
1. ソフトウェアとは?
1.1 ソフトウェアの定義
「コンピュータ、ソフトなければただの箱」
という言葉があるようにソフトウェアは、コンピュータが特定のタスクを実行するために必要不可欠な命令の集まりです。
これらの命令は、通常はプログラミング言語で書かれ、コンピュータが理解し実行できるようにコンパイル(編集)またはインタープリテーション(通訳)されます。ソフトウェアはハードウェアが具体的な作業を行うための「手順書」のようなものであり、ハードウェアの能力を活用してユーザーが望む機能を提供します。
1.2 ソフトウェアの主な種類
システムソフトウェア
コンピュータシステムの基本的な機能を制御・運用するためのソフトウェアで、オペレーティングシステム(OS)、デバイスドライバ、ユーティリティソフトウェア、ミドルウェアなどが含まれます。オペレーティングシステムとして、この研修ではWindowsを、ミドルウェアとしてデータベース管理システムのMySQLを使います。
アプリケーションソフトウェア
応用ソフトとも呼ばれ、ユーザーが特定のタスクを遂行するためのソフトウェアで、ワープロソフトウェア、表計算ソフトウェア、画像編集ソフトウェア、ウェブブラウザ、ゲームなどがあります。この研修でもパワーポイントでプレゼンテーションをする機会があります。
プログラミングソフトウェア
ソフトウェア開発者が新しいアプリケーションやシステムを作成するためのツールで、コンパイラ、インタープリタ、テキストエディタ、統合開発環境(IDE)などが含まれます。この研修でも統合開発環境のEclipseを使っていきます。
ネットワークソフトウェア
データ通信とネットワークリソースの管理を行うソフトウェアで、ファイアウォール、ルーターのOS、ネットワーク管理ツールなどがあります。
上記のカテゴリーは多少重なる部分もあり、また多くのソフトウェアは複数のカテゴリーにまたがっていることもあります。また、これらのカテゴリーに含まれない特殊なソフトウェアも存在します。ソフトウェアの開発は絶えず進化しており、新しい技術と新しいニーズに対応するために新しい種類のソフトウェアが常に生まれています。
2. なぜソフトウェアの仕組みを理解することが重要なのか?
ソフトウェアの仕組みを理解することは、以下のような理由で重要です。
トラブルシューティングと問題解決
ソフトウェアがどのように動作しているかを理解していれば、何か問題が発生したときにその原因を追求し、適切な解決策を見つけることができます。コードの一部やシステム全体が期待通りに動作しない場合、その背後にある原理を理解していると、問題の特定と修正がより迅速に行えます。
効率的なコード作成
ソフトウェアの基本的な仕組みを理解していると、より効率的でパフォーマンスの良いコードを書くことが可能になります。例えば、メモリ管理や並行処理の原理を理解していると、これらの要素を適切に利用してコードの速度を最適化することができます。
高品質なソフトウェア開発
ソフトウェアの仕組みを理解することは、安全で信頼性の高いソフトウェアを開発するためにも重要です。例えば、セキュリティやデータ保護の原則を理解していると、これらの要素をソフトウェア設計に組み込むことができます。
学習と成長
ソフトウェアの仕組みを理解することは、新しい技術やフレームワークを学ぶ上での基礎となります。ソフトウェアの基本的な仕組みについて理解していれば、新たな知識を既存の知識に関連付けて理解し、応用することが容易になります。
これらの理由から、ソフトウェアの仕組みを理解することは、エンジニアとして成功するための重要な要素といえます。
3. ソフトウェアの基本
3.1 ソフトウェアはプログラムから作られる
プログラムはprogramと書きますね。
これは、「pro = 前もって」、「gram = 書かれたもの」という意味です。
つまり、プログラムは、コンピューターが特定のタスクを実行するために予め書かれた指示書です。指示書はプログラミング言語を用いて記述され、それぞれの言語は異なる文法と命令セットを持っています。プログラムは、簡単な計算から複雑なビジネスロジックまで、様々なタスクをコンピューターに命じるために使用されます。
プログラムは以下の要素で構成されています。
- 変数【Variables】 - データを格納するための場所。変数は名前を持ち、それによって参照されます。
- データタイプ【Data Types】 - 整数、浮動小数点数、文字列、ブール値など、扱うデータの種類を定義します。
