
今日から一緒に、AI(人工知能)を作るための最強の道具、PyTorch(パイトーチ)について学んでいきましょう。
「AIなんて難しそう」
「プログラミング環境を作るだけで挫折しそう」
そんな不安を持っていませんか?大丈夫です。この連載では、専門用語をできるだけ噛み砕いて、まるで友達と話しているような感覚でAIの世界へ案内します。
第1章となる今回は、AI開発の準備運動です。道具を用意して、基本的なデータの扱い方をマスターしましょう。さあ、準備はいいですか?
1. 面倒な準備は不要!Google Colabを使おう
プログラミングを始めるとき、一番の壁になるのが「環境構築」です。自分のパソコンにソフトをインストールしたり、設定をいじったりしているうちにエラーが出て、やる気がなくなってしまう。あるあるですよね。
そこで、今回は「Google Colab(グーグル・コラボ)」というツールを使います。
これは、Googleがブラウザ上で提供しているプログラミング実行環境です。インターネットさえ繋がっていれば、あなたのパソコンが古くても、スマホやタブレットからでも、高性能なAI開発環境にアクセスできるんです。
例えるなら、料理をするために高い調理器具や広いキッチンを自分で買わなくても、無料で使える超高級レンタルキッチンがネット上にあるようなものです。
Google Colabのメリット
- 無料で使える(GoogleアカウントがあればOK)
- 環境構築が不要(アクセスしてすぐにコードが書ける)
- GPU(計算を高速にする装置)が無料で使える
Google Colabのデメリット
- インターネット接続が必須
- 長時間放置すると接続が切れて、データがリセットされることがある
まずはGoogleで「Google Colab」と検索して、新しいノートブックを作成してみてください。真っ白な画面が出てきましたか?それが、あなたがAIを作るためのキャンバスです。
2. AIの言葉「テンソル」を理解しよう
環境が整ったら、次はPyTorchの基礎中の基礎、「テンソル(Tensor)」について学びましょう。
テンソルという言葉を聞くと難しそうに聞こえますが、実はただの「数字の入れ物」のことです。
AIは画像や文章をそのまま理解することはできません。すべてを数字に変換して計算します。その数字を整理整頓して入れておく箱がテンソルです。高校の数学で習った「ベクトル」や「行列」を思い出してください。あれの親戚です。
- スカラー(0次元テンソル): ただの1つの数字。例:気温が
度。
- ベクトル(1次元テンソル): 数字が1列に並んだもの。例:テストの点数一覧(国語、数学、英語)。
- 行列(2次元テンソル): 数字が縦横に並んだ表。例:クラス全員のテストの点数表。
- 3次元テンソル: 行列がさらに奥に重なったようなもの。例:カラー画像(縦
横
PyTorchでは、このテンソルを使ってすべての計算を行います。つまり、テンソルを使いこなすことが、AIエンジニアへの第一歩なのです。
3. 実際にコードを書いてみよう
では、実際に手を動かしてみましょう。Google Colabのセル(入力欄)に、以下のコードを打ち込んで、再生ボタン(実行)を押してみてください。
まずは、PyTorchという道具箱を使えるようにします。
import torch
これで準備完了です。
テンソルを作ってみる
数字のリストからテンソルを作ってみましょう。
# リストからテンソルを作成
x = torch.tensor([1, 2, 3])
print(x)
出力結果を見ると、 tensor([1, 2, 3]) と表示されましたね。これで、ただの数字の羅列が、PyTorchで計算できる「テンソル」に生まれ変わりました。
テンソルの計算をしてみる
ここからが本番です。テンソル同士の足し算や掛け算をやってみましょう。
# 2つのテンソルを定義
a = torch.tensor([10, 20, 30])
b = torch.tensor([1, 2, 3])
# 足し算
print(a + b)
# 掛け算(要素ごとの掛け算)
print(a * b)
足し算の結果はどうなりましたか? tensor([11, 22, 33]) となっていれば正解です。
それぞれの場所にある数字同士が足し算されましたね。
ここでの計算を数式で表すと、例えば最初の要素は 




掛け算の場合はどうでしょう。
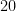

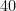
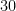
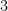
となります。
形を変える魔法
AIを作っていると、データの形を変えたいことがよくあります。例えば、一列に並んだ 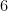
view という命令を使います。
# 0から5までの数字が入ったテンソルを作成
x = torch.tensor([0, 1, 2, 3, 4, 5])
# 2行3列に変形
y = x.view(2, 3)
print(y)
どうですか?一列だった数字が、きれいに
今後の学習の指針
お疲れ様でした!
第1章では、開発環境であるGoogle Colabの使い方と、データの基本単位であるテンソルについて学びました。
- Google Colabを使えば、すぐにAI開発が始められる。
- テンソルは、多次元の数字を入れる箱である。
- テンソル同士は簡単に計算や変形ができる。
これだけ理解できていれば満点です。
次回、第2章では「AI学習の心臓部」とも言える「自動微分」について解説します。
「微分」と聞いて身構えないでくださいね。PyTorchが面倒な計算をどうやって自動でやってくれるのか、その魔法のような仕組みを一緒に覗いてみましょう。
それでは、また次回お会いしましょう!
