 添字(インデックス)を用いて要素に値を代入する
ages[0] = 10;
ages[1] = 20;
ages[2] = 51;
配列の連番(インデックス)は 0から開始 します。なので、連番の最大値は(要素数 - 1) になります。上の例では、ages[3]という箱は存在しませんので、注意してください。
4) 繰り返し構文を使って配列の要素を参照(読み出し)する
Console.WriteLine(ages[2]); // 51
ages[2] の値を取り出してコンソールに表示します。
サンプル:配列とfor文
namespace Chap07;
using System;
public class Example01 {
public static void Run() {
int[] ages;
ages = new int[3];
ages[0] = 10;
ages[1] = 20;
ages[2] = 51;
for (int i = 0; i < 3; i++) {
Console.WriteLine(ages[i]);
}
}
}
<実行結果>
| 10 20 51 |
この例では、int iをインデックスにして、3つの箱が持つ値を順に表示しています。
配列の長さ Length
C#ではages.Length と記述することで、配列の要素数(配列が持つ箱の数)を取得できます。この場合のLengthを、配列が持つ属性(プロパティ)と言います。プロパティとは、あるものが持っている性質や情報のことで、Length(長さ)は、配列の要素数という情報を指すわけです。
for (int i = 0; i < ages.Length; i++) {
Console.WriteLine(ages[i]);
}
Example01では、配列の要素数を3というリテラルで書いていますが、.Lengthを使えば、配列の要素数が増えても減っても、エラー無く全ての要素を表示してくれます。この3というリテラル数字のことを一般に、マジックナンバーと言います。数字だけでは意味が分かりづらいことから、こう呼ばれます。Lengthを使った書き方のことを、「マジックナンバーの回避」と言います。3を.Lengthに変えたことで、これは配列の要素数だ、と意味が明確な数値を使うことになり、マジックナンバーを使わないで済んだ、ということですね。
配列の初期化リテラル
配列を一度に初期化する方法もあります。
int[] ages = { 10, 20, 51 };
配列の要素を宣言時に初期化する場合は、中括弧(波括弧)の中に、各要素をカンマで区切って記述します。この場合、要素数は 3 と自動的に確定します。
2. IndexOutOfRangeException
C#で、存在しない配列要素を指定すると IndexOutOfRangeException が発生します。インデックス(添字)が、out of range (有効範囲外)ですよ、というエラーです。
int[] ages = new int[3];
ages[3] = 10; // 配列は要素数3なので、有効インデックスは0~2のみ
<実行時エラー>
| Unhandled exception. System.IndexOutOfRangeException: Index was outside the bounds of the array. |
C#のコンパイラは、このエラーをコンパイル時には検出してくれません。実行時にインデックスが不正と判明して初めてエラーが出ます。
3. 参照とメモリのイメージ
ここまで ages[0], ages[1] などの要素に実際のデータが入ることを学びました。では、ages 自体には何が入っているのでしょうか?いつものコマンドで見てみましょう。
C#ではオブジェクトや配列は“参照型”