- 演算子【Operators】 - データに対する演算(足し算、引き算、掛け算、割り算など)を行うための記号。
- 制御構造【Control Structures】 - プログラムの流れを制御するための構造。条件分岐(if、else)、ループ(for、while)、ジャンプ(break、continue、return)などがあります。
- 関数/メソッド【Functions/Methods】 - 特定のタスクを実行するためのコードブロック。関数/メソッドは名前を持ち、パラメータを取ることができます。
- クラス【Classes】 - オブジェクト指向プログラミング言語では、クラスはオブジェクトの設計図として働きます。クラスはデータ(フィールド)とそれを操作するためのメソッドを持ちます。
プログラムはこれらの要素を組み合わせて、ユーザーの要求に応じて特定のタスクを実行します。コンピューターはプログラムの命令を一つずつ、上から下に向かって実行します。ただし、制御構造によりプログラムの実行順序は変わることもあります。
3.2 プログラミング言語の役割
エンジニアになった皆さんは、多かれ少なかれプログラミング言語を学ぶことになるでしょう。プログラミング言語はコンピュータに対する命令であり、その役割は非常に多岐にわたります。以下に5点、その主な役割を挙げます。
コミュニケーション手段
最も基本的な役割は、コンピュータとコミュニケーションすることです。つまり、コンピュータに対する命令を書くことです。エンジニアは特定のタスクを実行するプログラムを作成します。また、プログラミング言語はコンピュータと人間、または人間同士のコミュニケーション手段でもあります。
抽象化
プログラミング言語は、複雑なシステムやプロセスを抽象化する役割も果たします。抽象化することにより、開発者は具体的な実装の詳細を気にすることなく、より高いレベルでプログラムを理解し、操作することができます。例えば、Javaで「System.out.println("コンソール出力したい文字列")」と書けば、そのときに標準出力になっているハードウェアに出力することができます。一般的な標準出力はディスプレイです。しかし、エンジニアはディスプレイの仕組みを知らなくても良いのです。つまり、抽象化とはブラックボックス化であるといえるでしょう。
問題解決
プログラミング言語は、特定の問題を解決するための手段でもあります。特定の問題領域やタスクに特化したプログラミング言語(ドメイン特化言語とも呼ばれます)は、その問題を効率的に解決するための専門的なツールとなります。例えば、当社の研修ではデータベース管理システムを扱いますが、SQL【Structured Query Language】はデータベースの操作に使用されるドメイン特化言語で、簡単な記述でデータの検索、挿入、更新、削除などを行うための命令です。
機械とのインターフェース
プログラミング言語は、開発者がハードウェアと直接対話するためのインターフェースの役割も果たします。開発者はメモリ管理、プロセッサの使用など、低レベルの操作を行うことができます。例えば、Javaでは、ガベージコレクション【garbage collection : GC】によってメモリ管理が自動的に行われます。GCの動作を理解することで、メモリリークを防いだり、無駄なメモリ使用を減らしたりすることが可能になります。
プログラムの構造化
プログラミング言語は、プログラムのコードを構造化する役割も果たします。構造化によりコードは読みやすく、理解しやすく、保守しやすくなります。
例えば、Javaを例にとってプログラムの構造と組織について説明してみましょう。Javaはオブジェクト指向プログラミング言語であり、その構造は主にクラスとオブジェクトによって定義されます。例えばこんな感じです。(コードの詳細を理解する必要はありません。必要に応じて別単元で学びます)
// ① パッケージ宣言(省略可能)
package com.example;
// ② インポート宣言(省略可能)
import java.util.ArrayList;
// ③ クラス宣言
public class MyClass {
// ④ フィールド宣言(省略可能)
private String myField;
// ⑤ コンストラクタ宣言(省略可能)
public MyClass(String myField) {
this.myField = myField;
}
// ⑥ メソッド宣言
public void myMethod() {
// Some code here...