AIが賢くなる魔法?PyTorchの「自動微分」を直感的に理解しよう
第1章でPyTorchの準備運動はバッチリですね。今回は、いよいよAI学習の核心部分、少し専門的な響きのする「自動微分(Autograd)」についてお話しします。
「微分」という言葉を聞いて、数学の教科書を思い出して頭が痛くなった人もいるかもしれませんね。でも、安心してください。今日の主役であるPyTorchは、まさにその面倒な数学の計算を、私たちの代わりにやってくれる頼もしい相棒なんです。
なぜAIに微分が必要なのか、そしてPyTorchがどうやってそれを助けてくれるのか。数式を見るのが苦手な方でもわかるように、イメージたっぷりで解説していきますよ。
1. そもそも、なぜAIに「微分」が必要なの?
AI、特にディープラーニングが学習する仕組みは、「間違い探し」と「修正」の繰り返しです。
想像してみてください。あなたは真っ暗な山の上にいて、谷底(ゴール)にあるお家へ帰ろうとしています。周りは何も見えません。どうやって谷底へ向かいますか?
きっと、足元の地面の傾きを感じ取って、「こっちが下り坂だ」とわかる方向へ一歩踏み出すはずです。これを繰り返せば、いつかは一番低い場所にたどり着けますよね。
この「地面の傾き」を計算することこそが、数学でいう「微分」なんです。
- 山の上: まだ賢くないAIの状態(間違いだらけ)
- 谷底: 賢くなったAIの状態(間違いが最小)
- 足元の傾き(微分): どっちにパラメータ(設定値)を変えれば賢くなるかのヒント
AI学習とは、この「傾き」を計算して、少しずつ谷底へ向かって進んでいく旅のようなものです。しかし、最近のAIは計算が複雑すぎて、人間が手計算で傾きを求めるのはほぼ不可能です。
そこで登場するのが、PyTorchの「自動微分」機能です。
2. PyTorchの魔法「Autograd」
PyTorchには、計算の履歴をすべて記録しておき、ボタン一つで「傾き(勾配)」を計算してくれる「Autograd」という機能が備わっています。
これがあるおかげで、私たちは複雑な微分の公式を覚える必要がありません。「ゴールまでの計算式」を書くだけで、PyTorchが勝手に「スタート地点への戻り道(傾き)」を教えてくれるのです。
3. 実際にコードで体験してみよう
百聞は一見にしかず。Google Colabを開いて、実際にコードを書いてみましょう。
追跡機能をつける
まず、微分したい変数(テンソル)を作ります。ここで重要なのが requires_grad=True という呪文です。
import torch
# 追跡機能付きのテンソルを作成
x = torch.tensor(3.0, requires_grad=True)
print(x)
この requires_grad=True は、「この変数の計算履歴を全部記録してね!」というPyTorchへの指示です。これをつけることで、あとで自動的に微分ができるようになります。
計算グラフを作る
次に、簡単な計算をしてみましょう。ここでは、中学生で習う 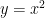


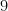
# 計算を行う (y = x^2)
y = x * x
print(y)
出力結果に grad_fn という不思議な文字がついているのが見えますか?これは「どうやって計算されたか覚えているよ」という印です。
魔法の呪文「.backward()」
さあ、ここからがクライマックスです。 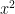
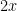
今、 
PyTorchでは、この計算をたった一行で行います。
# 自動微分を実行!
y.backward()
この .backward() という命令が実行された瞬間、PyTorchは計算の履歴を逆のぼり、傾きを計算しました。
答え合わせ
計算された傾きは、 x.grad (グラデーションの略)の中に保存されています。中身を見てみましょう。
# 計算された傾きを表示
print(x.grad)
tensor(6.) と表示されましたか?
大正解です!人間が公式を使って計算した
4. この機能のすごいところ
「たかだか
すごいのは、これがどんなに複雑な計算になっても使えるという点です。足し算、掛け算、対数、三角関数……それらが何千、何万回組み合わさった複雑怪奇なAIのモデルであっても、PyTorchは最後に .backward() と唱えるだけで、すべてのパラメータに対する正しい傾きを瞬時に計算してくれます。
これこそが、世界中の研究者がPyTorchを愛用する理由の一つです。
メリットとデメリット
メリット
- 数学が苦手でも大丈夫: 複雑な微分の計算式を自分で解く必要がありません。
- バグが減る: 人間が手計算でプログラムを書くとミスが起きやすいですが、自動微分なら正確です。
- 試行錯誤が早い: モデルの構造を変えても、自動的に対応してくれるので、すぐに実験できます。
デメリット
- メモリを使う: 計算の履歴をすべて保存しておくため、メモリ(PCの作業領域)を多く消費します。
- ブラックボックス化: 中で何が起きているかわからなくても動いてしまうため、数学的な理解がおろそかになりがちです。
今後の学習の指針
お疲れ様でした!