int[] ages = new int[3];
Console.WriteLine(ages);
を実行すると、C#ではたとえば System.Int32[] のような型情報が表示されるでしょう(環境により異なりますが、System.Int32[] とか System.Int32[3] などと表示する場合もあります)。
この中身は配列オブジェクトへの参照です。
スタック領域とヒープ領域
- スタック領域に配列変数
agesが置かれる(内部にヒープ領域へのポインタ/参照を保持) - ヒープ領域に「要素数3のint配列」が確保される
agesは、ヒープ上にある配列オブジェクトを指し示す“参照”を保持しますages[0],ages[1],ages[2]はヒープ内に確保された実際のデータです
イメージ図(簡略化):
スタック領域はローカル変数やメソッドが格納される領域です。【stack】には英語で「積み重ねた」という意味があります。積み重ねられた本のように、後から入れたものが先に取り出される構造をしています【Last-In First-Out(LIFO)】。
ヒープ領域はインスタンスが格納される領域です。個人的には“インスタンス”領域と呼んでもいいと思うのですが、英語の【heap】に「山積み、山盛り」という意味があり、メモリ容量が大きくなる可能性があるインスタンスはこのヒープ領域に格納されるのです。
例えば、スタック領域に格納されるプリミティブ型のデータは大きくてもdouble型の64bitです。対して配列などのインスタンスはどれだけ大きくなるかわからないためヒープ領域に格納します。例えるなら、家具屋さんで、店頭にはカタログだけ用意して、大きな商品は倉庫に置いておくようなイメージでしょうか。

②メモリにはアドレスがあります。
ローカル変数に格納されるのは、配列が格納される予定のヒープ領域の先頭アドレス(ここでは15db9742)です。(下図参照)

③要素がヒープ領域に格納されます。(下図参照)

値型と参照型の違い
int,double,boolなどの組み込み値型はスタック上に直接データを保持します。- 配列やクラスのインスタンスは参照型となり、変数にはオブジェクトの参照(アドレス)が入ります。
4. 配列の要素をまとめて表示する
配列の全要素を一度に出力したいとき、C#では以下の2つの方法があります。
方法1:string.Join を使う
namespace Chap07;
using System;
public class Example02 {
public static void Run() {
int[] ages = { 10, 20, 51 };
// 文字列化して出力
Console.WriteLine(string.Join(", ", ages));
}
}
<実行結果>
| 10, 20, 51 |
string.Join は第1引数に区切り文字、第2引数に配列を渡すと「10, 20, 51」のような文字列を生成します。
方法2:foreach 文を使う
5. foreach 文
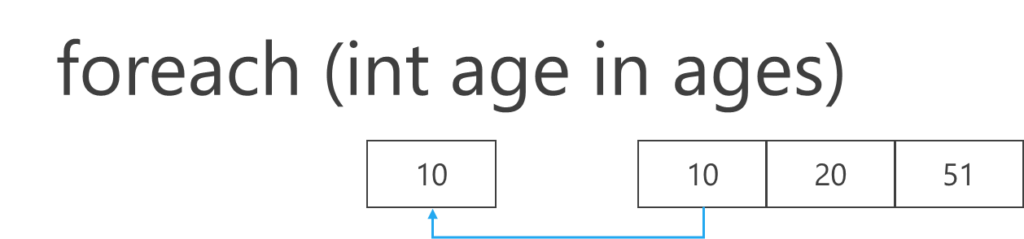
foreach 文は配列などの列挙可能なオブジェクトに対して、先頭から末尾まで自動で繰り返してくれます。
foreach (型 変数 in 配列)
namespace Chap07;
using System;
public class Example03 {
public static void Run() {
int[] ages = { 10, 20, 51 };
foreach (int age in ages) {
Console.WriteLine(age);
}
}
}
<実行結果>
| 10 20 51 |
foreach 文のイメージ
