トランスフォーマー:現代AIの基盤となる革新的アーキテクチャの全体像
 山崎講師
山崎講師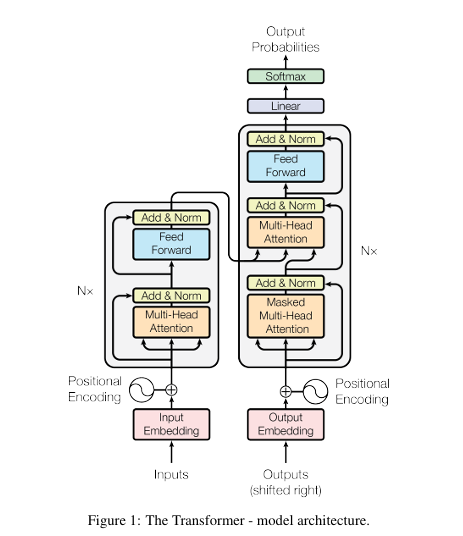
はじめに
こんにちは。ゆうせいです。
現在、私たちが日常的に利用している文章生成AIや高性能な翻訳サービスの裏側には、トランスフォーマー(Transformer)と呼ばれる技術が共通して使われています。2017年に発表されたこの技術は、それまでの人工知能の常識を塗り替え、現在のAIブームを支える決定的な役割を果たしました。
今回は連載の第1回として、このトランスフォーマーがどのような仕組みで、なぜこれほどまでに優れているのか、その全体像を解説します。
トランスフォーマーとは何か
トランスフォーマーは、与えられた文章を別の文章に変換したり、次に来るべき言葉を予測したりするための構造(アーキテクチャ)のことです。
大きな特徴は、図の左側にある「エンコーダ」と、右側にある「デコーダ」という2つの主要なパーツで構成されている点です。
- エンコーダ:入力された文章の意味を深く理解し、コンピュータが扱いやすい数値の束に変換します。
- デコーダ:エンコーダが作成した数値を受け取り、それをもとに新しい文章を組み立てます。
例えば、日本語を英語に翻訳する場合、エンコーダが日本語の意味を汲み取り、デコーダがその意味に合致する英語を生成するという流れになります。
従来技術との決定的な違い:並列処理
トランスフォーマー以前のAI(RNN:再帰型ニューラルネットワークなど)は、文章を端から1単語ずつ順番に処理していました。これは、前の単語の処理が終わらないと次の単語に進めないため、非常に時間がかかるという課題がありました。
これに対し、トランスフォーマーは文章に含まれるすべての単語を「同時」に処理する並列処理を実現しました。
高校の授業に例えると、これまでのAIは「先生が教科書を1行ずつ音読し、生徒がそれを順番に書き写す」ような形式でした。一方、トランスフォーマーは「クラス全員が教科書の異なるページを同時に読み、後で情報を共有する」ような形式です。これにより、学習のスピードが劇的に向上しました。
核心技術:自己注意機構(セルフアテンション)
トランスフォーマーが単語を同時に処理しながらも、文脈を正確に理解できる理由は、自己注意機構(セルフアテンション)という仕組みにあります。
これは、文中のある単語が、同じ文内の他のどの単語と強く関係しているかを計算する機能です。
例: 「彼は手にリンゴを持って、それを食べた。」
この文章において、「それ」という言葉が何を指しているかを判断するのは人間には簡単ですが、機械には困難でした。自己注意機構は、「それ」という単語を処理する際に「リンゴ」という単語に高い注目(アテンション)を払うことで、文脈を正しく把握します。
トランスフォーマーのメリットとデメリット
メリット
- 並列計算が可能なため、膨大なデータを用いた学習を短期間で完了させることができます。
- 文章が長くなっても、文頭と文末の関連性を失わずに処理できるため、一貫性のある文章を作成できます。
デメリット
- すべての単語間の関係を計算するため、文章が長くなればなるほど、必要な計算量とメモリ消費量が加速度的に増大します。
- 単語の並び順を並列処理で無視してしまうため、別途「位置情報」を教え込む工夫(位置エンコーディング)が必要になります。
まとめと次のステップ
トランスフォーマーがエンコーダとデコーダで構成され、並列処理と自己注意機構によって高速かつ正確な理解を実現していることを説明しました。
この革新的なモデルが、具体的にどのようにして単語を数値として受け取り、その順番を認識しているのでしょうか。
次はデータの入り口にあたる「埋め込み(Embedding)」と「位置エンコーディング(Positional Encoding)」の仕組みについて詳しく解説します。
トランスフォーマーを構成する2つの主要部分
トランスフォーマーは、入力された文章を別の文章に変換したり、次に出現する単語を予測したりする構造を持っています。トランスフォーマーの構造は大きく分けて、エンコーダとデコーダという2つの部分から成り立っています。
エンコーダは、入力された文章を読み込み、コンピュータが計算しやすい数値の集まりに変換する役割を担います。デコーダは、エンコーダが作成した数値を受け取り、新しい文章を組み立てる役割を持ちます。
