
第1章:はじめに|機械学習の世界へようこそ
この章では、機械学習とはそもそも何なのか?という基本から、「AI」「深層学習」といったよく耳にする言葉との違い、そしてこのテキストで学ぶ内容や準備しておくべきことまで、しっかりとお伝えしていきます。
これから一緒に、機械学習という知的で面白い世界を冒険していきましょう!
機械学習とは何か?
みなさんは「機械が自分で学ぶ」と聞いて、どんなイメージを持ちますか?
たとえば、次のようなことができたら便利だと思いませんか?
- メールが迷惑メールかどうか自動で判断してくれる
- スマホのカメラが風景を認識して自動でモードを切り替える
- ネットショップが「あなたへのおすすめ商品」を提案してくれる
こうした「データをもとに、コンピュータが自動的に判断や予測をする仕組み」をつくる技術こそが 機械学習(Machine Learning) です。
人間がルールを細かく書かなくても、「こういうデータのときは、こういう結果になりやすい」といったパターンをコンピュータが学び、応用していきます。
人工知能(AI)、機械学習(ML)、深層学習(DL)の違い
似たような言葉がいくつかありますよね。ここで一度、整理しておきましょう。
| 用語 | 略語 | 概要 |
|---|---|---|
| 人工知能 | AI | 人間のように「考える」「判断する」ことを目指した技術の総称 |
| 機械学習 | ML | AIの中でも、「データから学ぶ」能力を持つ技術 |
| 深層学習(ディープラーニング) | DL | MLの中でも特に「多層のニューラルネットワーク」を使った高度な手法 |
つまり、
AI > ML > DL という「入れ子構造」になっているわけです。
たとえば、AIが「自動運転車全体の頭脳」だとすれば、MLは「標識を学習して認識する目」、DLは「複雑な映像を読み取って判断する脳の一部」だとイメージするとわかりやすいかもしれません。
なぜPythonなのか?
数あるプログラミング言語の中で、なぜPython(パイソン)が機械学習に向いているのでしょうか?
理由はいくつかあります。
- 文法がシンプルで読みやすい
→ 初心者にも優しい言語です。 - 強力なライブラリが豊富
→ 機械学習の定番ライブラリ(scikit-learn、TensorFlow、PyTorchなど)がPythonで書かれています。 - 世界中で使われている
→ 情報も豊富で、困ったときにネットで検索すれば答えが見つかりやすいです。
つまり、Pythonは学びやすさと実用性のバランスが非常に高い言語なのです!
このテキストで学べること
このテキストでは、以下のような内容を丁寧に学んでいきます。
- データの扱い方(読み込み・加工・可視化)
- 機械学習の基本用語と考え方
- Pythonを使った機械学習モデルの作成方法
- 回帰や分類などの代表的なアルゴリズム
- モデルの評価と改善の方法
- 実践的な小さなプロジェクトの構築
最終的には、「自分の力でデータを分析し、モデルを作って評価できる」状態を目指します。
学習に必要な準備・前提知識
「自分にできるだろうか…」と不安になる方もいるかもしれません。
でも安心してください!以下の条件を満たしていれば、このテキストはきっと役立ちます。
事前に知っておくと良いこと
- Pythonの基本的な文法(変数、リスト、関数、if文など)
- 高校レベルの数学(特に、一次関数・平均・分散などの基本統計)
- パソコン操作の基本スキル(フォルダ操作やエディタの使い方)
もしPythonがまったく初めての方は、簡単なPython入門書やチュートリアルを先にやっておくとスムーズに進められます。
次のステップ
ここまでで、機械学習を学ぶ上での全体像が少し見えてきたかと思います。
次章からは、実際にPythonの環境を整え、手を動かしていきます!
「道具の準備をしてから旅に出る」ようなイメージで、開発環境を整えていきましょう。
第2章:Pythonと開発環境の準備|学習を始める前の第一歩
ここからはいよいよ、実際にPythonを使って機械学習に取り組むための「環境作り」に入っていきます!
料理で言えば、包丁やまな板、材料をそろえる段階です。
この章では以下の3つをじっくり解説していきます。
- Pythonのインストール方法
- Jupyter Notebookの使い方
- よく使うライブラリの紹介とインストール方法
Pythonのインストール
Pythonは、無料で使えるプログラミング言語です。
インストールにはいくつかの方法がありますが、初心者の方には「Anaconda(アナコンダ)」というパッケージの使用をおすすめします。
なぜAnacondaが便利なのか?
Anacondaは、以下のような特徴があります。
- Python本体と、よく使うライブラリが最初からまとめて入っている
- 環境構築が簡単
- データ分析や機械学習に必要なツールがすぐに使える
一言で言えば、「機械学習に最適化されたお弁当パック」のようなものです!
インストール手順(Windows / macOS 共通)
