
~スタック、ヒープ、スタティックの各領域と、値渡しと参照による値渡しを理解する~
なぜ、メモリ領域の理解が重要なのか、その理由
この記事では、当社の新人エンジニア研修の参考に C# を解説します。
前回は「 オブジェクト指向が生まれた理由」について学びました。オブジェクト指向が、様々なプログラマーの悩みを解消させるために生まれたこと、使い方を間違えなければ問題を軽減できる十分な可能性があることを理解しました。
今回はそのオブジェクトが、コンピュータのメモリをどのように利用して動作するのかを解説します。オブジェクト指向言語のアプリは、メモリをスタック領域、ヒープ領域、スタティック領域の三つに分けて使います。各領域はそれぞれ重要な役割を担っており、使われ方も全く違います。
皆さんが三つのメモリ領域の役割と動作を理解すれば、オブジェクト指向の奥深さに触れることになり、そしてそれは、オブジェクト指向を正しく使って、無駄無く高速でメンテナンス性も高いアプリケーションを開発するための確かな礎にもなるはずです。
まずは、各領域の概要からお話を始めたいと思います。メモリのお話は抽象的になりがちなので、図示できるものについては、なるべく図を挿入しています、よく見て理解してくださいね。
1. 三つのメモリ領域の概要
- スタック領域:次に実行される処理の場所やメソッドの引数と戻り値、ローカル変数などが置かれる
- ヒープ領域:new演算子で生成されたインスタンス(後述)が必要に応じて複数存在する
- スタティック領域:各クラスのインスタンス設計情報とスタティックメンバーが一つだけ存在する
いかがでしょうか。文章を読んだだけではイメージしづらいと思いますが、字面からも全く違う使われ方をしていそうだな、という印象を受けたのではないでしょうか。では、スタック領域から詳しく解説していきましょう。
2. スタック領域とは
動作の仕組みが複雑なので、初心者の方が一番躓きやすいのがスタック領域です。図で順を追って解説しますので、しっかりと付いてきてくださいね。
スタックは、他の二つの領域とは全く違う使われ方をする特殊な領域です。他の二つは言わばアプリケーションの部品が置かれる領域(詳細は後述)なのですが、それに対してスタックは、今の処理が終わったらどこに行くのか、呼び出すメソッドに何を渡すのか、また、そのメソッドが何を返したのか、といったアプリケーションの実行順序やメソッドの入出力を制御します。つまり、アプリケーションの動作の根幹を握る、大変重要な領域なのです。常に値が変動する、一番忙しく賑やかな鉄火場です。
スタックの仕組み
スタックでは、最後に入れたデータが最初に取り出されます。また、最初に入れたデータは最後に取り出される仕組みです。この仕組みを、FILO(First In, Last Out、先入れ後出し)とかLIFO(Last In, First Out、後入れ先出し)と呼びます。まずは、どうやってこんな仕組みを作っているのかを図を使って解説しましょう(実際にはもっと複雑なことをやっているのですが、スタックの概念を理解していただくために単純化していることをご了承ください)。
箱が地面からいくつも積みあがっている姿を想像してください。これが、スタック領域の模型です。次に、今どの箱を使っているかがわかるように、箱の横に矢印があるものと考えてください。矢印が指しているのが、現在使われている箱ということです。この矢印を、スタックポインタと呼びます。
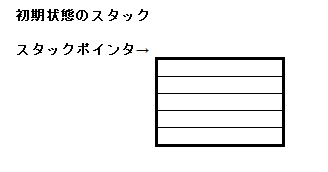
上図のような感じですね。箱の中は全部空で、矢印は何も無いところを指しています。
それでは、このスタックに一つデータを入れてみましょう説明を単純化するために、入れるデータは型や値など考えず、単に「データ1」としておきます。

最初の箱にデータ1が入り、矢印がその箱を指している状態になりました。
同じように「データ2」と「データ3」を追加すると、こうなります。

それでは、スタックからデータを一つ取り出してみましょう。
スタックからデータを取り出すときは、必ず矢印が指すデータが取り出されます。そして、スタックポインタは取り出したデータの一つ前に積まれたデータに移動します。

こういう仕組みなので、最初にスタックに積まれたデータ1を取り出せるのは最後になる、というわけです。
どうしてこんな変わった仕組みが必要なんだろうと、疑問を持たれた方も多いでしょう。実際のプログラム実行に沿ってスタックの動きを追ってみると、その理由がわかります。
メソッド呼び出しとスタックの動き
それでは、以下の単純なサンプルコードの動作に沿って、スタックの動きを追ってみましょう。
using System;
namespace Chap10 {
internal class Example01 {
// 挨拶相手名の配列
private static readonly string[] names = ["山崎", "今井", "山田", "田淵", "村田"];
// 挨拶文を引数にしてGreetを呼び出す
public static void Run() {
Greet("こんにちは");
