
前回はER図からテーブルを作成する方法を解説しました。
今回は、MySQL Workbenchを使ってテーブルを検索する方法を解説します。
1. 検索の基本
SELECT文はテーブルからデータを抽出するための文です。
データベースの主な役割はデータの保存と検索です。そのため、データ操作言語【Data Manipulation Language:データ操作言語】の中でもSELECT文は最も重要です。
先に用意した下図のようなcars表に対してSELECT文を実行してみましょう。
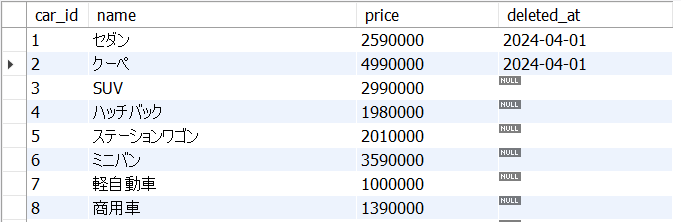
どの表からどんな列(フィールド)を取得するのかという文になっているので直感的にも分かりやすいと思います。また、この操作はリレーショナル・データベースの3種類の表操作のうち射影【projection】にあたります。
SELECT文の例文
SELECT name, price FROM sip_a.cars;<結果の例>
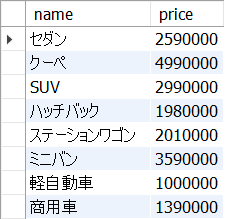
このようにSQL文の文末にはセミコロン(;)を付けます。このことは、新人エンジニアの皆さんが既に学んだJavaと同じですので馴染みやすいでしょう。
「sip_a.cars」という表記は「スキーマ名.テーブル名」という意味です。スキーマを選択済みであれば テーブル名だけにして「cars」 と書いても同じことでしたね。
また、以下5_2.sqlのようにキーワードの途中でなければ改行を入れて見やすくすることも可能です。
改行を入れて見やすくした例
SELECT
name, price
FROM
sip_a.cars;上記の結果はMySQL WorkbenchのBeautify Queryという機能で実現しました。下図のホウキのようなアイコンをクリック、または、ショートカットキー「Ctrl + B」でできますので積極的に活用しましょう。

全て小文字にした例
Javaとは違いSQLは大文字と小文字を区別しません。(Windowsの場合)
したがって以下5_3.sqlのように書いても同じ結果が得られます。しかし、すべて小文字は見にくくなりますので「SELECT」、「FROM」といったキーワードは大文字の方が良いでしょう。
select
name, price
from
sip_a.cars;また、以下5_4.sqlのように2つ目以降のフィールド名の先頭にカンマ( , )をつける書き方を好む人もいます。この書き方は、最後のフィールド名(下記5_4.sql でいえば「deleted_at」 )の後ろにカンマを付けてしまうミスを防ぐのに役立ちます。
SELECT
car_id
, name
, price
, deleted_at
FROM
sip_a.cars;
フィールド名等をスペルミスなく入力するにはEclipseのときと同様に「Ctrl + Space」でコード補完が使えます。
さらに、下図のColumnsの下からダブルクリックまたはドラッグ・アンド・ドロップでフィールド名やテーブル名を挿入できることを知っておくと良いでしょう。
コメントを入れてわかりやすくした例
なお、下図のようにコメントを入れることでSQLを分かりやすく説明することができます。
一行コメントは「--」、複数行コメントはJavaと同じ「/* */」です。
一行コメントのショートカットキーもJavaと同じですので講師に尋ねてください。

*を使って全てのフィールドを指定した例
最後に、よく使われる*(アスタリスク、英語圏では略称でスターとも呼ばれる)を使って全てのフィールドを指定する方法を5_5.sqlで見てみます。
SELECT
*
FROM
sip_a.cars;結果はご自身で確認ください。
このあと、Javaプログラムの中にSQL文を記述する方法も学ぶ予定です。その際、
「SELECT * FROM テーブル名」
のようにプログラムの中に"*"を書くことは一般的ではありません。
その理由は以下の2点です。
①テーブルの構造変更に弱くなる
②必要以上のデータを取得し、パフォーマンスが低下する
したがって、SELECTの後にはできるだけフィールド名を個別に記述すべきです。
ただし、この記事ではそのとき解説している論点を明確にしたいがために *を使っている場面があることを了解ください。
1.1. 検索の基本の例題
例題
cars表から、全てのレコードのcar_idとpriceを取得しなさい。
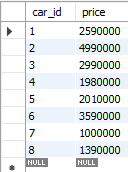
例題
cars表から、全てのレコードのnameとdeleted_atを取得しなさい。
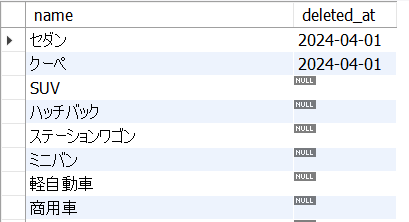
2. 条件付き検索
先のSELECT文では全てのレコードを抽出しました。WHERE句を使うと、特定の条件に一致するレコードのみを取得できます。条件式はJavaのif文と似ていますが、SQLでは比較演算子として=(イコール1つ)を使用する点が異なります。