- 公式サイトにアクセス:https://www.anaconda.com/products/distribution
- 「Download」から自分のOSに合ったバージョンを選ぶ
- ダウンロードしたインストーラを実行
- 基本的には「Next」をクリックしていくだけで完了
インストール後、「Anaconda Navigator」または「Anaconda Prompt」というメニューが使えるようになります。
Jupyter Notebookの使い方
Anacondaをインストールすると、「Jupyter Notebook(ジュピター・ノートブック)」という非常に便利なツールも使えるようになります。
Jupyter Notebookとは?
簡単に言えば、コードと説明をひとつの画面でまとめて書けるメモ帳のようなものです。
しかも、リアルタイムでPythonコードを実行できます。
たとえば:
print("こんにちは、機械学習!")
と書いて「Shift + Enter」を押すと、すぐ下に結果が表示されます。
起動方法
- Anaconda Navigatorを開く
- 「Jupyter Notebook」を起動
- ブラウザが開き、ファイル一覧が表示される
- 任意の場所で「New → Python 3」を選べば、Notebookが開きます!
これでコードの入力と実行、説明文の記述がすべてひとつの画面でできるようになります。
ライブラリの紹介とインストール方法
機械学習では、「ライブラリ」と呼ばれる便利なツール集を使って作業を効率化します。
ここでは基本的な4つのライブラリを紹介します。
| ライブラリ名 | 用途 |
|---|---|
| NumPy | 数値計算(配列・行列の操作) |
| pandas | データの整理・加工 |
| matplotlib | データの可視化(グラフなど) |
| scikit-learn | 機械学習モデルの構築・評価 |
それぞれの使い方は後の章で詳しく紹介していきますが、ここではインストールの方法だけ押さえておきましょう。
Anacondaを使っている場合
実は、これらのライブラリは最初から入っています!
ただし、バージョン確認や再インストールしたい場合は、以下のコマンドを使ってみてください。
conda install numpy pandas matplotlib scikit-learn
pipを使う場合(Anacondaを使わない人向け)
pip install numpy pandas matplotlib scikit-learn
どちらも、ターミナル(macOS)やコマンドプロンプト(Windows)に入力します。
まとめと次のステップ
ここまでで、Pythonの環境が整いました!
- Anacondaを使えばPython+Jupyter Notebookがすぐに使える
- Jupyter Notebookで手軽にコードを書ける
- NumPyやpandasなど、機械学習に必要なライブラリがすぐ使える
「道具の準備」はこれで完了です。
次章ではいよいよ、データを読み込んで操作するところから始めていきます!
第3章:データの扱い方|機械学習の出発点はここから
どんなに優れたモデルでも、「データ」がなければ始まりません。
そして、正しく整えられたデータこそが、機械学習の精度を大きく左右します。
この章では、以下の内容をひとつずつ見ていきます。
- データとは何か?
- CSVファイルの読み込みと保存
- pandasによるデータフレーム操作
- 欠損値や外れ値の処理
- グラフを使ったデータの可視化
データとは何か?
まずは基本から確認しましょう。
データ=現実を数字や記号にしたもの
たとえば、次のような表があったとします。
| 名前 | 年齢 | 身長(cm) | 体重(kg) |
|---|---|---|---|
| 山田 | 17 | 170 | 58 |
| 鈴木 | 16 | 165 | 54 |
| 高橋 | 18 | 180 | 72 |
このように、「誰かのプロフィール」を数字で表現したものがデータです。
機械学習ではこのような 表形式のデータ(=構造化データ) を多く扱います。
各行は1人分の情報、各列は「特徴量(feature)」と呼ばれます。
CSVファイルの読み込みと保存
表形式のデータを扱う際、よく使われる形式が CSV(Comma Separated Values) です。
カンマで区切ったテキスト形式のファイルで、さまざまなソフト(ExcelやGoogleスプレッドシートなど)と互換性があります。
読み込み方法(pandasを使用)
import pandas as pd
df = pd.read_csv("sample.csv")
このようにすると、df という変数にCSVデータが「データフレーム」として格納されます。
書き出し方法
編集したデータを保存したいときは以下のようにします。
df.to_csv("output.csv", index=False)