}
// 挨拶文を相手の人数分繰り返し表示する
private static void Greet(string msg) {
for (int i = 0; i < names.Length; i++) {
string name = GetName(i);
Console.WriteLine($"{msg}、{name}さん");
}
}
// 挨拶相手の名前を返す
private static string GetName(int index) {
return names[index];
}
}
}
プログラムを起動すると、まずトップレベルステートメントからExample01クラスのRunメソッドが実行されます。
この時のスタックの状態は、以下のようになります。

Example01.Run()メソッド処理終了後の戻り先をスタックに積んでから、Example01.Run()を呼び出します。Example01.Run()メソッドでは、"こんにちは"という文字列を引数にして、Greet()を呼び出します。この時のスタックの状態は、下図の通りです。

Greet()処理終了後の戻り先と引数をスタックに積んで、Greet()を呼び出していますね。次に、Greet()の処理開始時のスタックはこうです。

Greet()は、引数にStringを一つもらうことになっていますので、スタックに積まれた引数を取り出してから処理を開始します。この時のスタックポインタが、Greet()処理終了後の戻り先の箱を指してることに注目してください。
Greet()処理終了後の戻り先とは、Runメソッドへの戻り先ということです。上記の例でいえば、12行目の処理( { しか書いてありませんが)のアドレスが入っているのです。
Greet()では最初にforループを実行しています。forループに入った直後のスタックの状態は以下の通りです。

繰り返し処理のカウンタとしてint型の変数 i が宣言されていますね。 ローカル変数はスタック内に作られますので、スタックの状態は上図のようになります。 int型の変数 i は、プリミティブ型ですので、スタック内に変数の実体(値)がある状態です。 次に、Greet()では挨拶相手の名前をもらうためにGetName()を呼び出しています。 この時のスタックの状態は以下の通りです。

Greet()内では、string型の name 変数を宣言してGetName()の戻り値を代入しています。 なので、まずはこのnameの領域がスタックに取られます。まだ名前をもらう前なので、nameの値はnullです。 次に、Run()からGreet()を呼んだときと同じように、GetName()処理後の戻り先をスタックに積みます。 最後に、GetName()に渡す引数(index)をスタックに積んで、GetName()を呼び出します。この引数は、ローカル変数 i の値をコピーしたものです。 GetName()に渡す引数は、ローカル変数 i と中身は同じですが、別の箱にコピーされて渡されることに注目です。
それでは、GetName()の処理終了時のスタックを見てみましょう。

GetName()の引数であるindexは、Greet()の処理開始時と同じように、スタックから取り出されます。 また、メソッドの処理開始時には戻り先のアドレスもスタックから取り出すことになっていますから、Greet()への戻り先もスタックからもらっておきます。 スタックポインタが上に2つ移動するわけですね。次に、Greet()に渡す戻り値の領域がスタックに確保され、文字列names[index] への参照がスタックにコピーされます。 Greet()の17行目では、string型の変数nameに、スタックにあるGetName()からの戻り値を取り出して代入します。
一人目の挨拶文を表示後、配列 names の要素数分だけ、4.と5.の処理が繰り返されます。
それでは次に、Greet()処理終了時のスタック領域を見てみましょう。

処理が完了したので、ローカル変数のint i と string name は破棄されてスタックポインタが2つ上に移動しています。 図を見ると、メソッドの処理終了時には処理の戻り先がスタックポインタが指す箱に必ず入っている状態ができるのだ、とわかりますね。同じように、Run()の処理終了後の戻り先が一つ上の箱に入っていますから、
Greet()終了→Run()終了→トップレベルステートメント終了
というように、順番に各メソッドの処理が終了し、その結果、アプリケーションの実行が完了するのです。
スタック領域の、この一風変わった仕組みは、
「あるメソッドの処理が終了する時には、自動的に次の戻り先がスタックポインタが指す箱に入っている」
という状態を作り出し、スムーズにメソッドの呼び出し処理が実行できるように考えられたものだ、ということがわかります。
スタックの実際の動作
スタック領域の仕組みが理解できたところで、もう少し踏み込んでスタックの動作を見てみましょう。先ほどの、スタックの模型を再掲します。
それではここで質問です。スタックに積まれる箱の大きさは、どのくらいだと思いますか?