}
// ⑦ メインメソッド(プログラムのエントリーポイント。全てのクラスに必要というわけではない)
public static void main(String[] args) {
MyClass myObject = new MyClass("Hello, World!");
myObject.myMethod();
}
}
- [パッケージ宣言]Javaのパッケージは関連するクラスやインターフェースを一緒にまとめるためのもので、名前空間を管理し、クラス名の衝突を防ぎます。
- [インポート宣言]Javaのプログラムは、Javaのコアライブラリや他のライブラリからクラスやインターフェースを利用するためにインポートします。
- [クラス宣言]Javaプログラムの中核となるのはクラスです。クラスはフィールド(データ)とメソッド(データを操作する機能)を持つことができます。
- [フィールド宣言]フィールドはクラスの状態を保持します。そのクラスのインスタンスが持つデータを定義します。
- [コンストラクタ宣言]コンストラクタは新しいオブジェクトを生成するときに呼び出されます。通常、コンストラクタはオブジェクトの初期状態を設定するために使われます。
- [メソッド宣言] メソッドはクラスの振る舞いを定義します。そのクラスのオブジェクトが行うことができる操作を定義します。
- [メインメソッド] Javaプログラムのエントリーポイントであるメインメソッドは、プログラムの実行を開始するためにJVMによって呼び出されます。
以上がJavaプログラムの基本的な構造です。
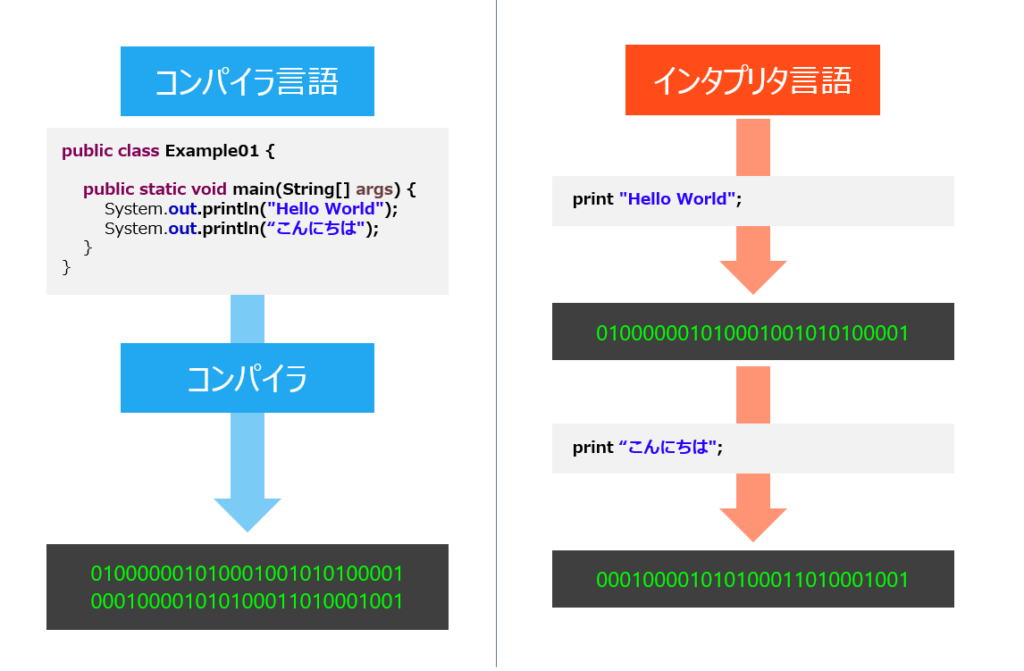
3.3 コンパイラとインタプリタの違い
コンパイラとインタプリタはどちらも、人間が理解しやすいプログラミング言語を機械が理解できる形(機械語またはマシン語)に変換するためのツールです。ただし、その変換方法や実行の流れに違いがあります。
英語の【compiler】には翻訳という意味があります。言葉通り一気にプログラムを機械語にしてしまいます。

一方、英語の【interpreter】には通訳者という意味があります。通訳者はその都度、セリフを通訳しますが、そのイメージが大事です。
コンパイラ
コンパイラはプログラミング言語のコード全体をまとめて、一度に機械語に変換します。【Compiler:翻訳者】と呼ばれるゆえんです。この変換後のコードは、元のソースコードとは別の実行可能ファイル(例えば、Windowsでは.exeファイル)となります。そのため、コンパイラを使用すると、変換した後であれば元のソースコードがなくてもそのプログラムを実行することが可能です。
コンパイラの主な特徴は以下の通りです。
- コンパイルには時間がかかることがありますが、一度コンパイルされたプログラムは高速に動作します。
- コンパイルは一度だけ行われ、その後は同じ実行可能ファイルを何度でも使うことができます。