index=False を指定することで、行番号(インデックス)をファイルに含めずに保存できます。
pandasでのデータフレーム操作
pandas(パンダス)は、データ分析の最強ツールのひとつです。
表形式のデータを「データフレーム」という形式で扱えます。
データの基本確認
df.head() # 上から5行表示
df.info() # 列の情報とデータ型
df.describe() # 基本統計量(平均、標準偏差など)
列を指定して抽出
df["年齢"] # 単一列(Series)
df[["年齢", "身長"]] # 複数列(DataFrame)
条件をつけて絞り込み
df[df["年齢"] > 17] # 年齢が17歳より大きい人だけ
新しい列を追加
df["BMI"] = df["体重(kg)"] / (df["身長(cm)"]/100)**2
欠損値・外れ値の処理
実データには「穴」や「おかしな値」がよく混ざっています。
これを処理せずにモデルに渡すと、精度が落ちたりエラーになったりします。
欠損値(NaN)の確認と処理
df.isnull().sum() # 各列の欠損数を確認
df.dropna() # 欠損行を削除
df.fillna(0) # 欠損値を0で埋める
dropna() は「消す」処理、fillna() は「埋める」処理です。
外れ値の検出(四分位範囲を使う)
Q1 = df["身長(cm)"].quantile(0.25)
Q3 = df["身長(cm)"].quantile(0.75)
IQR = Q3 - Q1
outliers = df[(df["身長(cm)"] < Q1 - 1.5*IQR) | (df["身長(cm)"] > Q3 + 1.5*IQR)]
四分位範囲(IQR)を使えば、一般的な外れ値を統計的に抽出できます。
データの可視化:matplotlibとseabornの基本
数値だけでは見えないパターンも、グラフにすると一目でわかります。
matplotlibの基本(折れ線・棒・ヒストグラム)
import matplotlib.pyplot as plt
df["身長(cm)"].hist()
plt.title("Height Distribution")
plt.xlabel("Height (cm)")
plt.ylabel("Frequency")
plt.show()
seabornの基本(見た目がキレイ!)
import seaborn as sns
sns.boxplot(x=df["体重(kg)"])
plt.title("Weight Boxplot")
plt.show()
ヒストグラムは分布を見るのに、ボックスプロットは外れ値の確認に便利です。
まとめと次のステップ
この章では、以下のスキルを習得しました。
- 表形式のデータをPythonで扱えるようになった
- CSVファイルの読み込み・保存方法を学んだ
- 欠損値や外れ値を処理する基礎を身につけた
- グラフでデータを直感的に理解できるようになった
これは、機械学習において非常に重要な「前処理(preprocessing)」の土台です。
しっかりマスターしておくと、今後のアルゴリズム実装がグッと楽になります。
第4章:機械学習の基本用語と分類|しくみを知れば怖くない!
ここからは、いよいよ機械学習の「考え方」や「用語」について学びます。
ここをしっかり理解すれば、以降のアルゴリズムの学習がグンとラクになりますよ。
教師あり学習と教師なし学習の違い
まずは、機械学習を大きく2つに分けてみましょう。
| 種類 | 特徴 | 例 |
|---|---|---|
| 教師あり学習 | 「答え付きデータ」で学習する | 売上の予測、スパムメールの判定など |
| 教師なし学習 | 「答えなしのデータ」でパターンを見つける | 顧客のグループ分けなど |
教師あり学習(Supervised Learning)
「正解がある」データでモデルを学習させる手法です。
たとえば、「部屋の広さと家賃の関係」を学ばせて、未来の家賃を予測する場合など。
データ:広さ → 家賃
モデル:広さから家賃を予測する数式やルール
これを数学で表すと、次のような式になります。 y=f(x)y = f(x)
($y$:出力、$x$:入力、$f$:予測のしくみ)
教師なし学習(Unsupervised Learning)
「正解がない」データから、構造やグループを見つけ出す手法です。
たとえば、あるスーパーの顧客の購買履歴から、「似たような買い物をする人たち」を自動で分類する場合など。
回帰と分類とは?
教師あり学習には、大きく分けて 回帰(Regression) と 分類(Classification) の2種類があります。
| 種類 | 出力のタイプ | 例 |
|---|---|---|
| 回帰 | 数値(連続値) | 売上予測、温度予測など |
| 分類 | ラベル(カテゴリ) | スパム判定、病気の有無など |
回帰:連続的な数値を予測
数式で表すと、 y^=wx+b\hat{y} = wx + b