実は、便宜上図のモデルでは箱の大きさを統一していますが、実際は積まれる値のバイト長によって一つ一つの箱の大きさも変わるのです。第1章でご紹介した組み込み型の表に、「参照」を追記して再掲します。
| 型 | ビット幅 | 値の範囲・内容 |
|---|---|---|
bool | — | true または false |
byte | 8ビット | 符号なし(※) / 符号あり sbyte が別にある |
char | 16ビット | Unicode 文字 (U+0000 ~ U+FFFF) |
short | 16ビット | -32768 ~ 32767 |
int | 32ビット | -2,147,483,648 ~ 2,147,483,647 |
long | 64ビット | -9,223,372,036,854,775,808 ~ 9,223,372,036,854,775,807 |
float | 32ビット | 単精度浮動小数点数(-3.4×10^38~3.4×10^38 など) |
double | 64ビット | 倍精度浮動小数点数(±5×10^-324~±1.7×10^308 など) |
decimal | 128ビット | 高精度(財務計算などで使用) |
| 参照 | 64ビット | 処理の戻り先とオブジェクトのアドレス |
最小が8ビット(1byte)、最大で128ビット(16byte)のデータが並んでいますね。なので、スタックにある箱の大きさは、最大16byteです。一番小さい箱はCPU側の都合で4byteになります。1byteのデータでも4byteの箱に入れるのです。メモリがもったいない気もしますが、これは64ビットCPUが持つレジスタという手の大きさが最小で4byteなので、1byteのデータを読み書きするよりも、4byteにしておいた方が高速に処理できる、というのが理由です。
参照が64ビットなのは、64ビットCPUが扱えるメモリの最大容量が64ビットだからです。参照とは要するに、オブジェクトが存在するメモリの位置(アドレス)のことなので、64ビットCPUの参照は自ずと64ビットになります。言い換えれば、64ビットCPUが扱えるメモリのアドレスは64ビット(8byte)で表せる範囲内の数値になるので、参照のデータ長も64ビット(8byte)になる、ということです。
大きさが違う値をスタックに出し入れできる仕組み
データ型によってサイズが違うのに、どうやって間違わずにスタックにデータの出し入れをしているんだろう、と疑問を持った方はいませんか?確かに不思議ですね。その答えは、「どの順番でどんなデータ型の値がスタックに入るかを、プログラム側が知っているから」です。
上でご紹介したスタックの動きをもう一度見てください。メソッドを呼ぶ時には、必ず戻り先アドレスをスタックにいれ、順番に引数を入れてから呼び出します。呼び出されたメソッドはスタックから自分がもらうデータ型の引数と戻り先のアドレスを順番にもらい、処理が終われば自分が返すデータ型の戻り値をスタックに入れて処理を戻します。つまり、プログラムがコンパイルされて実行された時点で、スタックにどの順番でどんなデータ型の値が入るのかもあらかじめ決まっているのです。処理側はそれを知っているので、順番とサイズを間違えずにスタックとデータのやりとりが出来る、というわけです。
値渡しと参照による値渡し
それではここで、次の質問です。C#のスタック領域全体のサイズはどのくらいだと思いますか?