- コード全体を見ることができるので、最適化が可能です。この結果、一般的には実行速度が早いです。
- エラーはコンパイル時に発見されます。つまり、すべてのエラーを解消しないとプログラムは実行されません。
Java、C、C++などの言語はコンパイラ型の言語としてよく知られています。
インタプリタ
インタプリタはプログラミング言語のコードを一行ずつ読み込み、その都度機械語に変換し、実行します。【Interpreter:通訳者】と呼ばれるゆえんです。プログラム全体を一度に変換する必要がなく、ソースコードが即座に実行可能になります。
インタプリタの主な特徴は以下の通りです。
- インタプリタ型のプログラムはコードが一行ずつ実行されるため、全体としてはコンパイラ型の言語よりも実行速度が遅いことがあります。
- ただし、一行ずつ実行されるため、開発中のテストやデバッグが容易になります。
- エラーはコードの該当行が実行される時点で発見されます。つまり、エラーがあるとその行でプログラムの実行が停止します。
JavaScript、Python、Rubyなどの言語はインタプリタ型の言語としてよく知られています。
以上のような特性を理解し、目的に合わせて適切なツールを選択することが重要です。
3.4 プログラムの基本制御構造
1960年代から1970年代にかけてソフトウェア開発が一般的になり大規模なプログラムが増え始めました。
その結果、スパゲティコード(スパゲティのように複雑に絡まりあったプログラム)がもたらす問題点が徐々に明らかになり、特に大規模なプロジェクトではソフトウェアの品質、保守性、信頼性に対する重大な問題を引き起こしました。これらの問題は、プロジェクトの遅延や予算オーバー、そして最悪の場合、プロジェクトの失敗につながることもありました。

エドガー・ダイクストラは、その有名な「GOTO文は害悪である【Go To Statement Considered Harmful】」という1968年のエッセイで、GOTO文によるスパゲティコードの問題を指摘しました。スパゲティコードとは具体的には「GOTO文の頻繁な使用」、「コードの重複」、「テストとデバッグの困難さ」といった特徴を持つコードのことです。
- 一般的に、GOTO文はプログラムの流れを任意の位置にジャンプさせるために使用されます。しかし、GOTO文が頻繁に使われると、プログラムの流れが非直線的で予測不可能になり、その結果、コードの可読性や保守性が大きく損なわれます。
- 同じコードが複数の場所で繰り返し書かれることがありました。これはコードの再利用性を低下させ、バグの発生を助長し、コードの変更を困難にするという問題を引き起こします。
- GOTO文の乱用とコードの重複により、プログラムの論理が複雑になると、テストとデバッグが困難になります。また、プログラムの流れが直感的でないため、新たな開発者が既存のコードを理解するのも難しくなります。
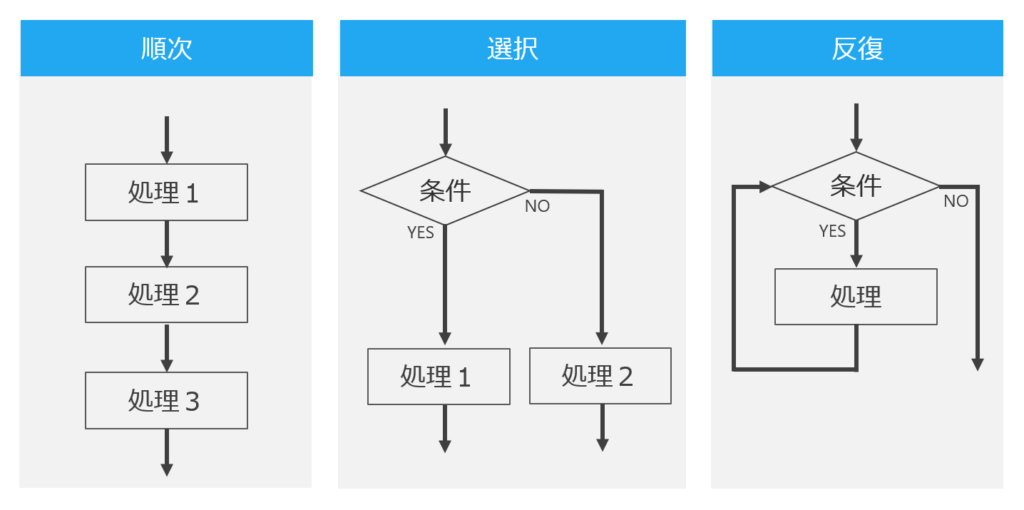