($\hat{y}$:予測値、$w$:重み、$x$:入力、$b$:バイアス)
たとえば、「部屋の広さ」が広いほど「家賃」が高くなるような関係を表現できます。
分類:カテゴリを分ける
分類では「犬か猫か」「合格か不合格か」など、カテゴリを判定します。
入力:ある花のがく片の長さと幅
出力:その花の品種(Setosa、Versicolorなど)
アルゴリズムには ロジスティック回帰 や 決定木 などがあります。
特徴量、ラベル、モデル、学習とは?
ここで、機械学習の主要な用語をまとめて覚えておきましょう!
| 用語 | 意味 |
|---|---|
| 特徴量(Feature) | 入力となる情報(例:年齢、身長、天気など) |
| ラベル(Label) | 正解(出力)の情報(例:合格/不合格など) |
| モデル(Model) | 学習の結果できる「予測のしくみ」 |
| 学習(Training) | 特徴量とラベルから、モデルの中身を決める作業 |
例:試験の合否予測
| 年齢 | 勉強時間 | 合格した? |
|---|---|---|
| 18 | 2時間 | 不合格 |
| 19 | 6時間 | 合格 |
| 17 | 1時間 | 不合格 |
- 特徴量:年齢、勉強時間
- ラベル:合格/不合格
- モデル:合格するかどうかを予測するしくみ
- 学習:このデータからモデルをつくること
過学習と汎化の考え方
ここで非常に大事な概念を紹介します。それが 過学習(Overfitting) と 汎化(Generalization) です。
過学習とは?
訓練データに「覚えすぎてしまい」、新しいデータに対応できなくなる状態です。
たとえば、模試の問題だけを暗記してしまって、本番では通用しない――そんな学生を想像してみてください。
グラフでイメージすると、こうなります:
- 過学習:訓練データにはピッタリだが、新しいデータではミスが多い
- 汎化:訓練にもテストにも「そこそこ」うまく対応できる
数式で表すと?
過学習を避けるには、モデルの複雑さ(自由度)と汎化性能のバランスを取る必要があります。 損失関数=誤差+λ⋅複雑さ\text{損失関数} = \text{誤差} + \lambda \cdot \text{複雑さ}
(λは調整係数。「正則化」と呼ばれる考え方です)
まとめと次のステップ
この章では、機械学習の全体構造に関わる重要なキーワードを学びました。
- 教師あり/教師なし学習の違い
- 回帰と分類という問題設定
- 特徴量やラベルといったデータ構造の理解
- モデルの学習プロセス
- 過学習と汎化という本質的な課題
これらの概念を押さえることで、以降のアルゴリズムの理解がグッと深まります!
第5章:線形回帰モデルを作ってみよう|予測の第一歩を踏み出す!
いよいよ、機械学習アルゴリズムの実装に入ります。
まずは最もシンプルで理解しやすい「線形回帰(Linear Regression)」を扱います。
この章では次のような内容を学びます。
- 線形回帰の考え方と仕組み
- 数式から直感的に理解する
- scikit-learnでPython実装
- モデルの評価方法(MSE, RMSE, R²スコア)
線形回帰の基本
「回帰」とは、数値を予測する問題でしたね。
線形回帰は、「入力変数(x)」と「出力変数(y)」の間に直線的な関係があると仮定し、その直線の式を学習します。
たとえば、部屋の広さから家賃を予測するようなケースです。
広さ(m²) → 家賃(万円)
具体例
| 広さ(㎡) | 家賃(万円) |
|---|---|
| 20 | 5.2 |
| 30 | 6.8 |
| 40 | 9.1 |
数式で理解する:
線形回帰の基本式はとてもシンプルです。
:予測する値(出力)
:説明変数(入力)
:重み(傾き)
:バイアス(切片)
この式は中学の 一次関数 とほとんど同じですね。
機械学習では、データを使って最適な
scikit-learnで線形回帰を実装
それでは、Pythonで実装してみましょう!
scikit-learn(サイキットラーン)というライブラリを使います。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
# データの準備
X = np.array([[20], [30], [40]]) # 入力(2次元配列)
y = np.array([5.2, 6.8, 9.1]) # 出力(ラベル)
# モデル構築と学習
model = LinearRegression()
model.fit(X, y)
# パラメータの確認
print("傾き(w):", model.coef_)
print("切片(b):", model.intercept_)
# 予測
new_X = np.array([[35]])
print("予測家賃:", model.predict(new_X))
モデルの評価(MSE、RMSE、R²スコア)
線形回帰では以下のような評価指標がよく使われます。
平均二乗誤差(MSE)

