
コイン3枚で完全理解!情報量からKLダイバージェンスまでAI時代の必須知識をマスターしよう
 山崎講師
山崎講師第1章:自己情報量:1つの出来事の「驚き」を数値化する
突然ですが、あなたは「情報量が多い」とはどういう意味で使っていますか?
一般的には、文章であれば、内容が豊富であることを指すことが多いでしょう。画像であれば、細部まで描かれていることを指すかもしれません。しかし、情報理論の観点から見ると、少し違った意味になります。
情報量を説明する上でよくある話を一つしましょう。以下の 2 つの文章を読んで、状況を想像してみてください。
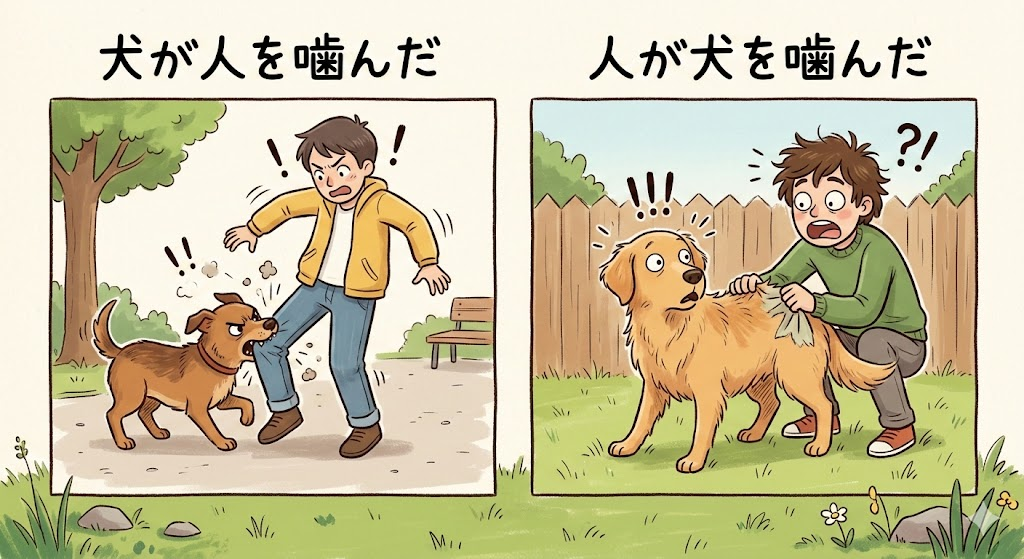
「犬が人を噛んだ」
「人が犬を噛んだ」
どちらの文章の方が、あなたにとって「情報量が多い」と感じますか?
「犬」が「人」を噛むことは、よくあることなので、あまり驚きません。一方で、「人」が「犬」を噛むことは、あまりよくある状況ではないため、少し驚きますよね。よって、一般的には、2 番目の文章の方が、1 番目の文章よりも「情報量が多い」と言うことができます。
この例からわかるように、情報理論においては、ある事象が起こる確率が低いほど、その事象が持つ情報量は多いとされます。つまり、想像しやすい状況は、情報量が少ないとされ、想像しにくい状況は、情報量が多いとされるわけです。
LLMと情報量
少し脱線しますが、最近の大規模言語モデル(LLM)においても、情報量の概念は重要です。
LLM は、与えられた文脈のもとで次に現れやすい単語を高い確率で予測するように訓練されています。それは、言い換えると、LLM は、情報量が少ない出力を生成する傾向があると言えます。
「猫が人を引っ掻いた」という文章は、一般的に LLM にとっては、情報量が少ないため、生成されやすいです。一方で、「人が猫を引っ掻いた」という文章は、LLM にとっては、情報量が多いため、生成されにくいのです。
自己情報量の定義
それでは本題に戻りましょう。先ほどの例を踏まえて、情報量を定義してみます。
専門用語では、ある特定の出来事が起きたときに得られる情報の大きさを、自己情報量と呼びます。自己情報量は、ある事象が起こる確率が低いほど、その事象が持つ値は大きくなります。
つまり、ある事象が起こる確率を 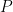
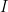

高校数学で習う対数(ログ)が出てきましたが、難しく考える必要はありません。これは「確率が 
例えば、3 枚のコインを投げて、全てが表になる確率を考えてみましょう。
1 枚が表になる確率は