第2章では、AI学習のエンジンである「自動微分」について学びました。
- AIの学習は、山を下るように「傾き」を使って間違いを減らすこと。
- PyTorchの
requires_grad=Trueと.backward()を使えば、面倒な微分計算が全自動になること。
この感覚さえ掴めていれば、あなたはもうAIの仕組みの半分を理解したようなものです。
さて、道具と理屈は揃いました。次回、「第3章:ニューラルネットワークを作ろう」 では、いよいよ本格的なAIのモデルを組み立てていきます。レゴブロックのように層を積み重ねていく作業は、クリエイティブでとても楽しいですよ!
それでは、また次回お会いしましょう!
まるでレゴブロック!?PyTorchでニューラルネットワークを組み立てよう
第1章でデータの扱い方を学び、第2章で自動微分の魔法に触れました。
いよいよ今回、第3章:ニューラルネットワークを作ろうでは、AIの「体」そのものを作っていきます。
「ニューラルネットワークを作る」なんて言うと、ものすごく複雑な設計図を書くようなイメージがありませんか?
実はPyTorchを使えば、レゴブロックをパチパチと組み立てるような感覚で、直感的にAIのモデルを作ることができるんです!
今回は、プログラミングの楽しさが詰まったこのパートを、一緒に体験していきましょう。
1. AIを作るための部品箱「torch.nn」
PyTorchには、AIを作るための便利な部品がたくさん詰まった torch.nn (ニューラルネットワークの略)というモジュールがあります。
これを使わない場合、私たちは数式を一から全部手書きしなければなりません。それは、家を建てるのに、釘やネジを一本ずつ鉄から削り出して作るようなものです。大変すぎますよね。
torch.nn は、すでに完成された「壁」や「柱」のような部品を提供してくれます。私たちはそれを呼び出して、組み合わせるだけでいいのです。
2. 最も基本的な部品「全結合層(Linear)」
まず最初に覚えるべき部品は、 nn.Linear (リニア)です。日本語では「全結合層」と呼ばれます。
これは、入力されたデータに対して、「重み」を掛けて「バイアス」を足す、という計算を行う層です。
数式で書くと、中学校で習った一次関数 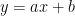
- 入力データ: AIが見ているもの(例:画像の画素)
- 重み: その入力がどれくらい重要かを表す数値
- 出力データ: 次の層へ渡す情報
この nn.Linear は、データの形(次元数)を変換する役割も持っています。例えば、「 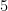
3. AIに表現力を与える「活性化関数(ReLU)」
ただ計算するだけでは、AIは複雑な現実世界を理解できません。そこで必要になるのが「活性化関数」というスパイスです。
中でも一番よく使われるのが ReLU (レル)という関数です。
仕組みはとてもシンプル。「マイナスの数字が来たら 
「そんな単純なことで意味があるの?」と思いますよね。
実は、この「
人間の脳の神経(ニューロン)も、電気信号が一定以上たまらないと発火しませんよね。 ReLU はそれを真似しているのです。
4. クラスを使ってモデルを組み立てよう
では、これらの部品を使って、実際にネットワークを組み立ててみましょう。
PyTorchでは、 nn.Module というひな形を使って、自分だけのAIモデルを定義します。
以下のコードを見てください。これがAIの設計図です!
import torch
import torch.nn as nn
# ニューラルネットワークの定義
class SimpleNet(nn.Module):
def __init__(self):
super().__init__()
# 1. 部品を用意する場所(__init__)
# 入力が3つ、中間層が5つ、出力が2つの層を作る
self.layer1 = nn.Linear(3, 5)
self.layer2 = nn.Linear(5, 2)
self.relu = nn.ReLU()
def forward(self, x):
# 2. 組み立てる手順書(forward)
# 入力xをlayer1に通す
x = self.layer1(x)
# ReLUで活性化させる(マイナスをカット)
x = self.relu(x)
# layer2に通して結果を出す
x = self.layer2(x)
return x
# モデルの実体を作る
model = SimpleNet()
print(model)
少しコードが長くなりましたが、やっていることは料理と同じです。
__init__(初期化): 必要な材料(層)を買ってきて、キッチンに並べる準備段階。forward(順伝播): 実際に材料をどういう順番で調理(計算)して、料理(出力)として出すかの手順。
この forward メソッドの中に、データの流れを書くだけで、PyTorchが自動的に裏側で計算をつなげてくれます。
実際にデータを通してみよう
作ったモデルに、適当なデータを入れてみましょう。入力は
# ダミーの入力データ(3つの数字)
input_data = torch.tensor([1.0, 2.0, 3.0])
# モデルにデータを通す
output = model(input_data)
print("出力結果:", output)エラーなく出力されましたか?
これが、あなたが初めて作ったニューラルネットワークが、データを処理した瞬間です!