- 実測値と予測値の差の2乗を平均したもの
- 小さいほど予測が正確
平均平方根誤差(RMSE)

- MSEの平方根
- 単位が元データと一致するので解釈しやすい
決定係数(R²スコア)

:完璧な予測
:平均で予測したのと同じ精度
- 1に近いほどよいモデル
Pythonコード例
from sklearn.metrics import mean_squared_error, r2_score
y_pred = model.predict(X)
mse = mean_squared_error(y, y_pred)
rmse = np.sqrt(mse)
r2 = r2_score(y, y_pred)
print("MSE:", mse)
print("RMSE:", rmse)
print("R²:", r2)
まとめと次のステップ
この章では、以下の知識を得ました:
- 線形回帰の基本原理(
- Pythonとscikit-learnを使ったモデル構築
- MSE・RMSE・R²といった評価指標の使い方
線形回帰は非常にシンプルですが、機械学習の基礎的な考え方が凝縮されたアルゴリズムです。
次章では、「分類問題」にチャレンジします。
Yes/Noの判定やカテゴリー分けなどに使われる「ロジスティック回帰」について、仕組みと実装を学びましょう!
第6章:分類問題に挑戦|YesかNoかを判断する仕組みとは?
今回は「分類問題」にチャレンジします。
分類とは、データがどのグループに属するかを予測する問題です。
この章では以下のことを学びます。
- ロジスティック回帰の仕組み
- 分類における「確率」の扱い
- 分類モデルの評価指標(Accuracy, Precision, Recall, F1など)
- 実際のデータ(Iris)を使った実践
ロジスティック回帰の考え方
「回帰」という名前がついていますが、ロジスティック回帰(Logistic Regression) は分類問題に使うアルゴリズムです。
S字カーブで分類
ロジスティック回帰では、「あるクラスに属する確率」を次の式で求めます:

