
データ分析初心者必見!ラベルエンコーディングとワンホットエンコーディングの使い分け完全ガイド
 山崎講師
山崎講師こんにちは。ゆうせいです。
データ分析や機械学習の世界へようこそ!これから皆さんと一緒に、AIがデータを理解するための魔法について学んでいきましょう。
皆さんは、コンピュータが日本語やカテゴリーをそのまま理解できると思いますか?実は、コンピュータは数字しか読み取ることができません。例えば、アンケート結果に「好き」「普通」「嫌い」という回答があっても、コンピュータはそれを計算に使えないのです。
そこで必要になるのが、文字を数字に変換するエンコーディングという作業です。今回は、その代表格であるラベルエンコーディングとワンホットエンコーディングについて、その違いをバッチリ解説します!
ラベルエンコーディング(Label Encoding)とは?
ラベルエンコーディングは、カテゴリーに対して単純に 0, 1, 2... と番号を振っていく手法です。
例えば、テストの評価を変換してみましょう。
- 優:0
- 良:1
- 可:2
このように、一つの列の中で数字を置き換えていきます。
専門用語解説:順序尺度(じゅんじょしゃくど)
ここで重要なのが、順序尺度という考え方です。これは、データの中に順序やランクがあるものを指します。
先ほどの「優・良・可」や「金メダル・銀メダル・銅メダル」には、明確な順番がありますよね。
例えるなら、学校の出席番号のようなものです。1番、2番、3番と並んでいるイメージですね。
メリットとデメリット
メリットは、データの形が非常にコンパクトに収まることです。元の列が1本のままなので、メモリを節約できます。
しかし、大きなデメリットがあります。それは、コンピュータが勝手に「2は0より大きいから、可は優よりも価値が高いんだな!」と勘違いしてしまう可能性があることです。
ワンホットエンコーディング(One-Hot Encoding)とは?
一方、ワンホットエンコーディングは、各カテゴリーを独立した新しい列として作り出し、該当するものに 1 、それ以外に 0 を入れる手法です。
例えば、「赤」「青」「緑」という色を変換する場合、以下のようになります。
| 赤である | 青である | 緑である |
| 1 | 0 | 0 |
専門用語解説:名義尺度(めいぎしゃくど)
こちらは名義尺度と呼ばれるデータに向いています。名義尺度とは、名前の違いだけで順序に関係がないデータのことです。
「赤」と「青」にどちらが上という順番はありませんよね?
例えるなら、電球のスイッチです。その色のスイッチが「オン(1)」か「オフ(0)」かだけを表現します。だから「ワン(1つが)ホット(オンになる)」という名前がついているのですよ。
メリットとデメリット
メリットは、コンピュータに余計な上下関係を教えずに済むことです。これにより、純粋なカテゴリーの違いとして学習させることができます。
デメリットは、カテゴリーの種類が多いと列が膨大に増えてしまうことです。都道府県47個をすべて列にしたら、データが横に長くなりすぎて処理が重くなってしまいます。
どちらを使うべき?判断基準
では、皆さんに質問です。
「犬、猫、うさぎ」という動物の種類をデータにしたいとき、どちらを使いますか?
正解は、ワンホットエンコーディングです!動物に1位、2位という順番はありませんからね。
使い分けのポイントを整理しましょう。
ラベルエンコーディングを使うとき
- データに「大・中・小」のような順序がある。
- カテゴリーの数が非常に多く、列を増やしたくない。
ワンホットエンコーディングを使うとき
- データに順序がない。
- カテゴリーの数がそれほど多くない。
数式で見るデータの変換
実際にどのような計算が行われるのか、少しだけ覗いてみましょう。データの重みを計算する際、以下のような形になります。
ラベルエンコーディングの場合、ある値 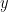
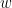


このとき、
一方、ワンホットエンコーディングでは、それぞれの列ごとに計算されます。

これなら、各カテゴリーが独立して計算に影響を与えることができます。
今後の学習の指針
今回の内容を理解できれば、データの前処理の第一歩はクリアです!
次へのステップとして、以下の内容に挑戦してみてください。
- Pythonのライブラリである scikit-learn を使って、実際に変換コードを書いてみる。
- ダミー変数化という言葉を調べて、ワンホットエンコーディングとの違いを確認する。
- カテゴリーが100個以上あるような多すぎるデータ(高次元データ)をどう扱うか、ハッシュエンコーディングなどを調べてみる。
データ分析の道は奥が深いですが、一つずつ丁寧に進んでいきましょう。分からないことがあれば、いつでも聞いてくださいね!
次は、欠損値をどう埋めるかというテーマでお会いしましょう。
この記事があなたの学習の助けになれば嬉しいです。
セイ・コンサルティング・グループでは新人エンジニア研修のアシスタント講師を募集しています。
投稿者プロフィール
- 代表取締役
-
セイ・コンサルティング・グループ株式会社代表取締役。
岐阜県出身。
海外放浪の末、2000年創業、2004年会社設立。
IT企業向け人材育成研修歴業界歴20年以上。
すべての無駄を省いた費用対効果の高い「筋肉質」な研修を提供します!
この記事に間違い等ありましたらぜひお知らせください。
学生時代は趣味と実益を兼ねてリゾートバイトにいそしむ。長野県白馬村に始まり、志賀高原でのスキーインストラクター、沖縄石垣島、北海道トマム。高じてオーストラリアのゴールドコーストでツアーガイドなど。現在は野菜作りにはまっている。
最新の投稿
 山崎講師2026年8月2日匿名加工情報とは:最も保護レベルが低い情報形式を理解する
山崎講師2026年8月2日匿名加工情報とは:最も保護レベルが低い情報形式を理解する- 山崎講師2026年8月2日仮名加工情報の役割を理解する:個人情報から一歩進んだデータ活用
- 山崎講師2026年8月2日個人情報の種類を理解する:要配慮個人情報とは何か
- 山崎講師2026年8月2日オプトインとオプトアウト:Webサービスでの同意の仕組みを理解する