ダイクストラは、これらの問題を解決するために「構造化プログラミング」を提唱しました。これは、プログラムを理解しやすく、保守しやすいものにするための方法論で、順次、選択、反復という3つの基本制御構造を中心に据えています。構造化プログラミングは、現代のソフトウェア開発では基本中の基本と呼べるものです。
3つの基本制御構造は以下のとおりです。
- 順次【Sequence】は最も基本的な制御構造で、命令は上から順に一つずつ実行されます。すなわち、一つの命令が完了した後に次の命令が実行されます。
- 選択または条件分岐 【Selection】はプログラムの流れを制御するための構造で、一般的に
if-then-else構造として表されます。条件式が真【true】の場合はthenの部分が実行され、偽【false】の場合はelseの部分が実行されます。 - 反復またはループ 【Iteration】は一部のコードを反復的に実行するための構造で、一般的に
while,do-while,forなどの形をとります。ループは特定の条件が真【true】である間は繰り返され、その条件が偽【false】になった時点で終了します。
4. ソフトウェアのライフサイクル
ソフトウェアのライフサイクルは、ソフトウェア開発プロジェクトが誕生から廃止まで経る各ステージを指します。ソフトウェア開発の各フェーズは次のようになります。
要件定義
プロジェクトの開始フェーズで、開発者とクライアント(または利用者)が協力して、ソフトウェアが達成すべき目標や機能、性能基準を明確に定義するステップです。
ソフトウェア設計
要件が明確になったら、開発チームはそれを実現するためのソフトウェアの設計を行います。これには、ソフトウェアのアーキテクチャ、データ構造、インターフェース、モジュールなどが含まれます。
実装(コーディング)
設計フェーズが完了したあと、開発者は設計に基づいてソフトウェアを実際にコーディングします。このフェーズでは、設計されたコンポーネント(ソフトウェア部品)や機能がプログラムコードとして書かれます。
テスト
コーディングが完了すると、ソフトウェアはテストフェーズに入ります。このフェーズでは、バグの検出と修正、機能と性能の確認、予期しない問題やエラーの検出が行われます。
デプロイメント
テストフェーズが成功すると、ソフトウェアはクライアントの実環境にデプロイ(導入)されます。場合によっては、ステージング環境での最終テストが行われた後、本番環境にデプロイされます。
メンテナンス
デプロイメント後も、ソフトウェアは定期的にメンテナンスが必要となります。これには、バグ修正、機能追加、性能改善などが含まれます。
ソフトウェアのライフサイクルは、ソフトウェア開発の全体像を理解するのに役立つフレームワークです。(詳細はSDLCを知り全工程に関わるエンジニアになるという記事を参照下さい)
5. ライセンスの基本
ソフトウェアライセンスとは、ソフトウェア製品を使用するための法的許諾または契約です。この契約は、ソフトウェアの製作者(または所有者)とエンドユーザー(消費者または企業)の間で結ばれます。ライセンスは通常、ソフトウェアの利用範囲や制限、配布、修正、複製などの権利を定義します。