実は、C#のスタック領域の総サイズは、デフォルトでは1M~2Mbyteしかありません。あまりの小ささにびっくりした方もいらっしゃるでしょう。それでもC#の開発陣がこれで十分だと判断したから、このサイズなのでしょう。
ある程度の規模のアプリケーションなら、日に何千回、何十万回とメソッドの呼び出しが繰り返されます。当然それに伴って様々な大量のデータがメソッド間でやりとりされます。それなのに、スタック領域がこんなに小さくてもちゃんと動作するのですから、よほどスタック領域をなるべく使わずに処理を進めるための工夫がきちんとされているのだろうな、と想像が付くと思います。
これまでちょくちょく出てきていた、「値渡し」と「参照による値渡し」が、まさにその工夫なのです。メソッド間のデータの受け渡しは基本的にはスタックを使って行われます。int型の数値であれば、たった4byteのサイズなので、スタックの箱に値をコピーして渡せば高速ですし、メモリの消費も少ないですよね。しかし、例えば2000文字以上ある小説の一話分の文字列をメソッドに渡す場合はどうでしょう。1Mbyteのスタックをたちまち使い切ってしまいます。しかも、そんな大容量のデータをスタックにいちいちコピーしていたら、メモリの消費量だけでなく、時間もかかってしまいます。なのでこういう場合はヒープに小説の文字列を置いておき、スタックには「あなたが欲しいデータはここだよ」と、ヒープ領域のアドレスだけをコピーして入れておく、というやり方をするのです。
この、int型の数値の扱いを「値渡し」、小説の一話の扱いを、「参照による値渡し」と呼びます。
なお、C#には構造体の参照を表すrefや、その参照を読み取り専用で渡すためのinという概念があり、この変数への参照そのものをメソッドに渡すやり方を「参照渡し」と呼びます。スタックに値と参照のどちらをコピーするか、という話とは別の概念になりますので、この章から先は「値渡し」「参照による値渡し」「参照渡し」を厳密に使い分けることにいたします。
C#の構造体は値渡し
ここで、「そういえばC#の組み込み型は構造体だから、組み込み型の変数は参照による値渡しなのか?」と思ったあなたは鋭いです。ですが、構造体は値渡しでメソッドとやりとりされる、というのが答えです。構造体のメンバのうち、スタックにコピーされるのは構造体が持つ変数の値だけなのです。構造体が持つメソッドなどは、その構造体の型に紐付いており、個々の構造体のインスタンスとは別の領域に一つだけ存在します(つまり構造体のインスタンスの実体はフィールド値だけになる= C等の手続き型言語のプリミティブ型と挙動も同じになる)。プログラムは自分がもらった構造体のメソッドがどこにあるかは知っているので、それを呼び出すことになっているのです。
これが、クラスより構造体を使った方が処理が早いと言われるゆえんでもあります。クラスのインスタンスはヒープ領域に生成されて不要になれば消去され、この生成と消去にもCPUパワーと時間がかかります。しかし、int型などの構造体は、ヒープを使わずスタックに入る時にはフィールドの値だけがコピーされ、ガベージコレクションも不要です。結果、クラスより構造体を使った方が高速に処理される、ということです。
値渡しと参照による値渡しを使う場合の注意点
では、値渡しと参照による値渡しの例で、注意点を探っていきましょう。各自実行結果を予想してみてください。
using System;
namespace Chap10 {
internal class Student {
/****************************
インスタンスメンバー
****************************/
// 名前
public string Name { get; set; }
// 年齢
public int Age { get; set; }
// コンストラクタ
public Student(string name, int age) {