高校の英語の授業に例えると、エンコーダは日本語の課題文を読んで意味を理解する作業に該当し、デコーダは理解した意味をもとに英作文を行う作業に相当します。
従来技術との違い:並列処理による高速化
トランスフォーマー以前の技術である再帰型ニューラルネットワークなどは、文章を先頭から1単語ずつ順番に処理していました。前の単語の処理が完了しないと次の単語に進めないため、長い文章の処理には時間がかかるという課題が存在しました。
対して、トランスフォーマーは文章に含まれるすべての単語を同時に処理する並列処理を採用しています。
並列処理と順番に処理する方式の違いを学校の課題に例えると、従来の技術は1冊の本を1人の生徒が最初から最後まで順番に読む状態です。一方の並列処理は、本をページごとに分解し、クラス全員で同時に読んで内容をまとめる状態に似ています。複数人で同時に作業を進めることで、学習の速度が向上しました。
核心となる技術:自己注意機構
単語を同時に処理しながら文脈を正確に把握できる理由は、自己注意機構(セルフアテンション)という技術が組み込まれているためです。
自己注意機構は、文章の中にある特定の単語が、同じ文章の中のどの単語と強い関連性を持っているかを計算する仕組みです。
例えば「太郎はカバンを持ち、それを開けた」という文章において、「それ」という言葉がカバンを指していると判断する過程です。自己注意機構は「それ」という単語を処理する際に、「カバン」という単語に対して高い注目度を割り当てる計算を行います。関連性の高い単語に注目することで、機械でも文脈を正確に捉えることが可能になります。
トランスフォーマーのメリットとデメリット
トランスフォーマーの特徴を客観的な事実に基づいて整理します。
メリット
- 文章全体の単語を同時に処理できるため、大規模なデータを用いた学習を短時間で完了できます。
- 文の先頭と末尾など、離れた位置にある単語同士の関連性も直接計算できるため、長い文章でも文脈を見失わずに処理できます。
デメリット
- すべての単語の組み合わせについて関連性を計算するため、入力する文章が長くなるほど、必要な計算能力とメモリの消費量が増加します。
- 単語を同時に処理する性質上、そのままでは単語の並び順(語順)を認識できないため、入力時に順序の情報を追加する別の仕組みが必要となります。
次は、データの入り口にあたる埋め込みと位置エンコーディングの仕組みについて解説します。
単語を数値ベクトルに変換する入力埋め込み
コンピュータは文字列をそのまま理解することができません。そのため、入力された単語を数値の配列であるベクトルに変換する作業が必要となります。単語をベクトルに変換する処理を入力埋め込みと呼びます。
入力埋め込みは、単語の意味合いを多次元の空間上の座標として表現します。似た意味を持つ単語は、多次元空間上で近い位置に配置されます。
高校の生徒の特徴を数値化する状況に例えて説明します。生徒の特徴を、国語の成績、数学の成績、運動能力、芸術的センスといった複数の項目に対する点数の集まりとして表現する状態と似ています。入力埋め込みは、各単語の持つ意味的な特徴を、数百から数千の項目を持つ点数(ベクトル)として数値化する機能を持っています。
語順情報を補う位置エンコーディング
トランスフォーマーはすべての単語を同時に処理するため、入力埋め込みの段階では単語の並び順(語順)のデータが失われています。「犬が人を噛む」と「人が犬を噛む」の違いをモデルが認識するためには、単語が文章の中のどの位置にあるかを示す情報が必要です。位置情報を付与する仕組みが位置エンコーディングです。
位置エンコーディングの役割を音楽の楽譜に例えて説明します。楽譜における音符は、五線譜上の高さ(入力埋め込みによる意味情報)だけでなく、左から右へどのタイミングで演奏されるかという横軸の位置情報(位置エンコーディング)を持っています。横軸の位置情報がなければ、メロディは成立しません。トランスフォーマーは、単語の意味を表すベクトルに対して、文章の中の位置を示す固有のベクトルを足し合わせることで、順序の情報を保持します。
波の性質を利用した位置情報の計算
位置エンコーディングでは、単語の絶対的な位置だけでなく、単語同士の相対的な距離をモデルが学習しやすいように、サイン波(正弦波)とコサイン波(余弦波)の周期関数を用いて位置ベクトルを計算します。