メリットとデメリット
メリット
- 柔軟性が高い:
__init__とforwardを書くだけで、どんなに複雑な形のAIでも自由に作れます。 - 再利用しやすい: 一度作ったモデルは部品として保存したり、他のモデルの一部として組み込んだりできます。
- 可読性が高い: データの流れがコードとして上から下へ書かれるので、後から見ても何をしているか分かりやすいです。
デメリット
- 記述量が増える: 単純なモデルでもクラスを定義する必要があるため、数行で書けるライブラリに比べるとコードが少し長くなります。
- Pythonの知識が必要: 「クラス」や「継承」といったPythonの概念を知らないと、最初はとっつきにくいかもしれません。
今後の学習の指針
お疲れ様でした!
第3章では、PyTorchにおけるモデル構築の基礎 nn.Module について学びました。
nn.Linearでデータの形を変えながら計算する。ReLUで表現力を高める。nn.Moduleを継承して、__init__で部品を定義し、forwardでつなげる。
この「部品を用意して、つなげる」という感覚を忘れないでください。どんなに最新のすごいAIも、基本はこの構造の巨大バージョンに過ぎません。
さて、立派なモデル(AIの脳)はできましたが、まだ肝心の勉強道具がありませんね。
次回、「第4章:データセットとデータローダー」 では、AIにご飯(学習データ)を効率よく食べさせるための仕組みを学びます。ここで学ぶテクニックを使えば、大量の画像データもスムーズに扱えるようになりますよ。
AIの「食育」講座!PyTorchでデータを効率よく食べさせる方法【DatasetとDataLoader】
前回は、AIの頭脳となる「ニューラルネットワーク」を組み立てましたね。
でも、いくら優秀な脳みそを作っても、そこに入れる知識(データ)がなければ、AIは何も学ぶことができません。
人間も、教科書を読んだり、経験を積んだりして賢くなりますよね。AIにとってもそれは同じです。
第4章となる今回は、AIにデータという名の「ご飯」を、効率よく、お行儀よく食べさせるための仕組みについて学びます。
「データを読み込むなんて、ただファイルを開くだけじゃないの?」
そう思ったあなた。実は、AIの学習において、データの渡し方は学習スピードや精度を左右する超重要なポイントなんです。
PyTorchに用意されている最強の配膳係、「Dataset」と「DataLoader」をマスターして、AIをすくすくと育てましょう!
1. データ管理の二大巨頭
PyTorchでは、データを扱うために2つの役割分担があります。これがDataset(データセット)とDataLoader(データローダー)です。
この2つの関係は、巨大な図書館で例えるとわかりやすいです。
Dataset:図書館の書庫
「Dataset」は、本(データ)が保管されている書庫そのものです。
ここには、「本が全部で何冊あるか」や、「
あくまで保管場所なので、自分から本を運んだりはしません。
DataLoader:敏腕司書さん
「DataLoader」は、書庫から本を取り出して、あなたの机(AIモデル)まで運んでくれる司書さんです。
ただ運ぶだけではありません。「 
2. なぜ「一口サイズ」にするの?(ミニバッチ学習)
ここで、AI学習におけるとても大切な概念、「ミニバッチ」についてお話しします。
もしあなたが、「この辞書の全部の単語を暗記して!」と言われたらどうしますか?
最初のページから最後のページまでを一気に読んでから、テストに挑みますか?それだと、途中で忘れてしまいますし、頭がパンクしてしまいますよね。
普通は、
AIも同じです。
そこで、データを 
この「一口サイズに切り分ける作業」を自動でやってくれるのが、DataLoaderのすごいところなんです。
3. オリジナルのDatasetを作ってみよう
では、実際にコードを書いてみましょう。まずは、データを保管する「Dataset」を作ります。
PyTorchで自作のデータセットを作るルールは簡単です。以下の3つを決めるだけです。
__init__:データの準備(材料を買ってくる)__len__:データの総数を返す(全部で何食分あるか教える)__getitem__:指定された番号のデータを返す(注文された料理を出す)
import torch
from torch.utils.data import Dataset
# 自作データセットの定義
class MyNumberDataset(Dataset):
def __init__(self):
# 0から99までの数字データを用意
self.data = list(range(100))
def __len__(self):
# データの個数を返す
return len(self.data)
def __getitem__(self, index):
# index番目のデータを取り出す
x = self.data[index]
# AIが扱えるテンソルに変換して返す
return torch.tensor(x, dtype=torch.float32)
# データセットを作成
dataset = MyNumberDataset()
# 5番目のデータを取り出してみる
print(dataset[5])
これで、 
4. DataLoaderでデータを運ぼう
次に、この倉庫からデータを運び出す「DataLoader」を使います。ここが腕の見せ所です。
from torch.utils.data import DataLoader
# データローダーの作成
# batch_size=10 : 10個ずつまとめて運んでね
# shuffle=True : 毎回順番をシャッフルしてね
dataloader = DataLoader(dataset, batch_size=10, shuffle=True)
# データを取り出してみる
for batch in dataloader:
print(batch)
break # 最初の一口だけでストップ
実行結果を見てください。順番がバラバラになった数字が、
なぜシャッフルするの?