Name = name;
Age = age;
}
// 年齢チェック
public bool isAdult() {
return ADULT_AGE <= Age;
}
// 自己紹介
public void Introduce() {
// スタティックメソッドにインスタンスフィールドを渡して自己紹介
DoIntroduce(Name, Age, isAdult());
}
/****************************
スタティックメンバー
****************************/
// 成人年齢の定数
public const int ADULT_AGE = 18;
// 自己紹介本体
public static void DoIntroduce(string name, int age, bool isAdult) {
string msg = $"私の名前は{name}です。\n{age}才の{AgeString(isAdult)}です。\n";
Console.WriteLine(msg);
}
// "成人" 又は "未成年" の文字列を返す
public static string AgeString(bool isAdult) {
return isAdult ? "成人" : "未成年";
}
}
}using System;
namespace Chap10 {
internal class Example02 {
public static void Run() {
// 年齢変数初期化
int age = 40;
// Studentのインスタンスを生成
Student st = new Student("今井", age);
// 一回目の自己紹介
st.Introduce();
// Studentの名前と、年齢変数を変更
ChangeValue(st, age);
// Studentインスタンスの年齢を変更
st.Age = age;
// 二回目の自己紹介
st.Introduce();
}
// Studentの名前と、年齢変数を変更してみる
private static void ChangeValue(Student st, int age) {
age = 50;
st.Name = "田淵";
}
}
}C#の参照渡しに関連する特別な修飾子
C#には、参照渡しに関連して、何かの参照や、その参照を読み取り専用で扱ったり、変更専用に扱ったりする特別なキーワードがあります。皆さんはすぐに使うことは無いかもしれませんが、先輩達が書いたコードには記述があるかもしれません。ここで軽く触れておきますので、頭の片隅にでも、置いておいて下さい。
| 修飾子 | 意味 | 用途 |
|---|---|---|
ref | 続くオブジェクトへの参照 | 読み出しと書き込み両方が可能 |
in | 読み取り専用で参照を渡す | 読み取り専用(変更不可) |
out | 要素変更のための参照を渡す | 書き込み専用(変更必須) |
スタックオーバーフロー(Stack Overflow)とは
いわゆる致命的なエラーの一種です。スタック領域のメモリが不足して、データがあふれ出してしまった(overflow)状態を指します。手続き型言語のアプリ開発ではよくあった緊急事態ですが、昨今の開発言語はスタックがあふれても暴走するようなことは殆どありません。歴史的にあまりにも有名なエラーでしたので、同名の問題解決相談サイトが今でも運営されています。皆さんも、エラー原因の検索で、お世話になることもあるかもしれませんね。
スタックトレースとは
さて、ここまで読んだ皆さんは、メソッドを呼び出すたびにスタックに戻り先が詰まれて行く、ということを理解しました。
ならば、エラー発生時のスタックを見れば、問題の処理がどんな経緯で実行されたのかを追えるのではないか、ということも想像できるのではないでしょうか。例外(エラー)が起こった時に出力されるスタックトレースというのは、文字通り、スタックの中を追いかけて出力される記録のことです。