注意:age は「一時変数」
foreach (int age in ages) {
age *= 2;
}
このように一時変数ageに新たな値を代入しても、もとの配列内容は変わりません。C#では age は配列要素のコピーに過ぎず、配列自体の要素を書き換えているわけではありません。
- メリット: インデックス管理をせずに書けるため、
IndexOutOfRangeExceptionのリスク減 - 制限: 先頭から順にしか処理できず、要素を飛ばして走査したり、逆順で走査したりするには工夫が必要
- 適用範囲: 配列や
List<T>などのコレクションに対して使えます(コレクションは後述)。
6. 多次元配列(2次元配列の例)
C#でも2次元以上の多次元配列を扱うことができます。見た目は行列のようですが、実際はいくつかの方法があります。ここでは「配列の配列」(ジャグ配列)を紹介します。
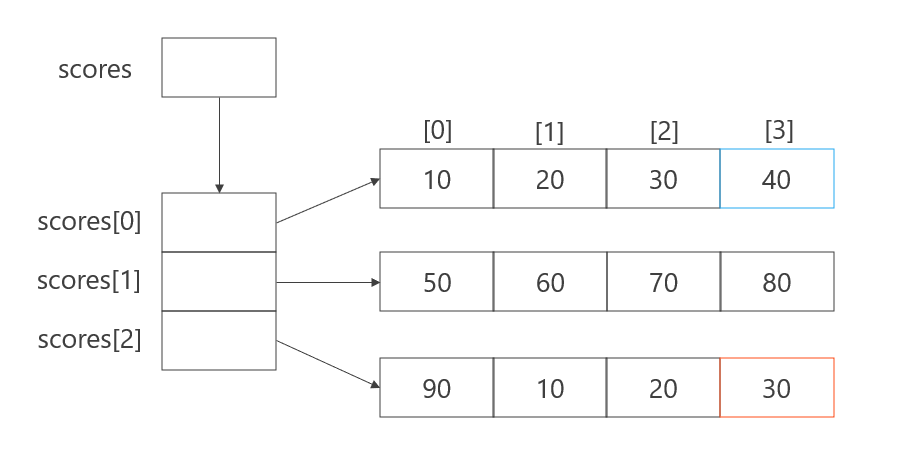
6-1. ジャグ配列(Jagged Array)
C#で int[][] scores = new int[][] { ... }; のように書くと「配列の配列」が作れます。長さの異なる配列を持つことも可能です。ジャグ配列といいます。
namespace Chap07;
using System;
public class Example04 {
public static void Run() {
int[][] scores = {
new int[] { 10, 20, 30, 40 },
new int[] { 50, 60, 70, 80 },
new int[] { 90, 10, 20, 30 }
};
Console.WriteLine(scores[0][3]); // 40
Console.WriteLine(scores[2][3]); // 30
// 二重の foreach
foreach (int[] row in scores) {
foreach (int val in row) {
Console.Write($"{val},");
}
}
}
}
<実行結果>
| 40 30 10,20,30,40,50,60,70,80,90,10,20,30, |
「配列の中にint[]を3個格納」しており、それぞれが4要素の配列を持っています。
7. 配列とオブジェクト指向
配列は非常に便利ですが、要素数を後から変更できないなどの制限があります。C#では可変長のコレクションとして List<T> などが用意されており、実務ではそちらを使う機会が多いでしょう。
例:配列で5名の生徒の成績を管理する
namespace Chap07;
using System;
public class Example05 {
public static void Run() {
int[] scores = { 80, 75, 100, 90, 80 };
string[] names = { "Tom", "John", "Mary", "Ken", "Jimmy" };
for (int i = 0; i < scores.Length; i++) {
Console.WriteLine($"{names[i]}'s score is {scores[i]}");
}
}
}<実行結果>
| Tom's score is 80 John's score is 75 Mary's score is 100 Ken's score is 90 Jimmy's score is 80 |
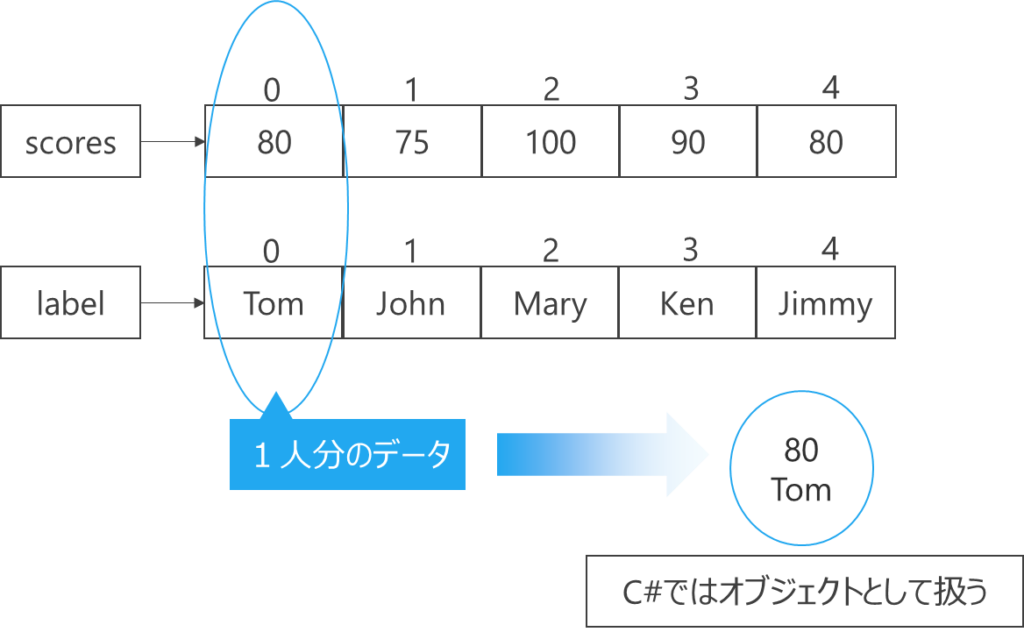
int型とString型のように違った型を1つのデータにまとめるにはどうしたら良いでしょうか?