shuffle=True にすると、データをその都度かき混ぜてくれます。これは、AIが「データの順番」を丸暗記しないようにするためです。
単語帳を「あいうえお順」のまま覚えると、順番が変わった瞬間に答えられなくなること、ありますよね?AIもランダムに特訓することで、本質的な力を身につけることができるのです。
メリットとデメリット
メリット
- メモリ効率が良い: 必要な分だけ読み込むので、巨大なデータセットでもパソコンがフリーズしません。
- 学習が安定する: データをシャッフルしたり、バッチサイズを調整したりする試行錯誤が、引数を変えるだけで簡単にできます。
- コードが綺麗になる: データの前処理部分と、学習させる部分をきれいに分離できます。
デメリット
- 最初は戸惑う: Pythonのクラス(class)の知識が必要になるため、初心者には少し敷居が高く感じるかもしれません。
- デバッグが難しい: データ読み込み部分でエラーが出たとき、どこが原因か特定するのに少し慣れが必要です。
今後の学習の指針
お疲れ様でした!
第4章では、AIにご飯をあげるための仕組み「Dataset」と「DataLoader」について学びました。
- Datasetは、データを保管し、一つずつ取り出せるようにする倉庫。
- DataLoaderは、データを一口サイズ(ミニバッチ)にまとめて運んでくれる配膳係。
- データを小分けにしたりシャッフルしたりすることで、AIは効率よく学習できる。
ここまでで、AI(モデル)とご飯(データ)の準備が整いました。
でも、まだAIは「どうやって食べれば(学習すれば)いいか」を知りません。
次回、「第5章:損失関数と最適化」では、AIが自分の間違いに気づき、それを修正して賢くなっていくための「指導方法」について学びます。ここがAI学習の司令塔となる面白いパートです。
AIはどうやって反省するの?損失関数と最適化で「失敗」を「成功」に変える方法
前回は、AIにご飯(データ)をあげる方法を学びましたね。
モデルもあって、データもある。でも、これだけではAIは賢くなりません。なぜなら、生まれたばかりのAIは、何が正解で何が間違いかを知らないからです。
テストで0点を取っても、先生に採点されなければ、「自分は天才だ!」と勘違いしたままかもしれませんよね?
第5章のテーマは、まさにその「採点(損失関数)」と「復習(最適化)」です。
AIが自分の間違いを認め、次はどうすれば正解に近づけるのか。その修正プロセスを司る重要な司令塔について解説します。
ここを理解すれば、AIが学習する仕組みの9割を理解したと言っても過言ではありません。さあ、一緒に見ていきましょう!
1. AIの採点係「損失関数(Loss Function)」
まず必要なのは、AIが出した答えが「どれくらい間違っているか」を数値化する定規です。これを専門用語で「損失関数(ロス・ファンクション)」と呼びます。
イメージしてください。
AIが「明日の気温は
でも、実際(正解)は 
このとき、ズレ(誤差)は
この数字が「0」に近づけば近づくほど、AIは優秀だということになります。
PyTorchには、用途に合わせてたくさんの採点方法が用意されていますが、初心者がまず覚えるべきはこの2つです。
MSELoss(平均二乗誤差)
- 使い道: 数の予測(回帰)に使います。
- 仕組み: ズレを2乗します。
- 予測
。2乗して
が「損失」になります。
- なぜ2乗するの?:プラスとマイナスの打ち消し合いを防ぐためと、大きく間違えたときに「大間違いだぞ!」と罰則を重くするためです。
- 予測
CrossEntropyLoss(交差エントロピー誤差)
- 使い道: 分類(クラス分類)に使います。
- 仕組み: 「猫」か「犬」かを当てるときなど、確率の分布のズレを計算します。
- 画像分類をするなら、迷わずこれを選びましょう。
2. AIのコーチ「最適化(Optimizer)」
採点(損失の計算)が終わったら、次は「反省」の時間です。
「
この「書き換え作業」を行ってくれるのが「最適化手法(オプティマイザ)」です。
第2章で学んだ「自動微分」が計算した「傾き(方向)」を使って、実際にパラメータを更新します。
代表的なコーチはこの2人です。
SGD(確率的勾配降下法)
- 特徴: 基本に忠実で、一歩ずつ着実に進む真面目なコーチ。
- 例え: 山登りで、足元の傾斜だけを見て慎重に一歩ずつ降りていくスタイル。
Adam(アダム)
- 特徴: 今一番人気のある天才肌のコーチ。過去の移動スピードなどを考慮して、歩幅を自動調整してくれます。
- 例え: 平坦な道では走り、急な崖では慎重になる、慣性制御つきのハイテクスニーカー。
- おすすめ: 迷ったらとりあえず
Adamを使っておけば間違いありません。
3. コードで見る「反省会」の流れ
では、実際に「損失関数」と「最適化」を定義して、パラメータを更新するコードを書いてみましょう。
import torch
import torch.nn as nn
import torch.optim as optim
# 1. 簡単なモデルを作る(重み1つだけの単純な層)
model = nn.Linear(1, 1)
# 2. 採点係を用意(今回は数値を当てるのでMSELoss)
criterion = nn.MSELoss()
# 3. コーチを用意(Adamコーチにお願いする)
# lr=0.01 は「学習率」。一回の反省でどれくらい値を修正するかの「歩幅」です。
optimizer = optim.Adam(model.parameters(), lr=0.01)
# --- ここからが学習の1ステップ ---
# ダミーの入力と正解データ
input_data = torch.tensor([1.0])
target = torch.tensor([3.0]) # 正解は3
# 予測する
output = model(input_data)
# 採点する(損失の計算)
loss = criterion(output, target)
print("誤差:", loss.item())
# 反省の準備(前の計算のゴミが残っていることがあるのでリセット)
optimizer.zero_grad()
# どこを直せばいいか計算(バックプロパゲーション)
loss.backward()
# パラメータを更新(実際に修正する)
optimizer.step()
このコードの後半部分、特に optimizer.zero_grad() 、 loss.backward() 、 optimizer.step() の3行は、AI学習における「三種の神器」のような呪文です。
- zero_grad:リセット!