スタックトレースの見方については、後述の例外の章で詳しく解説いたします。
2. スタティック領域とヒープ領域
それでは残り二つのメモリ領域について、詳しく見ていきましょう。スタティックとヒープは、どちらも生成されたオブジェクトが置かれる領域です。違うのは、スタティックがクラスオブジェクトの領域であるのに対し、ヒープはインスタンスと呼ばれるオブジェクトの領域であることです。
ここでの「クラス」は、オブジェクトの設計図を記述するクラスファイルとは違います。紛らわしいのですが、クラスファイルにはインスタンスに持たせるメンバーと、スタティック領域に構築されるオブジェクトのメンバー、両方が記述できるのです。
インスタンスメンバーとクラスメンバーの書き分けは簡単で、static宣言されたメンバーがクラスメンバーになります。まずは両領域の概要をご紹介します。
・スタティック領域
クラスでstatic宣言されている変数やメソッドと、インスタンス生成に必要な情報が一つだけ実体化する領域
一番静かで平和な領域です。
・ヒープ領域new演算子などで実体化したインスタンスが配置される領域です。newキーワードを使用すると、ヒープ領域に新たな領域が確保され、その領域にインスタンスが生成されるのです。
インスタンスは必要に応じて同じクラスからいくつでも複数生成されます。インスタンスが作られっぱなしでは、メモリがすぐ一杯になっていまいます。なので、使われなくなったインスタンスは自動的に消滅させられて、使っていたメモリが解放されます。この機能を、ガベージコレクション(GC)と呼びます。アプリケーションの構成にもよりますが、結構動きのある領域です。
クラスオブジェクトとインスタンスの違い
スタティック領域に生成されるクラスオブジェクトには、クラスファイルに記述された全ての要素が含まれています。と言っても、インスタンスメンバーの実体は含まれていません。クラスオブジェクトは、インスタンスを生成するための設計情報と、スタティックメンバーの実体で構成されているのです。つまり、new演算子などを使ってインスタンスを生成する際に、どんなメンバーを持たせてインスタンスを作るのか、という情報と、static宣言されたメンバーの実体を持つのがクラスオブジェクト、ということです。
クラスオブジェクトが持っているのはインスタンスの設計情報だけで、実体を持ってるわけではありませんから、インスタンスとしては機能しません。クラスのインスタンスメンバーは、実際にインスタンスを生成しない限りは使えないわけです。その代わり、実体化したスタティックメンバーは持っていますので、スタティックな情報やメソッドは利用できます。
逆に、インスタンスオブジェクトはインスタンスメンバーだけで構成されています。実体化したインスタンスのメンバーは、情報もメソッドも当然利用可能ですし、インスタンス内部からクラスメンバーにアクセスすることも可能です(詳細は後述)。
それでは実際にコードを追いながら、スタティックとヒープの動きを見てみましょう。
using System;
namespace Chap10 {
internal class Example03 {
public static void Run() {
Student st1 = new Student("川村武", 18);
Student st2 = new Student("大久保夏美", 17);
st1.Introduce();
st2.Introduce();
}
}
}using Chap10;
//Example01.Run();
Example02.Run();
Example03.RunメソッドでStudentクラスのインスタンスを2つ作り、それぞれの自己紹介で成人か未成年かを表示する、という簡単なアプリケーションです。アプリケーション起動直後の両領域は以下のようになります。