以下は、ソフトウェアライセンスの主な種類です。
パブリックドメイン
パブリックドメインのソフトウェアは、著作権のないソフトウェアで、誰でも自由に使用、変更、配布することができます。
オープンソース
オープンソースソフトウェアは、ソースコードが公開されており、誰でもそれを見たり、変更したり、自分の製品に組み込んだりすることができます。Apache LicenseやMIT Licenseなどが該当します。例えば、本研修で使用するEclipseはオープンソースです。
フリーソフトウェア
フリーソフトウェアは、ユーザーがソフトウェアを自由に使用が認められています。場合によっては、変更、共有(コピー)することをも認められているものもあります。例としては、GNU General Public License (GPL)があります。例えば、本研修で使用するMySQL WorkbenchはオープンソースでありGPLです。
プロプライエタリ
プロプライエタリソフトウェアライセンスは、ソフトウェアの使用を許諾する一方で、著作権はソフトウェアの製作者または配布者に帰属します。通常、ユーザーはソフトウェアのコピー、配布、修正を行う権利を持ちません。例えば、本研修で使用しているWindowsOSやエクセル、パワーポイントといったアプリケーションソフトはプロプライエタリソフトウェアライセンスです。

【proprietary】は土地や建物の所有権や所有物を表す【property】と語源的に近い言葉です。
ソフトウェアを使用する前には、そのライセンスを理解し、適切に使用することが重要です。ライセンス契約違反は法的な問題を引き起こす可能性があります。
6. トラブルシューティング
6.1 ソフトウェアトラブルシューティングの進め方
以下にソフトウェアトラブルシューティングの基本的なステップを示します。
問題の認識
最初のステップは、問題が何であるかを明確に認識することです。問題の症状は何か?何が正常で何が異常なのか?問題の再現手順は何か?これらの情報を収集し、問題を明確に定義します。
情報収集
問題に関連する可能性のある情報を収集します。エラーメッセージ、ログファイル、システムの状態、使用中のハードウェアやソフトウェアのバージョン等です。この時、できるだけ問題のある画面のキャプチャを取得しておくと他者に説明する際に便利です。
原因の特定
収集した情報を分析して問題の原因を特定します。これにはコードのレビュー、デバッグ、システム設定のチェック等が含まれます。しばしば問題の原因は複数の要素の組み合わせによって発生するため、全体の視点で問題を考えることが重要です。エラーメッセージをそのままグーグル検索にかけるのも有効です。世の中にはあなたと同じ問題に遭遇した人がいて、親切にその解決方法を解説してくれているものです。
仮説の設定と検証