:予測された確率(0〜1の間)
この式は「シグモイド関数」と呼ばれます。
$x$ が小さければ
クラス分類と確率
あるデータが「クラス1(例:スパム)」である確率が 
多クラス分類の場合
ロジスティック回帰は、3つ以上のクラスも扱えます。
このときは「ソフトマックス関数」を使って、各クラスの確率を出します(詳しくは後の章で扱います)。
評価指標(正解率、適合率、再現率、F1スコア、混同行列)
分類モデルが「うまく機能しているか」を測るには、以下のような指標を使います。
1. 正解率(Accuracy)

全体の中で正しく予測できた割合です。
簡単で便利ですが、クラスの数が偏っているときには注意が必要です。
2. 適合率(Precision)

→「陽性と予測されたもののうち、どれだけ本当に陽性だったか」
3. 再現率(Recall)

→「本来の陽性のうち、どれだけ取りこぼさなかったか」
4. F1スコア(調和平均)

適合率と再現率のバランスが大切なときに有効です。
5. 混同行列(Confusion Matrix)
結果を表にまとめたものです:
| 実際 Positive | 実際 Negative | |
|---|---|---|
| 予測 Positive | TP(正しく陽性) | FP(誤って陽性) |
| 予測 Negative | FN(誤って陰性) | TN(正しく陰性) |
Irisデータセットで実践
scikit-learnには、花の種類を分類するIrisデータセットが用意されています。
実装例
from sklearn.datasets import load_iris
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report, confusion_matrix
# データの読み込み
iris = load_iris()
X = iris.data
y = iris.target
# 学習用とテスト用に分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# モデル構築と学習
model = LogisticRegression(max_iter=200)
model.fit(X_train, y_train)
# 予測と評価
y_pred = model.predict(X_test)
print(confusion_matrix(y_test, y_pred))
print(classification_report(y_test, y_pred, target_names=iris.target_names))出力の例(簡略)
混同行列:
[[10 0 0]
[ 0 7 1]
[ 0 0 12]]
分類レポート:
precision recall f1-score support
setosa 1.00 1.00 1.00 10
versicolor 1.00 0.88 0.93 8
virginica 0.92 1.00 0.96 12
かなり高精度で3種類の花を分類できていることがわかります。
まとめと次のステップ
この章では、分類の基礎と評価を学びました。
- ロジスティック回帰は「確率で分類する」シンプルで強力な手法
- 分類精度を測るには「Accuracy」「Precision」「Recall」「F1スコア」など複数の視点が必要
- 実データ(Iris)を使って予測→評価まで実践できた!
第7章:さまざまなアルゴリズムを使ってみよう|モデル選びの引き出しを増やそう
ロジスティック回帰を使った分類に慣れてきたら、**他のアルゴリズムも試してみたい!**と思う方も多いはず。
実際、機械学習にはさまざまな手法があり、目的やデータの特徴に応じて最適なものを選ぶことが重要です。
この章では以下の4つの代表的なアルゴリズムを紹介します。
- k近傍法(k-NN)
- 決定木とランダムフォレスト
- サポートベクターマシン(SVM)
- Naive Bayes(ナイーブ・ベイズ)
それぞれの特徴と数式的な背景をやさしく解説していきます。
1. k近傍法(k-NN:k-Nearest Neighbors)
特徴
- 「近くにいるデータに従う」という直感的な考え方
- 学習時は何もしない(遅延学習)
- 予測時にすべてのデータとの距離を計算するため、処理が重いこともある
式の考え方
予測対象の点 

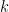
2. 決定木(Decision Tree)とランダムフォレスト(Random Forest)
決定木の特徴
- 条件分岐を繰り返して分類
- if〜thenルールに似ていて、解釈が非常にしやすい
弱点
- 単独では過学習しやすい(トレーニングデータに適合しすぎる)
ランダムフォレストの特徴
- 複数の決定木を学習し、予測を多数決で決定
- 木を構成するデータや特徴量をランダムに選ぶことで、バラつきに強くなる
メリット
- 過学習を防ぎながら高精度
- データの前処理が比較的少なくて済む
3. サポートベクターマシン(SVM)
SVMは、「最も広いマージン(間隔)でクラスを分ける線(または面)」を探すアルゴリズムです。
数式の考え方
SVMは、次の最適化問題を解きます。

ただし、

ここで:
:入力ベクトル
:クラス(+1または-1)
:分離境界のパラメータ
カーネルトリック
非線形なデータも、高次元にマッピングして線形分離できるようにするのがカーネル法です。
4. Naive Bayes(ナイーブ・ベイズ)
特徴
- 確率に基づく分類器
- 非常に高速で、テキスト分類に強い
数式:ベイズの定理

:クラス
である確率(後件確率)
:クラス
:クラスの事前確率
:
ナイーブ(=単純)な仮定
「すべての特徴量が独立している」という仮定を置きます。
現実では独立でないことも多いですが、それでも驚くほど高精度になることがあります。
各アルゴリズムの比較と使いどころ
| アルゴリズム | 長所 | 短所 | 向いている用途例 |
|---|---|---|---|
| k-NN | シンプル、チューニングが少ない | 計算が重い、スケーリングが必要 | 少量データの分類 |
| 決定木 | 視覚的でわかりやすい | 過学習しやすい | 解釈性が重要な場面 |
| ランダムフォレスト | 高精度、過学習に強い | 解釈しにくい | 安定性を重視する場合 |
| SVM | 境界がはっきり、非線形にも強い | 大規模データに弱い、調整が必要 | 小〜中規模データ |
| Naive Bayes | 高速、精度良好 | 特徴量の独立仮定が必要 | スパム分類など |
まとめと次のステップ
この章では、ロジスティック回帰以外の多様な分類アルゴリズムを紹介しました。
第8章:教師なし学習の世界へ|答えのないデータから意味を見つける
ここまで、教師あり学習として「正解があるデータ」に対する分類や回帰を学んできました。
この章では、正解のないデータをもとに法則性や構造を見つけ出す「教師なし学習」を扱っていきます。
クラスタリングとは?
クラスタリング(clustering)とは、似たデータを自動的にグループ分けする技術です。
たとえば:
- 顧客を購買パターンで分類
- 記事を内容ごとに分類
- 遺伝子のパターンから生物を分類
こうした「事前に正解ラベルが与えられていない」データに対して、グループ構造を見つけるのがクラスタリングです。
k-means法の基本
クラスタリングで最も有名なアルゴリズムが k-means法(k-means clustering) です。
手順
- クラスタ数
を決める
- ランダムに
- 各データ点を最も近い中心に割り当てる
- 各クラスタの中心を再計算する
- 割り当てが変わらなくなるまで繰り返す
評価指標:SSE(Sum of Squared Errors)
クラスタ内のばらつきを最小にするように分割を行います。