古典的には以下のように「別々の配列」で同じインデックスを共有して表現していました。(インデックス0番の人の名前はTom、スコアは80点のように)
しかしオブジェクト指向(クラス設計)が普及してからは、1人分のデータを1つのオブジェクトとしてまとめるやり方が主流となっています。
イメージは下図の通りです。
8. 配列を便利にしたコレクション
大量のデータを扱う際、確かに配列は便利なのですが、配列はサイズが固定されています。そのため、データ数が事前に決まっていない場面では扱いづらく、要素を動的に増減したい場合には不便です。この問題を解決するのがListです。Listはサイズを自由に変更でき、型安全性も保ちつつ柔軟なデータ管理を実現します。
Listを宣言する場合、よく使われるのが以下の表記です。
List<T>
Listは、コレクションと呼ばれる配列の機能を拡張したクラスの一種です。<T>はジェネリクスと呼ばれる表記法で、Listに入れるデータ型を便利に指定できるようにするための表記法です。ジェネリクスを利用することで、要素の型をあらかじめ指定できるため、型安全で効率的な処理を実現します。型変換時のミスを防ぎ、コードの再利用性も高まるのです。以下、詳しく見ていきましょう。
9. List<T> とは
C#には、配列の機能を拡張して「オブジェクトや値をまとめる」ためのコレクションと呼ばれるデータ構造が多数あります。中でも定番なのがList<T>。これは「要素数を自動的に伸縮できる配列のようなもの」であり、便利なメソッドを持っています。
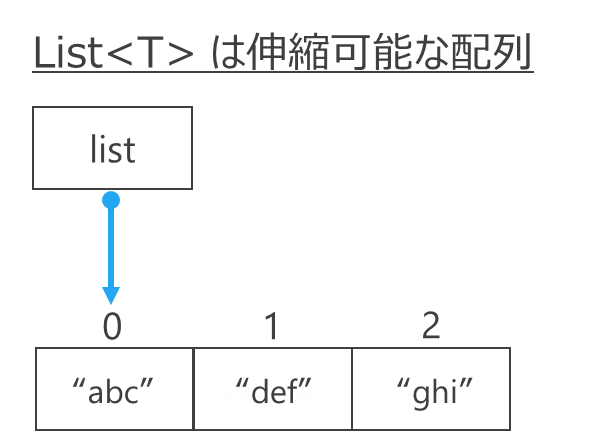
List<T>のイメージT は型パラメータと呼ばれ、Listに入れるデータの型を指定する表記です。これを「ジェネリクス」と呼びます)。下の例のように、List<string>と書けば、文字列を入れるListを作成します、という宣言になるわけです。
例: 文字列リスト
namespace Chap07;
using System;
using System.Collections.Generic;
public class Example06 {
public static void Run() {
List<string> list = new List<string>();
list.Add("abc");
list.Add("def");
list.Add("ghi");
Console.WriteLine(list[0]); // "abc"
}
}<実行結果>
| abc |
なぜ型パラメータが必要?