問題の原因について仮説を設定し、それを検証します。一つの仮説が誤っていた場合、別の仮説を立てて検証を行います。このプロセスは反復的に行われます。
修正策の計画と実施
問題の原因を特定したら、修正策を計画します。修正策を実施する前に、それが新たな問題を引き起こさないか、または他の部分に影響を及ぼさないかを考慮します。修正策の実施は慎重に行い、可能であればその影響を最小限に抑える方法を選びます。
テストと検証
修正策を実施した後は、問題が解決したことを確認するためにテストを行います。問題が再発しないことを確認し、必要に応じて追加のテストを行います。
ドキュメンテーション
最後に、発生した問題とその解決策をドキュメントに記録します。同じ問題が再発した場合や、似たような問題が発生した場合に、既に見つけた解決策を再利用できるようになります。
これらのステップは一般的なものであり、具体的なトラブルシューティングの状況によって調整が必要な場合もあります。しかし、これらの基本的なプロセスを理解しておけば、多くのトラブルシューティングの状況で役立つでしょう。
実験
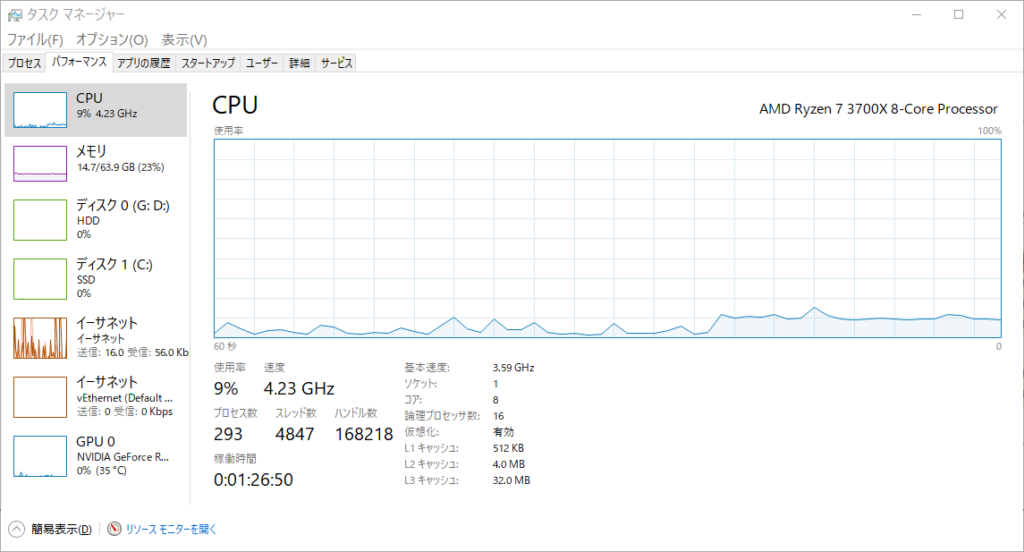
以下のプログラムは無限ループの中で乱数を発生させ、その値の正弦(sin)を求め続けます。当然、CPUの負荷は高くなります。(このコードの詳細を今は理解する必要はありません)
タスクマネージャー(ショートカットキー:Ctrl + Shift + Esc)を開いてからこのプログラムを実行してCPU使用率がどのように変化するかを観察しなさい。(プログラムの強制終了方法はコンソールの右の赤いアイコンを押すことです)
public class HighCpuUsage {
public static void main(String[] args) {
while (true) {
double x = Math.sin(Math.random());
}
}
}
実験
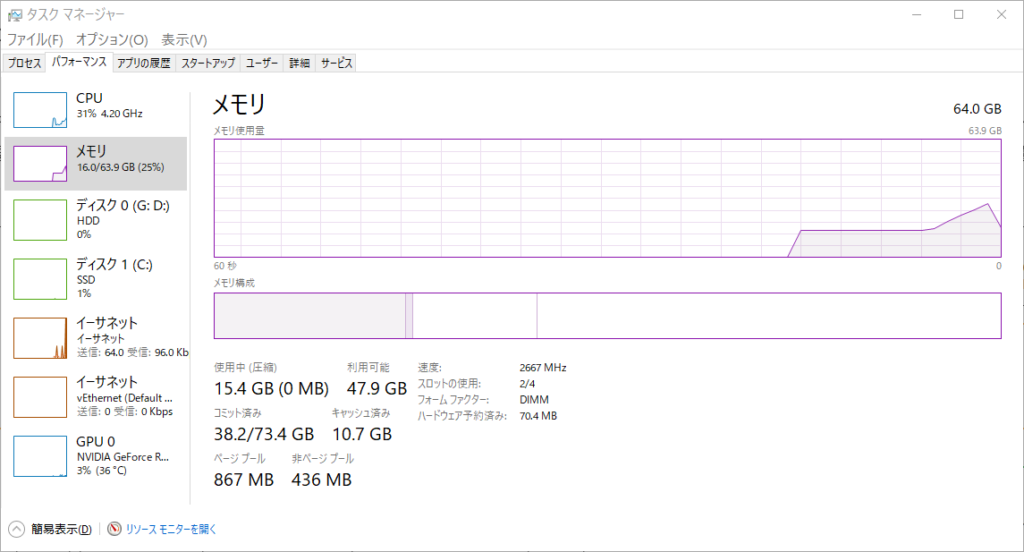
以下のプログラムは無限ループの中で100 MBのバイト配列を生成し、リストに追加し続けます。やがてメモリが使いつくされてエラーが発生します。
タスクマネージャーを開いたままで、このプログラムを実行してメモリ使用率がどのように変化するかを観察しなさい。
また、コンソールに出力されるエラー(正確には例外といいます)のメッセージを読み解いてください。
import java.util.ArrayList;
import java.util.List;
public class MemoryHog {
public static void main(String[] args) {
List<byte[]> list = new ArrayList<>();
while (true) {
// 100 MBのバイト配列を生成し、リストに追加
list.add(new byte[100 * 1024 * 1024]);
}
}
}
ログファイルとは?