:クラスタ
の集合
:クラスタ
SSEが小さいほど、クラスタ分けが「密集している」と判断できます。
主成分分析(PCA)で次元削減
教師なし学習でよく使われるもう一つの技術が、**次元削減(Dimensionality Reduction)**です。
たとえば、10個の特徴量を2つに減らしても、情報の多くを維持したまま処理を軽くしたり、可視化しやすくしたりできます。
主成分分析(PCA:Principal Component Analysis)
PCAは、データのばらつきが最も大きい方向を「主成分」として抽出し、少ない次元でデータを表現する方法です。
共分散行列と固有値分解
![\text{Cov}(X) = E[(X - \mu)(X - \mu)^T]](https://s0.wp.com/latex.php?latex=%5Ctext%7BCov%7D%28X%29+%3D+E%5B%28X+-+%5Cmu%29%28X+-+%5Cmu%29%5ET%5D+&bg=ffffff&fg=000&s=0&c=20201002)
この共分散行列の固有値・固有ベクトルを求め、それらを使って主成分を決定します。
変換の仕組み
元のデータ 

:主成分ベクトル(列ベクトルを並べた行列)
:低次元空間に写された新しいデータ
可視化と解釈の工夫
教師なし学習ではラベルがないため、結果をどう理解するかが大事です。
散布図やヒートマップ
- PCAで2次元に圧縮し、クラスタの違いを視覚的に比較
- 特徴量ごとの平均値やばらつきを見て、グループの性質を推定
実践例:IrisデータにPCAとk-meansを適用
from sklearn.datasets import load_iris
from sklearn.cluster import KMeans
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
iris = load_iris()
X = iris.data
# PCAで2次元に圧縮
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X)
# k-meansでクラスタリング
kmeans = KMeans(n_clusters=3, random_state=42)
labels = kmeans.fit_predict(X)
# 散布図で可視化
plt.scatter(X_pca[:, 0], X_pca[:, 1], c=labels)
plt.xlabel("PC1")
plt.ylabel("PC2")
plt.title("k-means clustering after PCA")
plt.show()
まとめと次のステップ
この章では、「正解のないデータ」から構造を発見する方法を学びました。
- クラスタリング(k-means)では、似たデータを自動でグループ分け
- 主成分分析(PCA)を使えば、次元を減らして分析がしやすくなる
- 可視化を通じて、グループの意味を解釈することが大切
次章では、モデルの精度を上げるためのテクニックを紹介します。
スケーリングやハイパーパラメータ調整、交差検証、パイプラインなど、プロっぽい実装の第一歩を学んでいきましょう!
第9章:モデルの精度を高めるテクニック|“なんとなく作ったモデル”から卒業しよう
せっかく作ったモデルでも、そのままでは本来の力を発揮できていないことが多くあります。
この章では、モデルの性能を引き出すためのテクニックを学んでいきましょう。
データの前処理とスケーリング
スケーリングとは?
特徴量の単位やスケールが異なる場合、距離や重みの計算に影響を与えるため、スケーリングが重要です。
標準化(Standardization)
平均0、標準偏差1に変換します:

:平均
:標準偏差
正規化(Min-Max Scaling)
0〜1の範囲にスケーリングします:

