
1. アルゴリズムの基本概念の解説
1.1 アルゴリズムとは何か?
アルゴリズムとは、ある問題を解決する手順や方法のことです。
具体的には、入力として与えられたデータを処理して、出力として求めたい結果を得るための手続きのことです。
例えば、以下はユーザーがキーボードから入力する2つの数の合計をコンソールに出力するアルゴリズムをJavaで実装したものです。
import java.util.Scanner;
public class AddTwoNumbers {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
int num1 = scanner.nextInt();
int num2 = scanner.nextInt();
int sum = num1 + num2;
System.out.println(sum);
scanner.close();
}
}アルゴリズムは、コンピュータ科学だけではなく、数学、物理学、生物学、経済学などあらゆる分野で広く用いられています。
また、もっと身近な例では料理のレシピも一種のアルゴリズムであるといえます。
アルゴリズムは、以下のような特徴を持っています。
- 求解性:問題を解決するための手順であることが必要。
- 有限性:有限回の手続きによって終了することが保証されている。
- 効率性:少ない計算資源(CPUやメモリ)で正しい結果を得ることができることが望ましい。
例えば、1から100までの合計を求めるときに1+2+3+...+100として求めることができます。
しかし、(1 + 100)+(2 + 99)+...(50 + 51)のように101を50回足すという計算で5050と求めたほうが効率的です。
同じ問題を解く場合でもアルゴリズムが異なれば処理速度が大きく異なる場合があるということになります。
それゆえ、アルゴリズムは、コンピュータプログラムを作成するために重要な要素です。
2 探索アルゴリズム
探索アルゴリズムとは、あるデータセット内で目的のデータを探索するためのアルゴリズムのことです。
データセットとは、例えば配列がそうですが、データを格納するためのデータ構造のことです。
ここでは、以下の3つの探索について解説します。特に1から3と変化するにつれて計算量が少なくなることを示したいと思います。
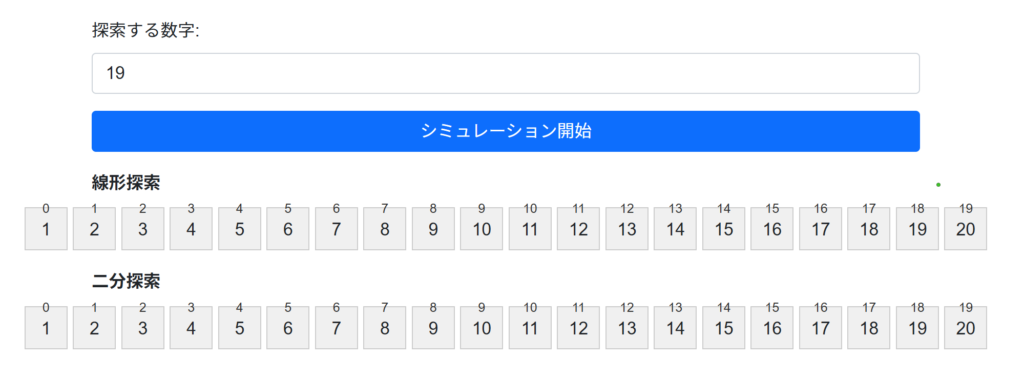
1.線形探索【Linear Search】
データセットを先頭から順番に比較して、目的のデータを探索するアルゴリズムです。データセットが整列されていない場合に有効ですが、データセットが大きくなると計算量が増加するため、効率的とは言えません。
2.二分探索【Binary Search】
データセットが整列されている場合に有効なアルゴリズムで、データセットを半分ずつ分割して目的のデータを探索します。探索範囲が狭まるため、線形探索に比べて効率的です。
3.ハッシュ探索【Hash Search】
ハッシュテーブルを用いてデータを探索するアルゴリズムです。ハッシュ関数を用いてデータの格納位置を計算し、その位置にデータが存在するかどうかを判定します。ハッシュ関数の選択が重要となります。
2.1 線形探索
講師の説明を受けて、あなたが他者に線形探索のアルゴリズムを説明する準備を以下にしなさい。
| ノート |
線形探索のJavaプログラムの例
import java.util.Scanner;
public class LinearSearch {
public static void main(String[] args) {
int[] dataset = {5, 1, 2, 8, 55, 13, 21, 34, 89, 3};
Scanner scanner = new Scanner(System.in);
System.out.print("検索する値を入力してください: ");
int target = scanner.nextInt();
scanner.close();
// 探索結果を保存するための変数(見つからない場合は -1)
int index = -1;
// メソッドを使わず、ここで直接ループを回して探す
for (int i = 0; i < dataset.length; i++) {
if (dataset[i] == target) {
index = i; // 見つかったらインデックスを保存
break; // 見つかったのでループを抜ける
}
}
// 結果の表示
if (index == -1) {
System.out.println(target + " は見つかりませんでした。");
} else {
System.out.println(target + " は、" + index + " 番目に見つかりました。");
}
}
}2.2 二分探索
講師の説明を受けて、あなたが他者に二分探索のアルゴリズムを説明する準備を以下にしなさい。
| ノート: |
二分探索のJavaプログラムの例
import java.util.Scanner;
public class BinarySearch {
public static void main(String[] args) {
