
初心者が選ぶべき道しるべ!データ分析の魔法「クラスタリング」完全ガイド
 山崎講師
山崎講師こんにちは。ゆうせいです。
あなたは、山積みになった大量のデータを前にして「これをどうにかして似たもの同士でまとめたい」と思ったことはありませんか?例えば、スーパーのお客さんを「自炊派」や「お惣菜派」に分けたり、大量のメールを「仕事」や「プライベート」に分類したりする作業です。
もし、コンピューターが自動でこれを行ってくれたら便利だと思いませんか?それを実現するのが、今回解説するクラスタリングという技術です。データ分析の世界では基本中の基本ですが、奥が深くて最高に面白い分野ですよ。さあ、一緒にデータの迷宮を解き明かしていきましょう!
クラスタリングって何だろう?
クラスタリングとは、正解がわかっていないデータの中から、似ているもの同士を集めてグループ(クラスター)を作る手法のことです。
ここで大切なのは、機械学習における「教師なし学習」という分類に属することです。
教師なし学習を例えるなら、名前も知らない色とりどりの果物が入ったカゴを渡されて「とりあえず似たような見た目のもので分けてみて」と頼まれるようなものです。リンゴやバナナという正解(ラベル)を教わらなくても、色や形でなんとなくグループが作れますよね。
一方で、あらかじめ「これはリンゴです」と教え込まれたデータを使うのは「教師あり学習」と呼びます。クラスタリングは、未知のデータから新しい発見をするための強力な武器になるのです。
メリットとデメリット
クラスタリングを使うと、どんな良いことがあるのでしょうか。
メリット
- 人間が気づかなかったデータの共通点が見つかる。
- 膨大なデータを少数のグループに整理して理解しやすくなる。
- 顧客ターゲットの絞り込みなど、ビジネスの戦略作りに直結する。
デメリット
- 「何個のグループに分けるか」を人間が決める必要がある場合が多い。
- データの並び順やノイズに結果が左右されやすい。
- 計算に時間がかかる手法もあり、データ量に応じた工夫が求められる。
代表的なクラスタリング手法をマスターしよう
一口にクラスタリングと言っても、そのやり方はさまざまです。研修講師として、特によく使われる手法を厳選して紹介しますね。
1. K-means法(K平均法)
最も有名でシンプルな手法です。最初に「いくつのグループに分けるか(K個)」を決めると、コンピューターがデータの中心点を探しながらグループを調整していきます。
例えば、クラスの生徒を3つの班に分けるとき、適当に3人のリーダーを決めて、他の生徒は一番近いリーダーの元に集まるようなイメージです。その後、集まったメンバーの真ん中にリーダーが移動し直して、また集まり直す。これを繰り返して最適な形に落ち着かせます。
数学的な距離を計算する際は、以下のような式が使われます。
点 A と点 B の距離 




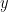

2. 階層的クラスタリング
こちらは、最初からグループの数を決める必要がありません。似ているもの同士をどんどん合体させて、最終的に大きな一つの木のような構造(デンドログラム)を作ります。
学校のトーナメント表を思い浮かべてください。最初は一人ひとりが独立していますが、近い者同士がペアになり、そのペア同士がさらに大きな塊になっていく。そんなイメージです。
3. DBSCAN(ディービースキャン)
密度に注目した手法です。「データが密集しているところを一つのグループとみなす」という考え方です。
都会の喧騒のように人が集まっている場所を街とし、ぽつんと離れた一軒家はノイズ(外れ値)として処理します。これのすごいところは、ドーナツ型のような複雑な形のグループでも正しく見つけ出せる点です。
4. 混合ガウスモデル(GMM)
K-means法に似ていますが、もっと柔軟な考え方をする手法です。K-meansが「君はこのグループ!100パーセント決まり!」と断定するのに対し、GMMは「君はAグループである確率が 0.8 、Bグループである確率が 0.2 だね」と、確率で表現します。
これをソフトクラスタリングと呼びます。 例えば、朝食にパンもご飯も両方食べるような「中間的な人」を無理やりどちらかに決めつけず、しなやかに分類できるのが強みです。
数学的な分布(ベル型のカーブ)の重なりとして計算します。 全体の分布 


5. 平均値シフト法(Mean Shift)
データの密度が最も高い場所(山頂)を探していく手法です。 霧の中を歩いていて、一番周りに人がたくさんいる方向に足を進めていき、最終的にたどり着いたピークをグループの中心とみなします。
DBSCANと同じく、あらかじめグループの数を決めなくて良いのが大きなメリットです。 画像処理の分野で、似た色の領域をひとまとめにする時などによく使われますよ。
6. スペクトラルクラスタリング
これは少し高度ですが、とても強力です。データ同士の「つながり(グラフ)」に注目します。 そのままでは複雑に絡み合って分類しにくいデータでも、一度次元を落として(別の視点から見て)から分ける手法です。
例えるなら、絡まった知恵の輪を真正面から見るのではなく、影を投影してシンプルな線として捉え直してから切り分けるようなイメージです。K-meansでは太刀打ちできないような、複雑に入り組んだ構造を持つデータに非常に強いのが特徴です。
手法の比較表
基本となる3つの特徴を簡単にまとめてみました。
| 手法名 | グループ数の指定 | 得意なデータの形 | 処理速度 |
| K-means | 必要 | 丸い塊 | とても速い |
| 階層的 | 不要 | 樹形図状 | データが多いと遅い |
| DBSCAN | 不要 | 複雑な形 | 密度がバラバラだと苦手 |
これからの学習のステップ
さて、クラスタリングの世界はいかがでしたか?「意外と自分でも使えそう!」と感じていただけたら嬉しいです。
次のステップとしては、以下の3つに挑戦してみてください。
- Pythonなどのプログラミング言語を使って、実際にライブラリを動かしてみる。
- 「エルボー法」という、最適なグループ数を見つけるためのテクニックを学ぶ。
- 実際のビジネスケースで、どの手法が最適か選定する練習をする。
データはただ持っているだけでは数字の羅列に過ぎません。クラスタリングという光を当てて、そこに隠れたストーリーを見つけ出しましょう!
もっと詳しく知りたい手法や、具体的な計算式について質問があればいつでも聞いてくださいね。次は、より実践的なデータの加工方法についてお話ししましょう。
セイ・コンサルティング・グループでは新人エンジニア研修のアシスタント講師を募集しています。
投稿者プロフィール
- 代表取締役
-
セイ・コンサルティング・グループ株式会社代表取締役。
岐阜県出身。
海外放浪の末、2000年創業、2004年会社設立。
IT企業向け人材育成研修歴業界歴20年以上。
すべての無駄を省いた費用対効果の高い「筋肉質」な研修を提供します!
この記事に間違い等ありましたらぜひお知らせください。
学生時代は趣味と実益を兼ねてリゾートバイトにいそしむ。長野県白馬村に始まり、志賀高原でのスキーインストラクター、沖縄石垣島、北海道トマム。高じてオーストラリアのゴールドコーストでツアーガイドなど。現在は野菜作りにはまっている。
最新の投稿
 山崎講師2026年8月1日コンピューターが数値計算の誤差に対処する仕組みと精度管理の方法
山崎講師2026年8月1日コンピューターが数値計算の誤差に対処する仕組みと精度管理の方法- 山崎講師2026年8月1日0乗が1になる理由を2乗の計算式から解説する指数法則の基礎
- 山崎講師2026年8月1日機械学習モデルの予測理由を解釈するSHAPとシャープレイ値の基礎
- 山崎講師2026年8月1日適合率と再現率の概念と初心者向けのわかりやすい再翻訳案