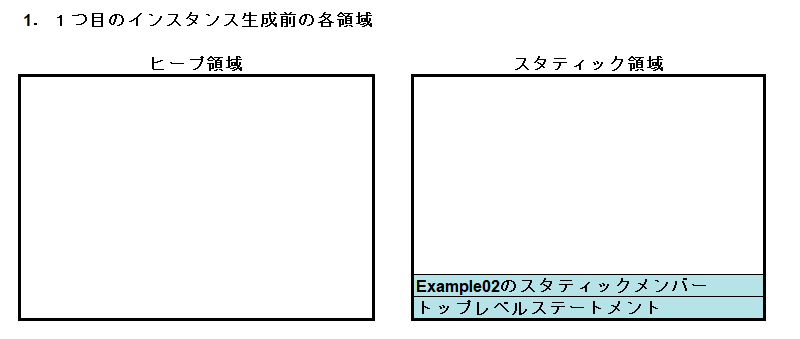
まだインスタンスは作られていませんので、ヒープ領域は空っぽです。
一方、スタティック領域には、トップレベルステートメントとExample02のスタティックメンバーがロードされています。
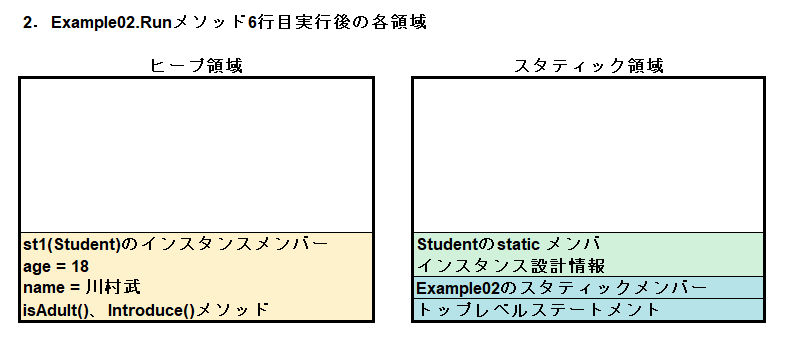
Runメソッド6行目でStudentのインスタンスを生成していますので、まずはスタティック領域にStudentクラスのインスタンス設計情報とstaticメンバがロードされます。その後、スタティックの設計情報を基にして、ヒープにst1用のインスタンスが一つ作られ、同時にst1という変数に、生成されたインスタンスの参照(アドレス)が入ります。
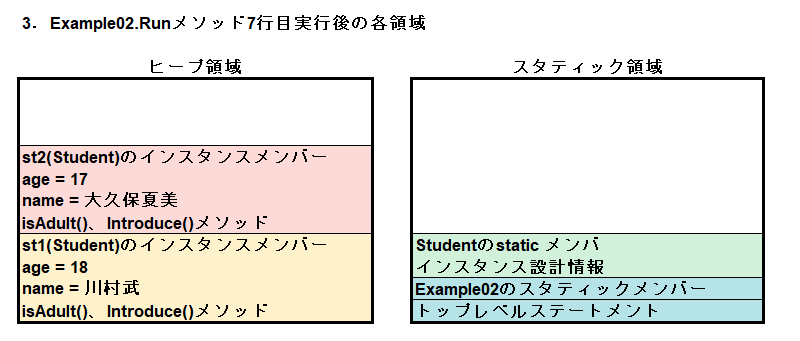
Runメソッド7行目が実行されると、st2用のStudentインスタンスがヒープに生成され、変数st2にその参照が代入されます。スタティック領域には変動はありません。
そして、9行目と10行目で、st1とst2の自己紹介処理が実行されます。
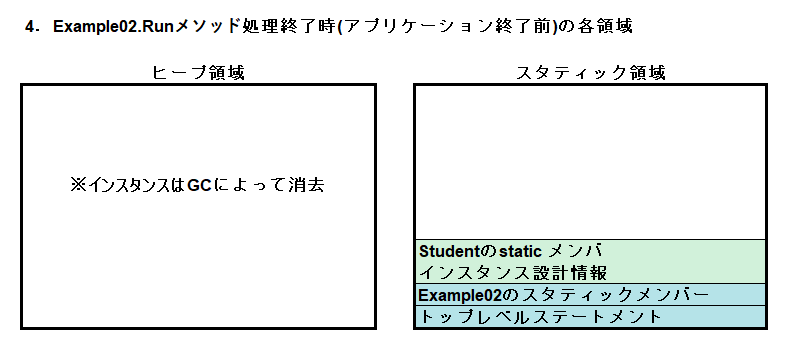
Runメソッドの処理が終了すると、ヒープのインスタンスはガベージコレクションによって消去されます。アプリケーションが終了していないので、やはりスタティック領域に変動はありません。
最後にアプリケーション終了時、ヒープとスタティック領域そのものが解放され、OSに返却されます。
スタティックメンバーからインスタンスメンバーを使うことはできない
初心者の方によくある勘違いが、同じクラスに書いてあるのだからと、スタティックメソッドからインスタンスフィールドを操作できると思い込んでしまうことです。インスタンスからスタティックメンバーは扱えますが、スタティックメンバーからインスタンスメンバーを扱うことはできません。
インスタンスからスタティックメンバーが扱えるのは、上記の例でもわかります。インスタンスメンバーであるIsAdult()メソッドで、スタティックフィールドのADULT_AGEを使えていますし、インスタンスメソッドであるIntroduce()は、スタティックメソッドのDoIntroduce()を呼び出せていますね。
しかし、スタティックメンバーからインスタンスメンバーを扱うことはできないのです。試しに以下のコードをStudent.csの45行目の下に追加してみてください。
public static void UnableToUse() {
Age = 20;
bool flag = isAdult();
}Age と isAdult()に、エラーを知らせる赤い波線が表示されましたね。
スタティックメンバーは、クラスが最初に使われた時にメモリにロードされます。ということは、インスタンスが生成された時には既にメモリにロードされていますから実体がありますし、スタティック領域に一つだけ存在するものなので、どのインスタンスからでもスタティックフィールドやスタティックメソッドがどれのことなのかを特定することができます。なので、インスタンスメンバーからスタティックメンバーを使うことが出来るのです。
しかし、前述のようにスタティック領域にあるクラスは、インスタンスの実体を持ちません。ですから、クラスメンバーからインスタンスのフィールドを扱おうとしても、そもそも存在しない物にアクセスしようとしているのと同じことになるのです。また、もしインスタンスが生成されていたとしても、スタティックメンバーからは、どのインスタンスのフィールドやメソッドを呼び出せば良いのかを特定出来ません。なので、スタティックメンバーからインスタンスメンバーを使うことはできないのです。
「静的でないフィールド、メソッド、又はプロパティ....オブジェクト参照が必要です」とエラーメッセージが出たら、この話を思い出してください。