int[] dataset = { 1, 2, 3, 5, 8, 13, 21, 34, 55, 89 };
Scanner scanner = new Scanner(System.in);
System.out.print("検索する値を入力してください: ");
int target = scanner.nextInt();
// ここから探索ロジックを直接記述
int index = -1; // 見つからなかった場合の初期値
int low = 0;
int high = dataset.length - 1;
while (low <= high) {
int mid = (low + high) / 2;
if (dataset[mid] == target) {
index = mid; // 見つかったのでインデックスを保存
break; // ループを抜ける
} else if (dataset[mid] < target) {
low = mid + 1;
} else {
high = mid - 1;
}
}
// ここまで
if (index == -1) {
System.out.println(target + " は見つかりませんでした。");
} else {
System.out.println(target + " は、" + index + " 番目に見つかりました。");
}
scanner.close();
}
}Arrays.binarySearchメソッド
Javaで二分探索するには以下のArrays.binarySearchメソッドが便利です。値が存在する場合にはその添字が、値が存在しない場合はマイナスの値が返ります。ただし、整列済みのデータに対してしか有効に働かないのでその点は注意しましょう。
import java.util.Arrays;
import java.util.Scanner;
public class ArraysbinarySearchExample {
public static void main(String[] args) {
int[] data = { 1, 2, 3, 5, 8, 13, 21, 34, 55, 89 };
Scanner scanner = new Scanner(System.in);
System.out.print("検索する値を入力してください: ");
int target = scanner.nextInt();
scanner.close();
int index = Arrays.binarySearch(data, target);
if (index < 0) {
System.out.println(target + " は見つかりませんでした。");
} else {
System.out.println(target + " は、" + index + " 番目に見つかりました。");
}
}
}参考リンク
2.3 ハッシュ探索
講師の説明を受けて、あなたが他者にハッシュ探索のアルゴリズムを説明する準備を以下にしなさい。

以下のプログラムでは、配列を使用してハッシュテーブルにデータを格納し、データの衝突が起こった際にオープンアドレス法を使用して解決するプログラムです。
ハッシュ関数は簡単に計算できるように、データを5で割った余りとします。
オープンアドレス法では、衝突が起こった場合、次の空いている位置にデータを挿入します。
ハッシュ探索のJavaプログラムの例
import java.util.Scanner;
public class HashTableOpenAddressingExample {
public static void main(String[] args) {
// ハッシュテーブルを作成
int[] hashTable = new int[5];
// データをハッシュテーブルに格納(オープンアドレス法)
int[] dataset = { 1, 2, 3, 5, 8 };
for (int i = 0; i < dataset.length; i++) {
int key = dataset[i] % 5;
while (hashTable[key] != 0) {
key = (key + 1) % 5;
}
hashTable[key] = dataset[i];
}
// ハッシュテーブルを表示
System.out.println("ハッシュテーブル:");
for (int i = 0; i < hashTable.length; i++) {
System.out.println("キー: " + i + ", 値: " + hashTable[i]);
}
// ハッシュテーブルからデータを検索
Scanner scanner = new Scanner(System.in);
System.out.print("検索する値を入力してください: ");
int searchValue = scanner.nextInt();
scanner.close();
int searchKey = searchValue % 5;
while (hashTable[searchKey] != searchValue) {
searchKey = (searchKey + 1) % 5;
}