- backward:計算!
- step:更新!
このリズムを覚えておいてください。どんなに複雑なAIでも、この手順は変わりません。
メリットとデメリット
メリット
- 自動化: 複雑なパラメータ更新の計算式を自分で書かなくて済みます。
- 切り替え簡単: 「今日はSGD、明日はAdam」といった変更が、コードを1行書き換えるだけで済みます。
- 学習率の調整:
lr(学習率)という数字を変えるだけで、学習のスピードをコントロールできます。
デメリット
- 選び方が難しい: 損失関数やオプティマイザには種類が多く、「どのタスクにどれを使えばいいか」を知っておく知識が必要です。
- 学習率の罠: 学習率(
lr)が大きすぎると修正しすぎて暴走し、小さすぎるといつまで経っても学習が終わらないことがあります。この調整は職人技に近い部分があります。
今後の学習の指針
お疲れ様でした!
第5章では、AIが賢くなるための核心部分である「損失関数」と「最適化」について学びました。
- 損失関数は、AIの間違いを採点する先生。
- 最適化(オプティマイザ)は、間違いをもとにパラメータを修正するコーチ。
zero_grad、backward、stepの3ステップで学習が進む。
さあ、これで全てのパーツが揃いました。
- 環境(Colab)
- データ(Tensor, DataLoader)
- モデル(nn.Module)
- 学習の仕組み(Loss, Optimizer)
次回、「第6章:学習ループの実装」では、これら全てを合体させます!
バラバラだった部品を組み立てて、実際にAIがデータを読み込み、学習し、どんどん賢くなっていく「学習ループ」を完成させましょう。
ここを乗り越えれば、あなたはもうAIエンジニアの卵です。
全ての知識がつながる瞬間!PyTorchで「学習ループ」を回そう
ついにここまで来ましたね。第6章は、これまでに学んだ全ての知識を総動員するパートです。
第1章から第5章まで、私たちはAIを作るための「部品」を一つずつ集めてきました。
環境、テンソル、モデル、データローダー、損失関数、そしてオプティマイザ。
これらは、料理で言えば調理器具や食材です。すべて揃っていますが、まだ料理(学習)は始まっていません。
今回は、これらの部品を組み合わせて、実際にAIに学習させるプログラム、「学習ループ」を書き上げます。
ここが動けば、あなたのPCの中でAIが産声を上げ、成長を始めます。最高にワクワクする瞬間ですよ!
