
Q学習(Q-learning)とは?新人エンジニアでも理解できる強化学習の基礎講座
 山崎講師
山崎講師
こんにちは。ゆうせいです。
今回は、強化学習(Reinforcement Learning)の中でも、最も有名で基本的な手法であるQ学習(Q-learning)について、新人エンジニアでも直感的に理解できるように丁寧に解説していきます!
Q学習って何?一言で説明すると?
「試行錯誤を通じて、ある状態でどの行動を選ぶのが最も得かを、数値で覚えていく仕組み」
です。
もう少し言えば、「どの状況で、どの行動をとれば一番ご褒美(=報酬)がもらえるかを学ぶアルゴリズム」と考えてください。
たとえば、こんな場面で…
例:迷路を解くロボット
あなたは今、ロボットに「ゴールまで最短でたどり着けるようになってほしい」と思っています。
でも、最初からルートは教えません。
ロボットにはただ、こんな風に報酬を与えます:
- ゴールに着いたら +10点
- 壁にぶつかったら -5点
- 通常の道は 0点
この状態で、ロボットは何度も迷路をうろうろしながら、「どこでどっちに曲がるのが良いか」を学んでいく。
これが強化学習であり、その中の具体的なアルゴリズムが Q学習なんです!
状態・行動・報酬って何?
強化学習では、以下の3つが基本です:
| 要素 | 説明 |
|---|---|
| 状態(State) | 今の状況。たとえば「現在地は(3,2)」など |
| 行動(Action) | その状態で選べる動き。「右へ」「上へ」など |
| 報酬(Reward) | 行動の結果としてもらえる得点 |
Q学習の「Q」とは?
Q値(Q-value)とは、
「ある状態である行動をとったときに、将来的に得られる報酬の期待値」
を数値で表したものです。
つまり、
- 状態
- 行動


に対して、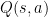
このQ値を表で管理しながら、「どの行動が得か?」を学習していきます。
Q学習の学習ステップ
Q学習のコアとなる更新式はこちら:

用語の意味:
| 記号 | 意味 |
|---|---|
| $s$ | 現在の状態 |
| $a$ | 選んだ行動 |
| $r$ | 即時報酬(その行動でもらえる得点) |
| $s'$ | 次の状態 |
| $a'$ | 次に取れる行動の中で最も良いもの |
| $\alpha$ | 学習率(0〜1) |
| $\gamma$ | 割引率(未来の報酬をどれだけ重視するか) |
学習の流れを図で!
[状態 s] → [行動 a を選ぶ] → [報酬 r を得る + 状態 s' に移動]
↓
Qテーブルを更新
↓
[状態 s'] → 次の行動へ…(繰り返し)
これを何度も何度も繰り返すことで、最も得な行動の選び方(方策)が身についていくんです!
重要な考え方:探索と活用(Exploration vs Exploitation)
Q学習では「どの行動を選ぶか」が非常に大事です。
そのときに重要になるのがこの考え方:
- 探索(exploration):まだ試してない行動をあえて試す
- 活用(exploitation):今までの経験から一番良さそうな行動を選ぶ
このバランスを取るのに使われるのが「ε-greedy法(イプシロン・グリーディ法)」です。
ε-greedy法のルール:
- 確率 ε でランダムな行動を選ぶ(探索)
- 確率 1 - ε でQ値が最大の行動を選ぶ(活用)
Q学習をPythonで実装すると…
実は、Q学習は非常にシンプルな構造なので、OpenAI Gymのような環境を使えば簡単に実装できます。
迷路や「CartPole(棒立てゲーム)」などでQ学習を試すのが最初のステップに最適です!
Q学習のメリット・デメリット
| 項目 | 内容 |
|---|---|
| メリット | - シンプルな構造- 実装が簡単- 小さな環境では高性能 |
| デメリット | - 状態数・行動数が多くなるとQテーブルが膨大になる(スケールしない)- 高次元の問題には不向き |
この弱点を解決するために登場したのが、Deep Q-Network(DQN)です。
これは、Qテーブルをニューラルネットワークで近似する手法です!
まとめ:Q学習とは?
| 観点 | 内容 |
|---|---|
| 目的 | 状態と行動のペアの「お得度」を学び、最善の行動を選ぶ |
| 記憶方法 | Qテーブル(Q(s,a))を使って記録 |
| 更新方法 | 報酬と次の状態からQ値を更新する |
| 使いどころ | 小規模な環境、基本的な強化学習の学習用に最適 |
今後の学習の指針
Q学習を理解したら、次は以下のステップに進んでみましょう!
- DQN(Deep Q-Network)でQ値の近似を学ぶ
- SARSAとの違いを理解する
- 方策ベース手法(REINFORCE、Actor-Critic)との比較
- OpenAI Gymを使って実際に試す
強化学習の基本中の基本であるQ学習をしっかりマスターしておくことは、応用アルゴリズムの理解にも大きく役立ちます!
ぜひ、手を動かして学びながら次のステップへ進んでみてください!
生成AI研修のおすすめメニュー
投稿者プロフィール
- 代表取締役
-
セイ・コンサルティング・グループ株式会社代表取締役。
岐阜県出身。
海外放浪の末、2000年創業、2004年会社設立。
IT企業向け人材育成研修歴業界歴20年以上。
すべての無駄を省いた費用対効果の高い「筋肉質」な研修を提供します!
この記事に間違い等ありましたらぜひお知らせください。
学生時代は趣味と実益を兼ねてリゾートバイトにいそしむ。長野県白馬村に始まり、志賀高原でのスキーインストラクター、沖縄石垣島、北海道トマム。高じてオーストラリアのゴールドコーストでツアーガイドなど。現在は野菜作りにはまっている。