同じList<...>でも、格納する要素の型がどんな型かを指定しないとコンパイラが判断できません。誤った型を混在させることを防ぎ、型安全を確保するため、<T> で要素型を宣言します。
10. ジェネリクス(Generics)
C#では「ジェネリクス」という機能で「再利用可能な型引数つきのクラス・メソッド」を設計できます。List<T>はその代表例で、Tには参照型でも値型(intなど)でも指定可能です。
例: 整数型リスト
namespace Chap07;
using System;
using System.Collections.Generic;
public class Example07 {
public static void Run() {
List<int> list = new List<int>();
list.Add(1);
list.Add(2);
list.Add(3);
// 合計を求める
Console.WriteLine(list[0] + list[1] + list[2]); // 6
}
}11. LinkedList<T>との使い分け
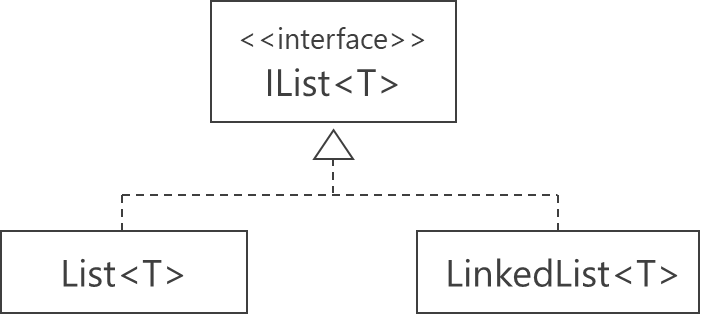
List<T>とLinkedList<T>の関係C#には LinkedList<T> という連結リスト構造もあります。LinkedList<T> はリスト先頭への要素の追加・削除が高速ですが、ランダムアクセスが遅いなど特徴があります。
List<T> は内部実装が配列の動的拡張であり、「先頭要素を削除」すると配列コピーが入るので遅め、逆に末尾への追加は高速、ランダムアクセスも高速です。
namespace Chap07;
using System;
using System.Collections.Generic;
using System.Diagnostics;
public class Example08 {
public static void Run() {
const int N = 10000;
// List<T>に1万件追加
var list1 = new List<int>();
for (int i = 0; i < N; i++) {
list1.Add(i);
}
var stopwatch = Stopwatch.StartNew();
// 先頭要素を連続削除
for (int i = 0; i < N/2; i++) {
list1.RemoveAt(0);
}
stopwatch.Stop();
Console.WriteLine($"List 先頭削除 {N/2}回: {stopwatch.ElapsedMilliseconds} ms");
// LinkedList<T>に1万件追加