この場合、自己情報量は以下のようになります。

つまり、3 枚のコインが全て表になるという事象は、3 bit の情報量を持つことになります。
bit(ビット)という単位の正体
ここで「bit」という単位に注目してください。3 bit というのは、実は「はい・いいえ」で答えられる質問を 3 回繰り返して、ようやくその事象を特定できる、という意味でもあります。
3 枚のコインの結果を誰かに当ててもらう場面を想像してください。
「1 枚目は表ですか?」「2 枚目は表ですか?」「3 枚目は表ですか?」
この 3 つの質問にすべて「はい」と答えてもらって、初めて「全部表だったんだ!」と特定できますよね。この質問の回数こそが、情報量の正体なのです。
メリットとデメリット
自己情報量を理解することには、どのような意味があるのでしょうか。
メリットは、主観的な「驚き」を客観的な「数値」として扱えるようになることです。これにより、コンピュータが「どのデータが珍しくて重要か」を計算できるようになります。
一方で、デメリットというか注意点もあります。自己情報量はあくまで「確率」に基づいた指標です。そのため、その情報の「意味の深さ」や「道徳的な価値」までは考慮してくれません。例えば、デタラメな文字の羅列であっても、それが起きる確率が極めて低ければ、理論上の情報量は膨大になってしまいます。
第1章のまとめ
- 情報量とは、珍しさ(驚きの大きさ)のことである。
- 確率が低いほど、自己情報量は大きくなる。
- 単位の bit は、その事象を特定するのに必要な「はい・いいえ」の質問回数に相当する。
次は、これらの自己情報量を平均した「エントロピー」について学んでいきましょう!
この「驚きの平均値」が分かると、データの圧縮や予測がもっと面白くなりますよ。
第2章:シャノンエントロピー:平均的な「予測しにくさ」
第1章では、たった一つの出来事が起きたときの「驚きの大きさ(自己情報量)」についてお話ししました。では、次に進みましょう。もし、コインを投げる前に「全体として、どのくらい結果が予測しにくいか」を数値で表せるとしたら、便利だと思いませんか?
それを教えてくれるのが、シャノンエントロピーという概念です。
エントロピーとは「平均的な情報量」のこと
エントロピーを一言で言うなら、ある確率分布において、平均的にどれだけの情報量が含まれているかを表す指標です。
難しく聞こえるかもしれませんが、要するに「そのギャンブル(試行)は、平均してどれくらいドキドキするか?」を数値化したものだと考えてください。
エントロピーは、確率分布

この式は、それぞれの出来事が持つ「自己情報量」に、その出来事が起こる「確率」を掛けて、すべて足し合わせたものです。まさに「情報の平均値」ですよね。
3枚のコインで計算してみよう!
では、実際に 3 枚のコインを投げたときの「表の数」に注目して、エントロピーを計算してみましょう。表が出る枚数の確率は、以下のようになります。
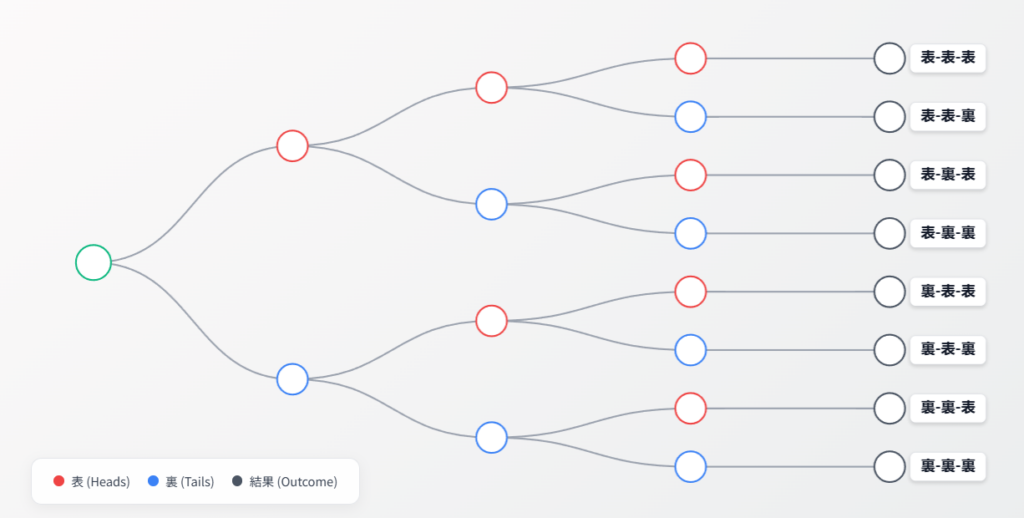
| 表の数 | 確率 | 自己情報量(驚き) |
| 0枚 | 1/8 | 3 bit |
| 1枚 | 3/8 | 約 1.415 bit |
| 2枚 | 3/8 | 約 1.415 bit |
| 3枚 | 1/8 | 3 bit |
この確率分布のエントロピーを計算すると、以下のようになります。