ログファイル【log file】とは、コンピュータプログラムやシステムが動作中に生成する情報の記録を保持するためのファイルです。ログは、システムの動作状況を追跡したり、問題が発生したときに何が起きたのかを解析したりするために非常に重要です。

logとはもともと航海日誌のことです。いつ、どこで、何が起こったかを記録した日誌です。ログにより船が難破した時の原因究明や再発防止に役立てることができます。コンピュータシステムのログも同じような目的で使われます。
ログには多くの種類がありますが、一般的には以下のような情報が含まれます。
- エラーログはプログラムが予期しない状況に遭遇したとき、何が起きたかを説明するメッセージです。開発者は問題を特定し、修正する手がかりを得ることができます。
- アクセスログはWebサーバーなどでは、誰がいつどのページにアクセスしたかといった情報が記録されたものです。サイトの人気ページを特定したり、不正アクセスを検出したりすることができます。
- トランザクションログは主としてデータベースシステムでデータの変更(追加、更新、削除など)が順番に記録されたログです。ログを使うことで障害発生時にデータを元の状態に戻す(ロールバックする)ことや、正常な時点のデータに復元する(ポイントインタイムリカバリ)ことができます。
ログファイルは、テキスト形式で保存され、ログビューアやテキストエディタを通じて閲覧することができます。ただし、大量のログが生成される場合、特定の情報を抽出するためのログ分析ツールや、リアルタイムでログを監視するためのモニタリングツールが使用されることもあります。
なお、ログはシステムの動作状況を詳細に記録するため、機密情報が含まれることがあります。そのため、ログの取扱いには適切なセキュリティ対策とプライバシー保護の観点からの配慮が必要です。
デバッグとは?
デバッグとは、コンピュータプログラムのバグを見つけて修正する作業のことを指します。

英語の【bug】には虫という意味があり、その昔、実際にコンピュータの中に虫が入り込んで不具合が起こったことから、この名前があります。
バグはプログラムが期待通りに動作しない原因となり、例えばプログラムがクラッシュしたり、誤った結果を出力したりすることがあります。デバッグのプロセスは、主に以下のステップで構成されます。
- [バグの特定]プログラムが正しく動作しないとき、まず何が問題なのかを特定する必要があります。エラーメッセージやログファイルの解析、または単純にプログラムの出力を観察することで、バグの箇所や原因を見つけ出します。
- [バグの再現]バグを特定したら、次にそのバグを再現する方法を見つける必要があります。つまり、同じエラーが再度発生するようにプログラムを操作します。このステップが重要な理由は、バグを修正した後にその修正が正しかったかどうかを確認する必要があるからです。
- [問題の解決]バグの原因を特定し、それを再現する方法を見つけたら、次にそのバグを修正します。エラーを引き起こすコードを修正し、プログラムが正しく動作するようにする作業です。
- [テストと確認]バグを修正したら、その修正が正しく、バグが解消されたことを確認するためにテストします。バグを再現する手順を再度実行し、エラーが再度発生しないことを確認する作業です。
デバッグはプログラミングの重要な一部であり、問題解決スキルと理解を深めるための重要な練習です。プログラマーは頻繁にデバッグを行うことになるので、効率的なデバッグのテクニックとツールを学ぶことは非常に価値があります。
次回は、「ネットワークにも強くなりトラブルシューティングのプロになる」を学びます。