1. 学習ループ=AIの特訓メニュー
学習ループとは、AIに「問題を解く→答え合わせをする→反省する」というサイクルを何度も繰り返させるプログラムのことです。
このサイクルを回す回数の単位を「エポック(Epoch)」と呼びます。
- 1エポック:用意した問題集(データセット)を、最初から最後まで一通り解き終わること。
人間も、問題集を1周しただけでは覚えきれませんよね?2周、3周と繰り返すことで、定着していきます。AIも同じで、データを何回も繰り返し見ることで、少しずつ賢くなっていきます。
2. 学習の方程式
プログラムを書く前に、ループの中でやることを整理しましょう。この手順は、どんな最先端のAIでも変わりません。
- データをもらう(DataLoaderから)
- 予測する(Modelにデータを通す)
- 間違いを計算する(Lossを計算)
- リセットする(前の計算の残骸を消す)
- 原因を探る(バックプロパゲーション)
- 修正する(パラメータを更新)
たったこれだけです。前回学んだ「三種の神器」も入っていますね。
3. 実装!これが学習ループだ
では、実際にコードを書いてみましょう。
ここでは分かりやすくするために、小さなデータとシンプルなモデルを使います。
以下のコードをGoogle Colabにコピーして実行してみてください。
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
# 1. データの準備(入力xと正解y)
# x: 0から9までの数字
x = torch.tensor([[float(i)] for i in range(10)])
# y: xに2を掛けた数字(AIにはこれを当てさせる)
y = torch.tensor([[float(i * 2)] for i in range(10)])
# データセットとデータローダーを作成
dataset = TensorDataset(x, y)
dataloader = DataLoader(dataset, batch_size=2, shuffle=True)
# 2. モデルの作成(入力1つ、出力1つのシンプルな層)
model = nn.Linear(1, 1)
# 3. 損失関数と最適化手法の準備
criterion = nn.MSELoss() # 誤差を測る定規
optimizer = optim.SGD(model.parameters(), lr=0.01) # 更新するコーチ
# --- いよいよ学習ループの開始! ---
# 全データを50周させる
num_epochs = 50
for epoch in range(num_epochs):
total_loss = 0 # このエポックの誤差合計
for inputs, targets in dataloader:
# 手順1:リセット(勾配の初期化)
optimizer.zero_grad()
# 手順2:予測(順伝播)
outputs = model(inputs)
# 手順3:間違いを計算(損失の計算)
loss = criterion(outputs, targets)
# 手順4:原因を探る(逆伝播)
loss.backward()
# 手順5:修正する(パラメータ更新)
optimizer.step()
# 誤差を記録しておく
total_loss += loss.item()
# 10周ごとに経過を表示
if (epoch + 1) % 10 == 0:
print(f'エポック {epoch+1}: 誤差 = {total_loss:.4f}')
実行すると、画面に文字が出てきましたか?
「誤差」という数字に注目してください。最初は大きかった数字が、エポックが進むにつれてどんどん小さくなっていれば大成功です!
それは、AIが「入力された数字を2倍すれば正解になるんだ!」という法則を、自力で見つけ出した証拠です。
4. 学習結果を確認してみよう
本当に賢くなったのか、テストしてみましょう。
学習が終わったモデルに、「5」という数字を見せてみます。正解の「10」を答えられるでしょうか?
# テストデータを作成
test_input = torch.tensor([[5.0]])
# モデルに予測させる
prediction = model(test_input)
print(f'5を入れたときの予測値: {prediction.item():.2f}')
どうですか?「9.98」や「10.02」など、限りなく「10」に近い数字が出ましたか?
おめでとうございます!あなたは今、手元のPCで「2の掛け算」を学習するAIを生み出しました。
メリットとデメリット
メリット
- テンプレート化できる: 上記のループの形は、画像認識でも自然言語処理でも、基本的には同じです。一度書けるようになれば、どこでも通用します。
- 成長が見える: 誤差(Loss)が減っていく様子を見るのは、RPGでレベル上げをしているような快感があります。
デメリット
- 時間がかかる: データが多かったりモデルが複雑だったりすると、学習が終わるまでに数時間〜数日かかることもあります。
- 過学習の恐れ: 問題集を覚えすぎてしまい、見たことのない新しい問題(テスト)が解けなくなることがあります。これを防ぐ工夫も奥が深いです。
今後の学習の指針
お疲れ様でした!
第6章では、これまでの知識を統合して「学習ループ」を実装しました。
- エポックとは、教科書を繰り返す回数のこと。
- ループの中で「予測・採点・修正」を繰り返すことでAIは賢くなる。
- Loss(誤差)が減っていくことが、学習成功の証。
ここまでくれば、あなたはもう立派なPyTorchユーザーです。
しかし、数字の予測だけでは少し地味ですよね?
次回、ついに最終回。「第7章:実践!画像分類モデルの構築」 です。
手書きの数字(画像)を読み取って、「これは3だ!」「これは7だ!」と判別する、本格的な画像認識AIを作ります。
これまで学んだ全ての技術を使って、AI開発の集大成を作り上げましょう。感動のフィナーレが待っていますよ!
【完結編】自分の手で作る感動!PyTorchで「手書き数字」を読み取るAIを作ろう
ついに、この連載も最終回を迎えました。第1章でGoogle Colabを開いたときのこと、覚えていますか?あのときは真っ白な画面に戸惑っていたかもしれません。
でも今のあなたは違います。テンソルを操り、自動微分の仕組みを知り、学習ループを回すことができます。
今回は、その全てのスキルを総動員して、AI開発の登竜門である「MNIST(エムニスト)」に挑戦します。これは、人の手書き数字(0から9)の画像を読み取って、どの数字が書かれているかを当てるAIです。
自分が作ったプログラムが、未知の画像を見て「これは7です!」と正解する瞬間。この感動を味わうために、私たちはここまで頑張ってきたのです。
さあ、最後の仕上げに取り掛かりましょう!