スタティックメンバーとインスタンスメンバーの振り分け
ここで、インスタンスが持つべきメンバーと、スタティックが持つべきメンバーの振り分けを考えてみましょう。
まずは、どんなフィールド(情報)をインスタンスに持たせるべきでしょうか。インスタンスは、必要に応じていくつでもヒープ領域に生成されるオブジェクトです。ですから、インスタンス毎に違う値を持つフィールドはインスタンスメンバーにすべきです。ECサイトを例にとれば、会員名や住所、メールアドレスなどはインスタンスメンバーにするべきでしょう。
それに対して、成人年齢(18歳)のデータはインスタンス毎に変わりません。というよりも全インスタンス共通の値で、場合によって変わってもらっても困る情報です。このような値は、スタティックメンバーとして持つべきだ、ということです。上記の例でも、Studentのインスタンスは名前と年齢をフィールドに持っていますね。そして、成人年齢は定数として宣言されていますので、スタティックメンバーになっています(const宣言された定数は、static修飾子を使うことは出来ませんが、値を後から変更できないので、暗黙的にスタティックメンバーとなるのです)。
注意しなければならないのは、巨大なデータをインスタンスに持たすべきではない、ということです。そういう設計をしてしまうと、各インスタンスのサイズが膨れ上がって、メモリ不足による動作遅延などの問題が起こる危険性が高くなります。
ではメソッドはどうでしょう。インスタンスのフィールドを操作するようなメソッドは、当然インスタンスメンバーにした方が良い場合が多いでしょう。しかし、商品をカートに入れるメソッドは?カートの商品を決済するメソッドは?と考えていくと、判断が難しいですよね。
実は、メソッドを全てインスタンスメンバーにしたとしてもアプリケーションは動作はします。逆に、全メソッドをスタティックメンバーにすることも理論上は可能です。スタティックメンバーからインスタンスメンバーを直接操作はできませんが、スタティックメソッドがインスタンスの参照を引数に取れば、インスタンスフィールドを直接操作できるからです。しかしこれはオブジェクト指向のメリットを捨てることになるので、推奨はされません。
定石としては、複雑で容量が大きい処理をスタティックメンバーに持たせ、インスタンスから自身のフィールドを引数にしてスタティックメソッドを呼ぶように設計します。上記の例でも年齢チェックの処理本体はスタティックメンバーとして記述し、インスタンスの年齢チェックメソッドは自身のフィールド値を引数にして、スタティックな処理本体を呼び出すだけの小さいメソッドになっています。
C#ではインスタンスメソッドもスタティックメソッドと同じように一箇所にロードされ、全てのインスタンスで共有するので、巨大なインスタンスメソッドを作ったとしてもメモリを圧迫はしませんが、あまり大きなメソッドを作るとコードの可読性が悪くなります。
クラスにしてもメソッドにしても、読みづらくなるほど大きなサイズの物を作るべきではありません。どんなに複雑で多くのコードが必要な処理でも、適切に細分化して処理の流れを追いやすくし、可読性を上げる設計を目指しましょう。処理を適切に細分化することをブレイクダウンと呼び、これは設計段階の大変重要な要素です。
複雑でサイズが大きい処理はスタティックメンバーに持たせ、インスタンスはスタティックメソッドを呼び出すだけの軽い実装にする、という例はC#言語が用意する各種クラスでも用いられており、メソッドをインスタンスとスタティック、どちらに実装するかを考える上での指針になるでしょう。
適切なスタティックとインスタンスの使い分けを意識することで、堅牢で保守性の高いプログラムを作成できるようになります。
これで、オブジェクト指向の基礎講義を終わり、次回からはオブジェクト指向の三大要素の解説が始まります。
まず最初に、「11.オブジェクト指向の三大要素① カプセル化と情報隠蔽」を学びます。