論文内で提案されている位置エンコーディングの基本方程式は以下の通りです。


ここで、posは文章の中の単語の位置を示し、iはベクトルの次元のインデックスを示します。偶数次元にはサイン関数が、奇数次元にはコサイン関数が適用されます。波の周期を変えることで、近い位置にある単語同士の相対的な位置関係を、コンピュータが正確に計算できる仕組みになっています。
入力処理に関するメリットとデメリット
入力埋め込みと位置エンコーディングの仕組みについて、事実に基づく特徴を整理します。
メリット
- 単語の意味と位置情報を固定長の数値ベクトルとして表現することで、後続の並列計算を効率的に実行できます。
- サイン波とコサイン波を用いることで、学習時に経験したことのない長さの文章が入力されても、理論上は位置情報を計算して対応することが可能です。
デメリット
- 事前に定義された語彙(辞書)に存在しない未知の単語が入力された場合、適切な入力埋め込みベクトルを割り当てることが困難になります。
- 文章が非常に長くなると、遠く離れた単語間の相対的な位置関係の精度が低下する傾向があります。
次は、トランスフォーマーの核心部である注意機構の仕組みについて解説します。
クエリ、キー、バリューの役割
注意機構は、入力された単語の関連性を計算するために、各単語のデータを3つの役割に分割します。分割されたデータは、クエリ(Query)、キー(Key)、バリュー(Value)と呼ばれる3つのベクトルとして扱われます。
注意機構の仕組みを、高校の図書室で本を探す状況に例えて説明します。
- クエリ:生徒が探したい情報のキーワード(検索条件)
- キー:図書室にある各本が持っているタイトルや目次(検索対象のラベル)
- バリュー:本の中に書かれている実際の内容(情報そのもの)
注意機構は、入力された単語(クエリ)が、文章内の他のどの単語(キー)と一致するかを照合し、一致度が高い単語の情報(バリュー)を強く引き出します。
注意機構の計算過程と数式
特定の単語が他の単語にどれだけ注目すべきかを計算する過程は、舞台照明に似ています。主役となる単語に対して、関連性の高い脇役の単語に強いスポットライトを当て、関連性の低い単語には弱い光を当てることで、文脈全体の中で重要な情報を浮き上がらせます。
論文で定義されている自己注意機構の計算式は以下の通りです。

計算式において、Qはクエリ、Kはキー、Vはバリューの行列を表します。クエリとキーの内積を計算し、スケーリング係数(ルートdk)で割ることで計算を安定させます。最後にソフトマックス関数を適用して確率(注目度)に変換し、バリューを掛け合わせて最終的な出力を得ます。
マルチヘッドアテンションによる多角的な分析
トランスフォーマーは、単一の注意機構ではなく、複数の注意機構を並行して動作させるマルチヘッドアテンションを採用しています。
1つの注意機構だけで文章を分析すると、主語と述語の関係など、特定の文脈にのみ偏って注目してしまう可能性があります。マルチヘッドアテンションは、複数の視点を持たせることで文脈をより正確に捉えます。
高校の国語の授業において、1つの小論文を複数の教師が採点する状況に例えます。文法をチェックする教師、論理構成を評価する教師、表現の豊かさを確認する教師が、それぞれ異なる視点から小論文を分析し、最終的にすべての評価を統合する工程と同じ役割を果たします。
注意機構のメリットとデメリット
マルチヘッドアテンションの仕組みに基づくメリットとデメリットを整理します。
メリット
- 複数の視点(ヘッド)で同時に計算を行うため、単語間の複雑な関係性を多角的に学習できます。
- 単語同士の距離に関わらず直接関連度を計算できるため、文の先頭と末尾にある単語の関係も正確に捉えることが可能です。
デメリット
- 計算の視点(ヘッド数)を増やすほど、処理に必要な行列計算の規模が大きくなり、メモリの使用量が増大します。
- 注意機構がどの単語に注目したのかという計算過程が複雑に絡み合うため、人間がAIの判断理由を解釈することが難しくなります。
次は、データの流れを支え、モデルの精度を高める周辺構造(Feed ForwardやAdd & Norm)について解説します。
情報を整理する順伝播ネットワーク