この「1.811 bit」という数字は何を意味しているのでしょうか?
それは、このコインの表の数を完全に特定するために、平均して約 1.811 回の「はい・いいえ」の質問が必要である、ということなのです。
効率的な質問のしかた
「質問は整数回しかできないのに、1.811回なんて中途半端な数字はおかしい!」と思いましたか?鋭い視点ですね!
実は、エントロピーは「理想的な戦略」をとったときの限界値を表しています。
例えば、次のような質問戦略を考えてみましょう。
- 「表の数は 1 枚か 2 枚ですか?」( Yes の確率は
、No は
)
- ( Yes の場合)「それは 1 枚ですか?」
- ( No の場合)「それは 0 枚ですか?」
このように、確率が高いもの(よく起きること)を優先的に絞り込む質問を繰り返すと、平均的な質問回数をエントロピーの数値に近づけることができるのです。
エントロピーのメリットとデメリット
エントロピーを理解する最大のメリットは、データの圧縮限界がわかることです。「このデータはこれ以上小さくできない」という理論的な壁を、エントロピーが教えてくれます。
一方でデメリットは、あくまで「確率の散らばり具合」を見ているだけなので、中身がどれほど重要かは教えてくれない点です。砂嵐のようなデタラメなノイズ画像は、予測が全くつかないためエントロピーが最大になりますが、人間にとっては価値のない情報ですよね。
第2章のまとめ
- エントロピーは、情報量の「平均値」である。
- 確率分布がバラバラで、予測しにくいほどエントロピーは高くなる。
- データをどれだけ効率よく圧縮できるかの「理論的な限界」を表している。
さて、ここまでは「1つのルール(分布)」の中での話でした。
次は、自分の「予想」と「現実」が食い違ったときに何が起きるのか、第3章の「交差エントロピー」と「KLダイバージェンス」で詳しく見ていきましょう!
第3章:交差エントロピーとKLダイバージェンス:理想と現実のズレ
これまでは、コインの表が出る枚数のように、決まったルール(確率分布)の中だけで話を進めてきました。しかし、現実の世界ではどうでしょうか。私たちは常に「こうなるだろう」という自分の予想を持って動いていますよね。
第3章では、自分の予想と現実にズレがあったときに何が起きるのかを数値化する、交差エントロピーとKLダイバージェンスについて解説します!
交差エントロピーは「的外れな戦略」のコスト
想像してみてください。あなたは「このコインはイカサマだ。絶対に表が出るはずだ!」と固く信じているとします。この、あなたの思い込みによる確率の分布を 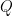
一方で、実際にはそのコインは普通のコインで、表も裏も同じ確率で出るとします。この真実の確率分布を
このとき、あなたが自分の間違った予想
この「間違った予想に基づいたときの、平均的な情報量(質問回数)」のことを、交差エントロピーと呼びます。
式で表すと、真実の分布

LLM(大規模言語モデル)の学習では、この交差エントロピーという指標が主役です!AIが作った文章の分布(予想
KLダイバージェンスは「ズレの正体」
次に、KLダイバージェンスについてお話ししましょう。これは、2つの分布がどれくらい離れているかという「距離」を表す指標です。
先ほどの交差エントロピーには、実は「本来必要な情報量(エントロピー)」と「予想が外れたせいで余計にかかった情報量」の2つが含まれています。
これを式にすると、非常にスッキリします!

KLダイバージェンス = 交差エントロピー - エントロピー
つまり、KLダイバージェンスは、純粋に「あなたの予想がどれだけ現実からズレているか」だけを抜き出した数値なのです。ズレが全くない( 