- 値が全て同じスケールに揃うため、SVMやk-NNなどで効果的です。
ハイパーパラメータ調整(グリッドサーチ・ランダムサーチ)
ハイパーパラメータとは、学習前に設定するパラメータのことです(例:k-NNの $k$、SVMの $C$ など)。
グリッドサーチ(Grid Search)
すべての組み合わせを試す方法です。
from sklearn.model_selection import GridSearchCV
from sklearn.svm import SVC
param_grid = {'C': [0.1, 1, 10], 'kernel': ['linear', 'rbf']}
grid = GridSearchCV(SVC(), param_grid, cv=5)
grid.fit(X_train, y_train)
ランダムサーチ(Randomized Search)
指定した回数だけ、ランダムにパラメータを選んで試す方法です。
広い範囲を素早く探索したいときに有効です。
交差検証(Cross Validation)
単に「訓練データとテストデータを分ける」だけでは評価が不安定になることがあります。
そこで使われるのが「交差検証」です。
k分割交差検証(k-fold cross validation)
データを 
評価値の平均を取ることで、安定したモデル評価が可能になります。
パイプラインの活用
前処理 → モデル構築 → 評価 という一連の流れをひとまとめにして管理できるのが「パイプライン」です。
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
pipe = Pipeline([
('scaler', StandardScaler()),
('svc', SVC())
])
pipe.fit(X_train, y_train)
メリット
- コードが整理される
- グリッドサーチと組み合わせやすい
- 実運用時のエラーを防げる
まとめと次のステップ
この章では、モデルの精度を高めるための4つのテクニックを学びました。
| テクニック | 効果 |
|---|---|
| スケーリング | 特徴量の単位をそろえることで性能向上 |
| ハイパーパラメータ調整 | モデルの力を最大限に引き出す |
| 交差検証 | 安定した性能評価が可能になる |
| パイプライン | 処理の一貫性と再現性を高める |
次章では、いよいよ簡単な実践プロジェクトに取り組みます!
実データを使って、モデルを構築・評価・可視化するまでの一連の流れを実践していきましょう!
第10章:簡単なプロジェクトにチャレンジ!|学びを実践につなげよう
これまでに学んだ機械学習の基礎と実装スキルを活かして、ひとつのプロジェクトを最初から最後までやりきることを目指しましょう!
今回は、住宅価格を予測する回帰モデルを作成します。
実データを使った機械学習プロジェクト
使用データ:California Housing Dataset
このデータは以下のような特徴量を持っています。
| 特徴量名 | 説明 |
|---|---|
| MedInc | 世帯収入(中央値) |
| HouseAge | 築年数 |
| AveRooms | 平均部屋数 |
| AveOccup | 平均世帯人数 |
| Latitude | 緯度 |
| Longitude | 経度 |
| MedHouseVal | 目的変数:住宅価格の中央値 |
問題の定義からモデル構築まで
from sklearn.datasets import fetch_california_housing
import pandas as pd
# データ読み込み
data = fetch_california_housing()
df = pd.DataFrame(data.data, columns=data.feature_names)
df["Price"] = data.target
データ分割と標準化
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
X = df.drop("Price", axis=1)
y = df["Price"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
モデル構築(線形回帰)
from sklearn.linear_model import LinearRegression
model = LinearRegression()
model.fit(X_train_scaled, y_train)
評価と改善
予測精度の評価には以下の3つを使います。
平均二乗誤差(MSE)
平均平方根誤差(RMSE)
決定係数(R²スコア)
from sklearn.metrics import mean_squared_error, r2_score
import numpy as np
y_pred = model.predict(X_test_scaled)
mse = mean_squared_error(y_test, y_pred)
rmse = np.sqrt(mse)
r2 = r2_score(y_test, y_pred)
print(f"MSE: {mse:.3f}")
print(f"RMSE: {rmse:.3f}")
print(f"R²: {r2:.3f}")
プレゼンテーション用のグラフ作成
実測値 vs 予測値(散布図)
import matplotlib.pyplot as plt
plt.figure(figsize=(6, 6))
plt.scatter(y_test, y_pred, alpha=0.3)
plt.plot([y_test.min(), y_test.max()], [y_test.min(), y_test.max()], color='red', linestyle='--')
plt.xlabel("Actual Price")
plt.ylabel("Predicted Price")
plt.title("Actual vs Predicted Prices")
plt.grid(True)
plt.show()
特徴量の重要度(回帰係数)
coefficients = pd.DataFrame({
"Feature": X.columns,
"Coefficient": model.coef_
}).sort_values(by="Coefficient", key=abs, ascending=False)
coefficients.plot.bar(x="Feature", y="Coefficient", figsize=(10, 4), legend=False)
plt.title("Feature Importance")
plt.ylabel("Weight")
plt.tight_layout()
plt.show()
まとめと次のステップ
この章では、以下の工程を一気通貫で体験しました。
- 問題の設定(住宅価格予測)
- データの準備と前処理(スケーリング)
- 線形回帰モデルの構築
- 評価指標(MSE, RMSE, R²)による精度確認
- 可視化による理解と発表資料の準備
この経験を通じて、「機械学習の実務的な流れ」を体感できたはずです。