var list2 = new LinkedList<int>(list1);
stopwatch.Restart();
// 先頭要素を連続削除
for (int i = 0; i < list2.Count/2; i++) {
list2.RemoveFirst();
}
stopwatch.Stop();
Console.WriteLine($"LinkedList 先頭削除 {N/2}回: {stopwatch.ElapsedMilliseconds} ms");
}
}実行すると、List<T>の先頭削除が遅い、LinkedList<T>は先頭削除は高速といった結果になる傾向があると思います。(環境によります)
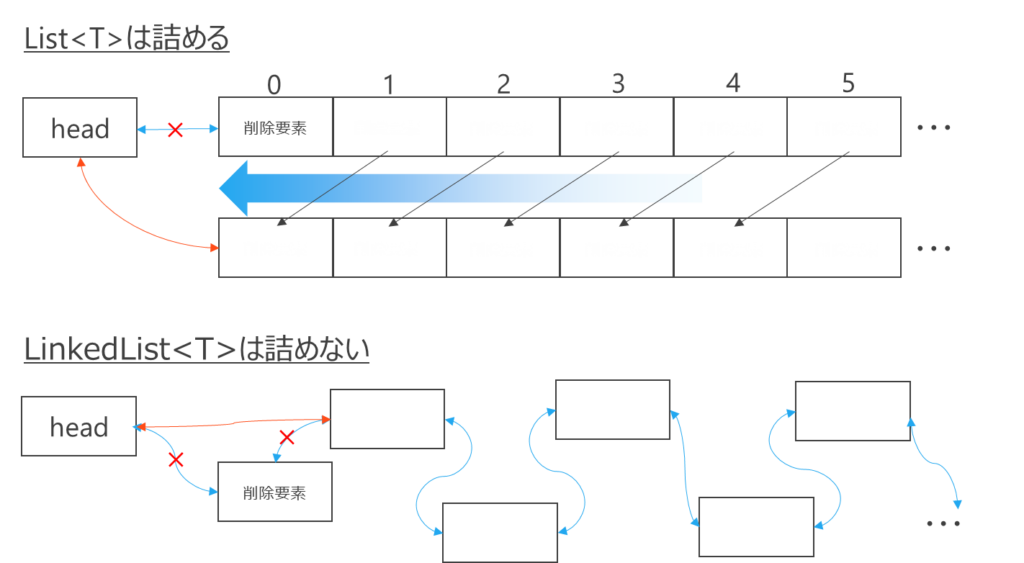
List<T>とLinkedList<T>の違いList<T>: ランダムアクセス高速 / 末尾追加高速 / 先頭削除・挿入遅めLinkedList<T>: 先頭・中間の削除・挿入が部分的に高速 / ランダムアクセス苦手
12. IList<T>やICollection<T>
C#のList<T>は「動的配列」の具象クラスですが、インターフェースとして IList<T> や ICollection<T> を使う場合があります。これは「柔軟に差し替えられるようにしたい」ときなどに便利です。
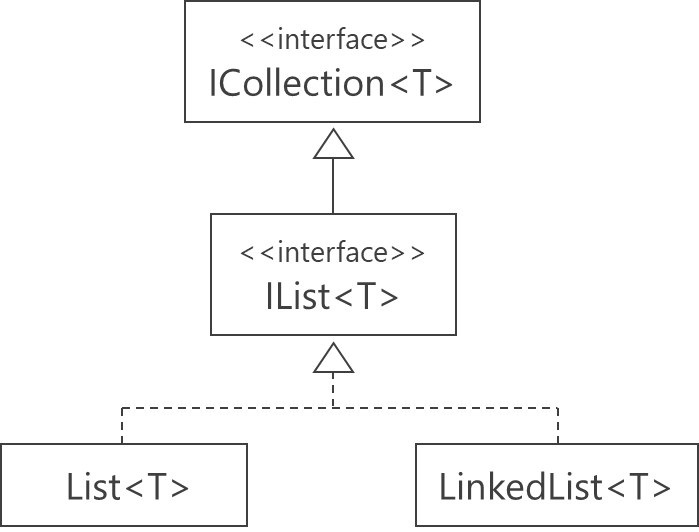
IList<string> list = new List<string>();
// あとで new LinkedList<string>() などに付け替えやすい
Removeメソッドを安全に使えるかどうかが異なります。
一般的には「コレクションをforeach中に変更しない」が原則で、変更したいなら別の方法(例えば forループ、または .Where(...) で抽出)を推奨します。
- C#のジェネリクスで
Tを指定することで、型安全かつパフォーマンス良くデータを扱える LinkedList<T>など他のコレクションもあり、用途に応じて使い分ける- インターフェース (
IList<T>など) で変数を宣言すれば差し替え可能 foreach中の要素削除は注意(InvalidOperationException)
これで、コレクションフレームワークの基礎が学べました。
C#でもList<T>を中心に覚えれば「要素数を動的に管理する」作りができ、ロジックを組む上で強力なツールとなります。追加でDictionary<TKey,TValue>, HashSet<T>など他のコレクションも学んでみるとさらに便利さが分かるでしょう。
次回は、「8章. オブジェクト指向基礎① 文字列を使いこなそう」を学びます。