int value = hashTable[searchKey];
System.out.println(searchKey + "番目の配列に" + value + "が見つかりました。");
}
}※上記プログラムは5つ以上の要素を扱うと無限ループになるなど不完全な部分があります。
3. 計算量理論
3.1 ビッグオー記法
ビッグオー記法とは、データ量(n)が大きくなるにつれて、処理にかかる計算量(時間やステップ数)がどのように増加するかを表す記法です。
線形探索、二分探索、ハッシュ探索それぞれのアルゴリズムの性能について以下で解説します。
線形探索は、データ構造内の全ての要素を順番に比較していくため、最悪の場合にはn個の要素を全て比較する必要があります。そのため、時間計算量はO(n)となります。探索対象のデータが少量の場合や、データ構造が未整列の場合に有効です。
二分探索は、データ構造が整列していることが前提となります。探索対象となるデータを中央の要素と比較し、探索範囲を半分に狭めていくことで探索を行います。一度の比較で探索範囲を半分にできるため、最悪の場合でもlog n回の比較で探索を終えることができます。そのため、時間計算量はO(log n)となります。探索対象のデータが多量にある場合に有効です。(ただし、前提としてデータ構造が整列されている必要があります)
ハッシュ探索は、ハッシュ関数によって探索対象のデータをハッシュ値に変換し、そのハッシュ値に対応するデータをO(1)の時間で取得する方法です。ハッシュ関数によって、探索対象のデータが格納されている場所を直接特定するため、探索の必要がある要素数にかかわらず、一定の速度でデータを取得することができます。しかし、異なるデータが同じハッシュ値を持つ場合には、衝突が発生し、探索に時間がかかる場合があります。その場合は、衝突を避けるための方法を考える必要があります。(さらに、最初にハッシュテーブルを作成する時間もかかります。)
オーダーの観点から以下の表に各アルゴリズムの時間計算量を示します。
| 探索アルゴリズム | 時間計算量 |
|---|---|
| 線形探索 | O(n) |
| 二分探索 | O(log n) |
| ハッシュ探索 | O(1)(平均) |
| バブルソートや選択ソート(後述) | O(n^2) |
講師が時間計算量のグラフを書きますのでメモしてください。
| ノート: |
指数と対数
指数と対数は大きな数を扱うのに便利なように開発された数学のテクニックです。例えば、1,000,000,000という数値は10⁹と書けば3つの数字で表現できますね。
指数 【Exponents】
指数は、ある数を何回かけるかを簡潔に表す方法です。例えば、2⁸は (2*2*2*2*2*2*2*2 = 256) という意味です。ここで、2 は「底」、8は「指数」と呼ばれます。
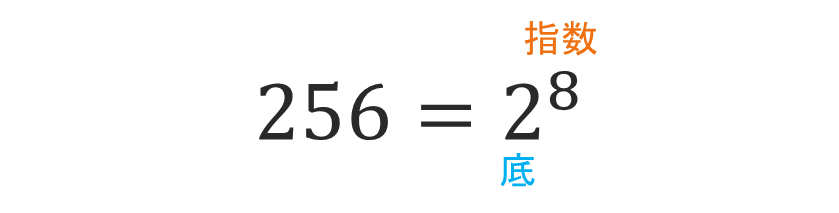
対数【Logarithms】
対数は指数の逆の操作を表します。つまり、ある数が別の数の何乗であるかを表します。対数の表記は、以下のとおりです。
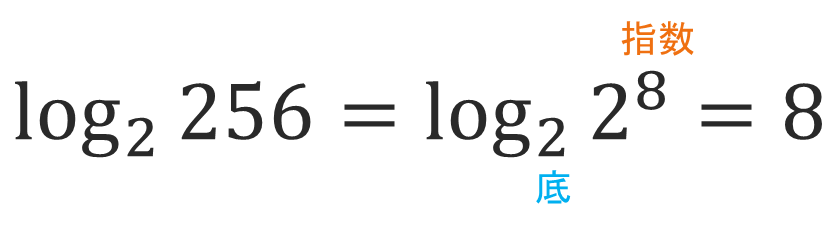
例えば、(2^8 = 256) は指数の例です。これを逆に対数で表すと、(log₂ 256 = 8) となります。つまり、2を8乗すると256になる、または、2の何乗で256になるかというと8乗である、ということを意味しています。
以上のように、探索アルゴリズムにはそれぞれ特徴があり、用途に応じた適切なアルゴリズムを選択する必要があります。
線形探索はシンプルで実装が容易ですが、データ量が増えると計算量が増大するため、大規模なデータには向いていません。
二分探索は、データ構造が整列されている場合には高速に探索を行えますが、データ構造が未整列の場合には事前に整列する必要があります。
ハッシュ探索は、ハッシュ関数によってデータの格納場所を直接特定するため、一定の時間で探索が終了することが期待できますが、衝突が発生した場合には処理が遅くなる場合があります。
それぞれのアルゴリズムを理解して、用途に応じた適切なアルゴリズムを選択することが大切です。
4. ソートアルゴリズム
ソートとは、並べ替えのことです。(そうとも言う(^^))
ここでは、2つのソート方法をお伝えします。ただし、ここでお伝えするアルゴリズムはいずれも高速なソートとはいえませんのでデータ量や用途によっては適さないことがあります。大量のデータを高速に並べ替えたい場合にはここには紹介されていないクイックソートなどを使う必要があります。
ソートには昇順(文字コードの小さい順)と降順(文字コードの大きい順)があります。ここでは、昇順で解説します。
また、Javaの場合は以下の一文で並べ替えができますので、わざわざ自分で実装する必要はありません。(しかも、Dual-Pivot Quicksortという高速なアルゴリズムです)
Arrays.sort(配列の変数);
サンプルプログラム
import java.util.Arrays;
public class SortExample {
public static void main(String[] args) {
int[] data = {5, 1, 2, 8, 55, 13, 21, 34, 89, 3};