1. データの準備:torchvisionを使おう
今回は画像データを扱いますが、自分で何万枚も写真を撮る必要はありません。PyTorchには torchvision という、画像処理に特化した便利な相棒がいます。ここからMNISTデータをダウンロードします。
以下のコードを実行してみてください。
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
# 画像をAIが読めるテンソルに変換する設定
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
# 訓練用データのダウンロード
train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
# テスト用データのダウンロード
test_dataset = datasets.MNIST(root='./data', train=False, download=True, transform=transform)
# データローダーの作成
train_loader = DataLoader(dataset=train_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(dataset=test_dataset, batch_size=64, shuffle=False)これで、6万枚の訓練データと1万枚のテストデータが一瞬で準備できました。
MNISTの画像は、縦 
つまり、 
2. モデルの構築:画像を入力できる形にする
次はモデル(脳)の設計です。
ここで一つポイントがあります。画像は四角い形(2次元)ですが、第3章で学んだ全結合層(Linear)は、一列に並んだデータ(1次元)しか食べられません。
そこで、四角い画像を1列の棒状に引き伸ばす「Flatten(フラットゥン)」という処理を挟みます。
- 入力:
個の数字(画像の全画素)
- 出力:
class DigitNet(nn.Module):
def __init__(self):
super().__init__()
# 画像を1列に伸ばすための部品
self.flatten = nn.Flatten()
# ニューラルネットワークの層
self.layer_stack = nn.Sequential(
nn.Linear(28*28, 128), # 784個の入力を128個の特徴にまとめる
nn.ReLU(), # 活性化関数
nn.Linear(128, 10) # 最後は0〜9の10種類に分類する
)
def forward(self, x):
x = self.flatten(x)
logits = self.layer_stack(x)
return logits
model = DigitNet()
これで、画像を受け取って「それがどの数字か」を判断する脳が完成しました。
3. 学習ループ:AIの特訓開始!
準備は整いました。第6章で学んだ学習ループを使って、AIを特訓しましょう。
今回は「分類」の問題なので、損失関数には「CrossEntropyLoss」を使います。
このコードを実行すると、AIが猛スピードで勉強を始めますよ。
# 損失関数と最適化手法
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 学習ループ(5周させる)
epochs = 5
print("学習開始!")
for epoch in range(epochs):
running_loss = 0.0
for images, labels in train_loader:
# 1. リセット
optimizer.zero_grad()
# 2. 予測
outputs = model(images)
# 3. 誤差計算
loss = criterion(outputs, labels)
# 4. 逆伝播
loss.backward()
# 5. パラメータ更新
optimizer.step()
running_loss += loss.item()
print(f"エポック {epoch+1}: 完了 (誤差: {running_loss / len(train_loader):.4f})")
print("学習終了!")実行結果を見てください。エポックが進むごとに誤差が減っていれば、AIは順調に数字の特徴を掴んでいます。「丸い形があるから0かな?」「縦線だけだから1かな?」と、中で一生懸命考えているのです。
4. 運命のテスト:正解率は何%?
最後に、学習に使わなかった「テストデータ」を使って、実力を測りましょう。
初めて見る1万枚の画像を、どれくらいの精度で言い当てられるでしょうか?
correct = 0
total = 0
# テスト時は学習(勾配計算)をしないので torch.no_grad() を使う
with torch.no_grad():
for images, labels in test_loader:
outputs = model(images)
# 一番数値が高い(自信がある)数字を選ぶ
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f"正解率: {100 * correct / total:.2f}%")
どうでしたか?
おそらく、 
ほんの数行のコードで、人間と変わらないレベルで数字を認識できるAIが完成したのです。すごいことだと思いませんか?
メリットとデメリット
メリット
- 実用性が高い: 画像分類は、医療画像の診断や工場の不良品検知など、実際の社会で広く使われている技術の基礎です。
- 拡張性がある: 今回は単純なモデルでしたが、ここを「畳み込みニューラルネットワーク(CNN)」という技術に変えるだけで、カラー写真やもっと複雑な物体も認識できるようになります。
デメリット
- 中身がブラックボックス: AIがなぜ「これは3だ」と判断したのか、人間が理由を説明するのが難しい場合があります。
- データの偏りに弱い: もし「きれいな字」ばかりで学習させると、「汚い字」が読めないAIになってしまいます。
今後の学習の指針
全7回、本当にお疲れ様でした!
あなたはもう、PyTorchの基礎をマスターした立派なAIエンジニアの卵です。
これからさらにステップアップするためのキーワードをいくつか紹介しておきます。
- CNN(畳み込みニューラルネットワーク): 画像認識をもっと極めたいなら、次はこれです。
- RNN / Transformer: 「ChatGPT」のような、言葉を操るAIを作りたいならこの分野へ。
- Kaggle(カグル): 世界中のエンジニアがAIの精度を競い合うコンテストです。腕試しに最適です。
AIの世界は日進月歩で、毎日新しい技術が生まれています。でも、基礎となる「テンソル」「モデル」「学習ループ」の仕組みは変わりません。この連載で学んだ知識があれば、どんな新しい技術もきっと理解できるはずです。
あなたの作ったAIが、いつか世界を驚かせる日が来ることを楽しみにしています。
それでは、長い間お付き合いいただき、本当にありがとうございました!