これを、確率を表す 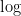

メリットとデメリット
交差エントロピーやKLダイバージェンスを使うメリットは、目に見えない「予測の精度」を数学的に厳密に測定できることです。これにより、AIの賢さを数値で測り、より正確な方向に導くことが可能になります。
一方でデメリットは、この指標が「非対称」であるという点です。
第3章のまとめ
- 交差エントロピーは、間違った予測に基づいて行動したときの「平均的なコスト」である。
- KLダイバージェンスは、2つの確率分布がどれくらい「ズレているか」を表す。
- AIの学習とは、このズレ(交差エントロピー)を極限まで減らしていく作業のことである。
自分の考えと現実のギャップを数字で見ることができるなんて、少し怖い気もしますが、とても合理的だと思いませんか?
次は、コインの間に隠れた関係性を暴く「相互情報量」について見ていきましょう。
「1枚目が表なら、2枚目も表になりやすい」といった、データの繋がりを解き明かす魔法の指標ですよ!
情報理論入門:相互情報量でデータの隠れた繋がりを見抜く完全ガイド
第4章:相互情報量:コインの間に隠れた関係性を見抜く
第3章までは、3枚のコインがそれぞれバラバラに、独立して動いていることを前提にお話ししてきました。少し視点を変えてみましょう!もし、得られたデータ同士に「繋がり」があったらどうなると思いますか?
第4章では、2つの事象がどれだけ情報を共有しているかを測る、相互情報量について解説します。
片方を知ればもう片方が予測しやすくなる感覚
想像してみてください。あなたが3枚のコインを投げて、手で隠しているとします。私が「全体の表の数は何枚ですか?」と当てるゲームをしている状況を思い浮かべてください。第2章で計算した通り、表の数の予測しにくさ(エントロピー)は約 
ここで、あなたがこっそり「1枚目のコインは表だったよ」と教えてくれたとします。すると、私の予測はどう変化するでしょうか?
1枚目が表だと分かった瞬間、全体の表の数が「0枚」になる可能性は完全に消え去ります。残る2枚の結果次第なので、全体の表の数は「1枚」「2枚」「3枚」のどれかに絞られました。まったくのノーヒントだった状態に比べて、格段に予測が簡単になりましたよね!
ある事象(1枚目の結果)を知ることで、もう一方の事象(全体の表の数)の予測しにくさがどれだけ減ったかを数値化したものを、専門用語で相互情報量と呼びます。
エントロピーの引き算で計算する
相互情報量を数学的に表現してみましょう。2つの事象 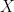
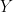


数式を見ると難しそうに感じるかもしれませんが、意味はとてもシンプルです。 


もし2つの事象に全く関係がなければ、両方を同時に当てる難しさは、それぞれの難しさを単純に足し合わせたものと同じになります。しかし、お互いに関係性があれば、片方が分かればもう片方も分かる部分があるため、同時に当てる難しさは少し下がります。下がった分、つまり両者が共有している情報こそが相互情報量なのです!
実際の計算例で相互情報量を体感しよう
それでは、先ほどの「1枚目のコインの結果」と「表の総数」の関係を、実際に数字を使って計算してみましょう。 少し複雑に見えるかもしれませんが、パズルを解くような感覚で追いかけてみてくださいね。
ステップ1:全体の表の数 のエントロピー
3枚のコインを投げたとき、表の数 


ステップ2:1枚目の結果 を知った後のエントロピー 
ここで、1枚目のコイン 
この「条件付き」の状態での予測しにくさを計算すると、次のようになります。

ステップ3:情報の「おトク感」を計算する
さて、ヒントをもらう前は 
相互情報量 

つまり、1枚目のコインの結果を知ることで、あなたは全体の正解に 
メリットとデメリット
相互情報量を使うメリットを具体的に見ていきましょう。最大の利点は、データの中に隠れた「相関関係」をあぶり出せる点にあります。AI(大規模言語モデル)が言葉を学ぶ際にも、「『空が』という言葉の次には『青い』がきやすい」といった単語同士の結びつきの強さを計算するのに、相互情報量の考え方が大いに役立っています。
一方で、デメリットも存在します。膨大な種類のデータ同士で相互情報量を計算しようとすると、すべての組み合わせの確率を調べなければならず、コンピュータの計算時間やメモリを極めて大量に消費してしまう点に注意してください。
第4章のまとめ
- 相互情報量とは、2つの出来事が「どれだけ情報を共有しているか」を示す指標である。
- 片方の結果を知ることで、もう片方の予測がどれくらい楽になるかで計算できる。
- AIが言葉の繋がりやデータの相関を理解するために欠かせない考え方である。
さあ、ついに最後の総仕上げです。第5章では、これまで学んだエントロピーの知識を使って、データを極限まで圧縮する「シャノンの情報源符号化定理」について学んでいきましょう。無駄のない効率的な通信がどうやって実現されているのか、魔法のような仕組みをぜひ楽しみにしていてくださいね!
AIの根幹を支える魔法の定理!シャノンの情報源符号化定理とデータ圧縮の限界
第5章:シャノンの情報源符号化定理とまとめ
いよいよ最終章です!今まで学んできた情報理論の知識が、現実の世界でどのように役立っているのかを見ていきましょう。
クロード・シャノンという人物をご存知ですか?情報理論の父と呼ばれるシャノンが提唱した「情報源符号化定理」について解説します。現代のスマートフォンやインターネットが快適に使えるのは、シャノンの大発見があったからなのです!
エントロピーはデータ圧縮の「限界ライン」
情報源符号化定理を高校生にもわかるように一言で説明すると、「データを圧縮するとき、平均的な長さをエントロピーより短くすることは絶対にできない」という強力なルールです。
第2章で、3枚のコインを投げたときの表の数を特定するエントロピーは約
限界に挑戦!コインの確率で圧縮を体験しよう
では、実際にデータを短い暗号に変換する(圧縮する)方法を考えてみてください。表の数が出る確率は以下の通りでした。
0枚:

1枚:

2枚:
3枚:
戦略Aとして、表の数が何枚であっても、すべて2回の質問( 
そこで、戦略Bとして、確率に合わせて暗号の長さを変えてみてください!
よく起こる結果には短い暗号を、めったに起きない結果には長い暗号を割り当てるのがコツです。
確率が高い1枚と2枚には短い暗号(2回の質問や1回の質問)を使い、確率が低い0枚と3枚には長い暗号(3回の質問)を使います。平均の質問回数を計算してみましょう。
平均の長さ 
いかがでしょうか!戦略Aの 
メリットとデメリット
情報源符号化定理に基づくデータ圧縮のメリットは、無駄を徹底的に省き、通信量や保存容量を劇的に減らせることです。高画質の動画をスマートフォンでスムーズに見られるのは、データをエントロピーの限界近くまで圧縮して送ってくれているからです。
一方でデメリットは、限界まで圧縮しようとすればするほど、暗号化と復号(元に戻す作業)のルールが複雑になり、コンピュータの計算処理に時間がかかってしまうことです。速さと軽さのバランスを取るのがエンジニアの腕の見せ所ですね。
記事全体のまとめ
コイン3枚という身近な例から出発し、5つの重要な概念を駆け抜けました。
- 自己情報量:確率が低い出来事ほど「驚き」が大きい。
- シャノンエントロピー:確率分布全体の「予測しにくさ」の平均値。
- 交差エントロピー:間違った予測で動いたときの無駄を含んだコスト。
- KLダイバージェンス:予測と現実がどれくらい「ズレ」ているか。
- 相互情報量:2つの出来事がどれだけ情報を共有しているか。
最近話題のAIや大規模言語モデルが流暢な言葉を紡ぎ出す背景には、驚きを計算し、予測のズレを減らし、言葉の繋がりを見つけ出すという、緻密な数学の世界が広がっています。情報理論の基礎を知ることで、魔法のように見えるAIの仕組みが、少しだけ身近に感じられたのではないでしょうか。
今後の学習の指針
情報理論の世界に興味を持っていただけたなら、次はぜひ「ハフマン符号化」という具体的なデータ圧縮のアルゴリズムを調べてみてください!
今回紹介した「出やすい結果には短い暗号を」というアイデアが、プログラムとしてどのように実現されているのかが分かると、さらに理解が深まりますよ。紙とペンを使って、自分で最適な暗号化ツリーを描いてみるのも非常に面白い体験になります。
最後まで読んでいただき、本当にありがとうございました!
セイ・コンサルティング・グループでは新人エンジニア研修のアシスタント講師を募集しています。
投稿者プロフィール
- 代表取締役
-
セイ・コンサルティング・グループ株式会社代表取締役。
岐阜県出身。
海外放浪の末、2000年創業、2004年会社設立。
IT企業向け人材育成研修歴業界歴20年以上。
すべての無駄を省いた費用対効果の高い「筋肉質」な研修を提供します!
この記事に間違い等ありましたらぜひお知らせください。
学生時代は趣味と実益を兼ねてリゾートバイトにいそしむ。長野県白馬村に始まり、志賀高原でのスキーインストラクター、沖縄石垣島、北海道トマム。高じてオーストラリアのゴールドコーストでツアーガイドなど。現在は野菜作りにはまっている。
最新の投稿
 山崎講師2026年8月1日コンピューターが数値計算の誤差に対処する仕組みと精度管理の方法
山崎講師2026年8月1日コンピューターが数値計算の誤差に対処する仕組みと精度管理の方法- 山崎講師2026年8月1日0乗が1になる理由を2乗の計算式から解説する指数法則の基礎
- 山崎講師2026年8月1日機械学習モデルの予測理由を解釈するSHAPとシャープレイ値の基礎
- 山崎講師2026年8月1日適合率と再現率の概念と初心者向けのわかりやすい再翻訳案