ちなみに、英語の【where】に「~の場合には」という意味があります。(例.Where there's a will, there's a way.)
抽出条件はJavaでも学んだ条件式です。条件式は結果がTRUE又はFALSEに評価できるものでなければならなかったことを思い出してください。
なお、この操作はリレーショナル・データベースの3種類の表操作のうち選択【selection】にあたります。
2.1. 条件式の書き方
まずは、=を使って条件と等しいレコードを抽出してみます。(Javaとは異なり=は1つです)
5_6.sqlの通り数値の場合はクォーテーションマークで囲うことなく、そのまま書きます。
SELECT
name, deleted_at
FROM
cars
WHERE
car_id = 4;<結果の例>

以下の5_7.sql、5_8.sqlのように文字列や日時の場合はシングルクォート(')で囲みます。
SELECT
name, deleted_at
FROM
cars
WHERE
name = 'クーペ';<結果の例>

SELECT
name, deleted_at
FROM
cars
WHERE
deleted_at = '2024-04-01';<結果の例>

2.2. 算術演算子
Javaと同様の下表5.1の算術演算子が使えます。
Javaと異なる点は、割り算の際、4つの式の例はいずれも 0.5000 となるところです。
| 算術演算子 | 説明 | 式の例 | 例の結果 |
| + | 数値同士の加算 | SELECT 1 + 2 | 3 |
| - | 数値同士の減算 | SELECT 1 - 2 | -1 |
| * | 数値同士の掛け算 | SELECT 1 * 2 | 2 |
| / | 数値同士の割り算 | SELECT 1 / 2 SELECT 1 / 2.0 SELECT 1.0 / 2 SELECT 1.0 / 2.0 | 0.5000 |
以下5_9.sqlは、cars表からname,price,price*1.1を税込価格として全てのレコードを抽出します。
SELECT
name
,price
,price * 1.1
FROM
cars;<結果の例>
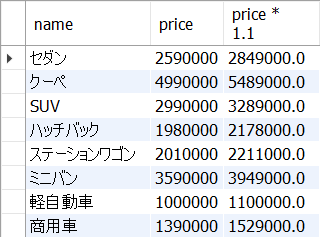
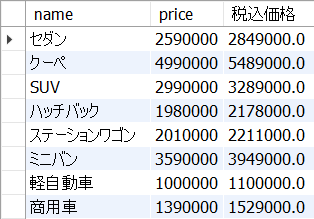
なお、以下5_10.sqlのようにprice * 1.1は税込価格という別名を付けて表示するとなお分りやすくなります。
別名をつける際にはAS句を使います。英語の【as】にはもともと「〜として(=イコールに近いニュアンス)」という意味があります。
SELECT
name
,price
,price * 1.1 as '税込価格'
FROM
cars;<結果の例>
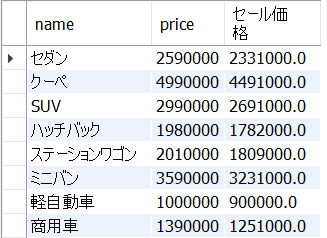
例題
cars表から、name、price、price*0.9をセール価格という別名で全てのレコードを取得しなさい。
2.3. 関係(比較)演算子1
Javaと同じように下表5.2のような演算子が使えます。
| 関係演算子 | 説明 | 式の例 | 例の結果 |
| = | 左辺と右辺が等しい | SELECT 1 = 1 | 1 (TRUE) |
| != または <> | 左辺と右辺が等しくない | SELECT 1 != 2 | 1 (TRUE) |
| > | 左辺が右辺より大きい | SELECT 1 > 2 | 0 (FALSE) |
| < | 左辺が右辺より小さい | SELECT 1 < 2 | 1 (TRUE) |
| >= | 左辺が右辺以上である | SELECT 1 >= 2 | 0 (FALSE) |
| <= | 左辺が右辺以下である | SELECT 1 <= 2 | 1 (TRUE) |
注意点としては、等しいがイコール1つであること。(Javaは==でした)等しくないは、 <> も使えることです(Javaは!=だけでした)。
例えば、以下の5_11.sqlは、 cars表からpriceが100万円のnameとpriceを抽出します。
SELECT
name, price
FROM
cars
WHERE
price = 1000000;<結果の例>