Arrays.sort(data);
for (int i = 0; i < data.length; i++) {
System.out.print(data[i] + " ");
}
}
}ここでは、比較的低速ながらアルゴリズムが理解しやすい、バブルソート、選択ソートを紹介します。
4.1 バブルソート
バブルソートは、隣り合った要素の大小関係を比較しながら、交換を繰り返すことで、配列全体を昇順または降順に並び替えるアルゴリズムです。別名、隣接交換法とも言います。
具体的には、配列の先頭から順に隣り合った2つの要素を比較し、順序が逆であれば交換します。この比較と交換を配列の末尾まで繰り返します。この一連の処理で最大値が末尾に移動するため、次のループでは、末尾を除いた残りの部分を対象として同様の処理を繰り返します。これを、配列全体が昇順または降順に並び替えられるまで繰り返します。
バブルソートは、比較回数が多く、効率が悪いアルゴリズムです。しかし、実装が簡単であるため、小規模なデータの並び替えには適しています。
講師の説明を受けて、あなたが他者にこのアルゴリズムを説明する準備を以下にしなさい。
| ノート: |
バブルソートのJavaプログラムの例
public class BubbleSort {
public static void main(String[] args) {
int[] data = {5, 1, 2, 8, 55, 13, 21, 34, 89, 3};
for (int i = 0; i < data.length - 1; i++) {
for (int j = 0; j < data.length - 1 - i; j++) {
if (data[j] > data[j+1]) {
int temp = data[j];
data[j] = data[j+1];
data[j+1] = temp;
}
}
}
for (int i = 0; i < data.length; i++) {
System.out.print(data[i] + " ");
}
}
}バブルソートの平均時間計算量: O(n^2)
バブルソートは、各要素を他の要素と比較して並べ替えを行うため、全体の要素数が n の場合、平均的には n-1 回の走査を行います。各走査では、最大の要素が配列の末尾に移動することが保証されますが、各要素を比較して交換するため、n-1 回の比較と交換が行われます。
したがって、平均的には、n-1 回の走査でそれぞれ n-1 回の比較と交換が行われるため、(n-1)(n-1) = n^2 -2n + 1となり、全体として O(n^2) の時間がかかります。
ビッグオー記法では、指数の1番大きい項だけを考えます。
例えば、O(n^3 + n^2 + n) という表記は、n が非常に大きな値を取る場合、n^3 に対して n^2 や n は比較的小さいため、計算量の主要な部分は n^3 であると判断することができます。したがって、アルゴリズムの最悪計算量は O(n^3) となります。
指数の1番大きい項だけを考えることで、アルゴリズムの計算量を簡単に見積もることができると同時に、計算量の大まかなオーダーを求めることができます。ただし、ビッグオー記法によるアルゴリズムの計算量の見積もりは、アルゴリズムの実行速度を正確に測定するものではありません。
4.2 選択ソート
選択ソートは、配列の中から最小値または最大値を選び、その値を配列の先頭と交換することで、配列全体を昇順または降順に並び替えるアルゴリズムです。
具体的には、配列の先頭から順に、未ソート部分の中から最小値または最大値を探し、先頭の要素と交換します。その後、次の未ソート部分から最小値または最大値を探し、それを先頭の次の要素と交換します。このように、未ソート部分がなくなるまで、配列の要素を選択して並び替えます。
選択ソートは、比較回数がバブルソートよりも少なく、データ移動回数も少ないため、中程度の大きさの配列のソートには適しています。
講師の説明を受けて、あなたが他者にこのアルゴリズムを説明する準備を以下にしなさい。
| ノート: |
選択ソートのJavaプログラムの例
public class SelectionSort {
public static void main(String[] args) {
int[] data = {5, 1, 2, 8, 55, 13, 21, 34, 89, 3};
for (int i = 0; i < data.length - 1; i++) {
int minIndex = i;
for (int j = i + 1; j < data.length; j++) {
if (data[j] < data[minIndex]) {
minIndex = j;
}
}
int temp = data[minIndex];
data[minIndex] = data[i];
data[i] = temp;
}
for (int i = 0; i < data.length; i++) {
System.out.print(data[i] + " ");
}
}
}選択ソートは、平均時間計算量: O(n^2)です。
次回は、「テスト技法を知りソフトウェア品質を高める」を学びます。