例題
cars表から、car_idが6以上のnameとpriceを取得しなさい。

例題
cars表から、priceが200万未満のidとname、priceを取得しなさい。
2.4. 関係(比較)演算子2
ここでは下表5.3を使ってJavaには存在しないSQL特有の関係演算子を見ていきます。
| 関係演算子 | 説明 | 句の例 |
| BETWEEN ~ AND | 値が値の範囲内に含まれているかどうかを確認します | WHERE price BETWEEN 1000000 AND 2000000; |
| IN | ある値が値セット内に含まれているかどうかを確認します | WHERE price IN (1000000 , 1980000); |
| IS NULL | NULLであるかどうかを確認します | WHERE deleted_at IS NULL; |
| LIKE | 文字列のパターン一致(あいまい検索)をします。 | WHERE name LIKE '%車'; |
なお、上記関係演算子はNOTをつけることで否定の意味になります。
具体的にはそれぞれ、「NOT BETWEEN ~ AND」,「NOT IN」 ,「IS NOT NULL」 ,「NOT LIKE」 です。
BETWEEN ~ AND を使ったSELECT文
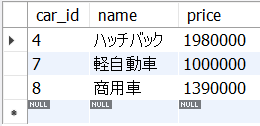
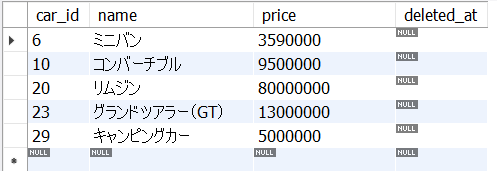
以下の5_12.sqlは、cars表からpriceが100万円以上200万円以下のcar_idとname, priceを抽出します。
SELECT
car_id, name, price
FROM
cars
WHERE
price BETWEEN 1000000 AND 2000000;<結果の例>
このとき100万の軽自動車が含まれていることに留意ください。もしも、未満や超過という抽出条件を記述したい場合には"<"や">"記号を使うしかありません。
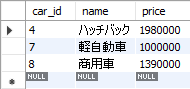
以下5_13.sqlのようにNOTを使うとpriceが100万円以上200万円以下でないnameとpriceを抽出します。
SELECT
car_id, name, price
FROM
cars
WHERE
price NOT BETWEEN 1000000 AND 2000000;<結果の例>

INを使ったSELECT文
次にINを使ってリストにある場合にデータを抽出する例を見ていきます。
以下5_14.sqlのSELECT文は、cars表からpriceが100万円 または 198万円のレコードを抽出します。
SELECT
*
FROM
cars
WHERE
price IN (1000000 , 1980000);<結果の例>

上記SQLは論理演算子のORを使って書き換えることもできますのでやってみてください。
| あなたの答え: |
しかし、条件が2つならまだしも、それ以上に増えてくるとあなたはこのINを使った書き方に感謝するでしょう。
IS NULLを使ったSELECT文
次に、IS NULLを使って空欄のあるデータだけを抽出してみます。
NULLとは未定義を意味する特別な値です。数値のゼロ(0)や文字列の空白とは違います。
NULLが存在するメリットとしては、例えば「銀行口座を開設したばかりで残高が未定義」なのか、それとも「0円」なのかを区別することができます。
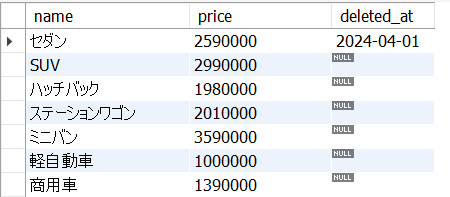
以下の5_15.sqlは、cars表からdeleted_atがNULL、すなわち販売中の車のname,とdeleted_atを抽出します。
SELECT
name, deleted_at
FROM
cars
WHERE
deleted_at IS NULL;<結果の例>
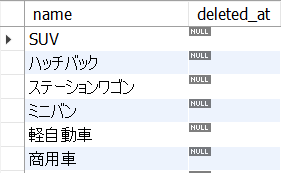
このとき初学者が犯しがちなミスは
WHERE deleted_at = NULL;
としてしまうことです。
NULLは未定義の値を表し、数値の0や空文字列とは異なります。そのため、NULLを比較する場合は IS NULL を使用し、 = NULL では比較できません。
NULL値と等しい値はありませんし NULL値との大小比較も無意味です。例えば、「SELECT NULL = NULL;」という文を実行すると結果はNULLとなり無意味です。
以下5_16.sqlは、cars表からdeleted_atがNULLでない、すなわち販売終了している車のname,とdeleted_atを抽出します。
SELECT
name, deleted_at
FROM
cars
WHERE
deleted_at IS NOT NULL;<結果の例>
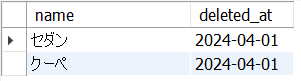
LIKEを使ったSELECT文
最後にこれも大変利用シーンの多いあいまい検索を解説します。LIKE演算子は、ワイルドカード(%や_)を使用して部分一致検索を行います。例えば name LIKE '%車' とすると「車」で終わるレコードを検索できます。
あいまい検索には以下のワイルドカードを使います。
「%」 :任意の文字列 (ゼロ文字を含む)
「_」 :任意の単一の文字
を意味します。

ワイルドカードとは、その名の通り「トランプのゲームでジョーカーが他のどのようなカードとも読み替え可能なこと」を考えるとイメージしやすいでしょう。
下表5.4に一覧にまとめます。
| 文字列 | 意味 | 該当する例 | 該当しない例 |
| a% | 「a」から始まる文字列 | art, autumn, Australia(※) | idea |
| %a% | 「a」 を含む文字列 | art, car, idea | book |
| %a | 「a」 で終わる文字列 | Australia, idea | art |
| a_ | 「a」から始まる2文字 | an | car |
| _a_ | 2文字目に「a」がある3文字 | car | art |
| __a | 「a」で終わる3文字 | era | art, car |
とくに、 「xxx」 を含む文字列 として %xxx% という表現は弊社の新人エンジニア研修でもよく使いますから押さえてください。
以下の5_17.sqlは、cars表から「車」で終わるレコードを抽出します。=ではなく「LIKE」を使うという点も間違えやすいので気をつけましょう。英語でも【She is like a flower.】のような表現がありましたね。
なお、今回指定している照合順序の「utf8mb4_unicode_520_ci」では、英字の大文字と小文字が区別されません。
SELECT
car_id, name, price
FROM
cars
WHERE
name LIKE '%車';<結果の例>
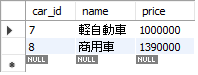
また、以下5_18.sqlのようにすると全てのレコードを抽出します。
この後、皆さんが作成するWebアプリケーションでも
%%の間にキーワードを入れて検索したら「あいまい検索」
%%の間にキーワードを入れずに検索したら「全件検索」
という場合によく使われますのでここでも解説しました。
SELECT
*
FROM
cars
WHERE
name LIKE '%%';例題
cars表から、以下のようにnameに「ー」が含まれるレコードのcar_id、name、priceを取得しなさい。

例題
cars表から、以下のようにdeleted_atが4月のレコードのnameとprice、deleted_atを抽出しなさい。

ワイルドカードの考え方はSQL以外の情報処理の世界でも使われるものです。新人エンジニアの皆さんは、ぜひ、この機会にマスターしてください。
2.5. 論理演算子
Java同様、SQLでも論理演算子を使うと複雑な条件式を組み合わせることができます。SQLの論理演算子はANDとORとNOTです。NOTはすでに見たのでANDとORについて確認しましょう。一般にAND条件は対象を絞り込むのに対して、OR条件は対象を広げましたね。
下表5.5を使いしばらく遠ざかっているJavaの復習もしておきましょう。
| 演算子 | 式がtrueになる条件 | 使用例 | Javaの場合(復習) |
| AND | 左辺と右辺の両方がtrue | WHERE name LIKE '%ン%' AND deleted_at IS NULL; | && |
| OR | すくなくとも左辺と右辺のどちらかがtrue | WHERE name LIKE '%ン%' OR deleted_at IS NULL; | || |
具体例を以下の5_19.sqlと5_20.sqlで見てみます。
SELECT
name, price, deleted_at
FROM
cars
WHERE
name LIKE '%ン%' AND deleted_at IS NULL;<結果の例>

SELECT
name, price, deleted_at
FROM
cars
WHERE
name LIKE '%ン%' OR deleted_at IS NULL;<結果の例>
上記例では2つの条件の組み合わせでしたが、3つ以上の条件を組み合わせることもできます。
例題を解いてみましょう。
例題
cars表から、販売中でかつpriceに1.1を掛けた値が230万円以上かつnameに「ン」が含まれるレコードのすべてのフィールドを抽出しなさい。
3つ以上の条件をつなげた際、AND条件はOR条件に優先します。ただし、丸括弧()で優先順位を変えられるのはJavaと同じです。
今回みたWHERE句を使った条件指定はUPDATE文やDELETE文でも使用します。SELECT文だけで使うわけではありません。更新するレコードや削除するレコードを特定するためです。逆に言えば、 WHERE句のない UPDATE文やDELETE文 は全てのレコードを対象にしますから一般的にはほとんど使わないと思っておきましょう。この点はまた触れていきます。
以上、検索(SELECT文)について見てきました。
次は「検索結果のソート、グループ化と集約関数」を学びましょう。