注意機構(マルチヘッドアテンション)が単語間の関連性を計算した後、計算されたデータは順伝播ネットワークに送られます。順伝播ネットワークは、各単語のデータを独立して処理し、情報をより扱いやすい形に変換および整理する役割を持っています。
順伝播ネットワークの働きを、工場における製品の製造ラインに例えて説明します。注意機構が複数の部品の関連性を見て組み立てを行う工程だとすれば、順伝播ネットワークは組み立てられた個々の製品に対して、それぞれ独立して品質チェックを行い、最終的な微調整を施す工程に該当します。微調整を行うことで、次の層へ渡すデータの品質を均一に保ちます。
情報の消失を防ぐ残差接続と層正規化
AIのモデル構造が深くなると、初期の入力データが持つ重要な情報が、計算を繰り返す過程で徐々に失われてしまうという問題が発生します。情報の消失を防ぎ、学習をスムーズに進めるための仕組みが、残差接続(Add)と層正規化(Norm)です。
残差接続は、ある計算処理を行う前の元のデータを、処理後のデータにそのまま足し合わせる仕組みです。高校の授業のノート作りに例えると、先生の板書(処理後のデータ)を新しく書き写すだけでなく、教科書の原文コピー(処理前のデータ)も横に貼っておくことで、いつでも元の正確な情報に立ち返ることができる状態と似ています。
層正規化は、データの数値のばらつきを一定の範囲に収める処理です。学校のテストの点数を偏差値に変換して評価基準を統一するように、層正規化によって各データ層の数値のスケールを揃えることで、AIの学習が安定しやすくなります。
周辺構造に関するメリットとデメリット
順伝播ネットワークと正規化の仕組みに基づくメリットとデメリットを整理します。
メリット
- 残差接続により、計算の層を深く重ねても元の情報が失われにくいため、より複雑な文章の文脈やパターンを学習させることが可能です。
- 層正規化によって数値の極端な変動が抑えられるため、学習の進行が安定し、計算処理の効率が向上します。
デメリット
- 順伝播ネットワークが各単語に対して個別の変換処理を行うため、モデル全体で保持すべきパラメータ(設定値)の数が大幅に増加します。
- パラメータが増加することで、学習済みモデルを保存するためのストレージ容量や、実行時のメモリ消費量が大きくなります。
次は、出力の生成過程とトランスフォーマーの応用について解説します。
線形変換による語彙の点数化
エンコーダとデコーダでの複雑な計算を経て、最終的にモデルから出力されるデータは数値のベクトルです。計算されたベクトルを、AIが知っているすべての単語(語彙)に対する点数に変換する処理が線形変換(Linear)です。
線形変換の作業を、高校の生徒会役員選挙に例えて説明します。全校生徒の性格や実績といった特徴(ベクトル)を分析し、立候補者全員に対して「誰が役員にふさわしいか」という基準で点数をつける工程に該当します。線形変換の段階では、候補者に対する点数はマイナスからプラスまで様々な値をとります。
ソフトマックスによる確率への変換
線形変換で得られた点数は、そのままでは「どの単語が次に選ばれる可能性が高いか」を比較しにくい状態です。点数を確率の形式に変換する役割を担うのがソフトマックス(Softmax)関数です。
生徒会選挙の例を続けると、ソフトマックス関数は各候補者の点数を、全員の合計が100パーセント(確率の合計が1.0)になるように計算し直す作業に相当します。得点が高い候補者は選ばれる確率が高くなり、明確な確率分布として出力されます。最終的に、最も確率の高い単語が次の単語として選ばれます。
数式表現として、入力された数値の集まりを確率に変換するソフトマックス関数の基本方程式は以下のように定義されます。

ここで数式内のeはネイピア数という定数を表しており、点数の差を指数関数的に強調する働きがあります。微小な点数差であっても、確率に変換する際に明確な差として表すことが可能になります。
トランスフォーマーから派生した現代のAI
トランスフォーマーの仕組みは、現在の生成AIの基礎技術として広く利用されています。
文章を生成することに特化したGPTシリーズなどのAIは、トランスフォーマーの右側にある「デコーダ」部分の構造を拡張して作られています。過去の単語から次に来る単語を予測する能力に優れています。
一方、文章の文脈を深く理解することに特化したBERTなどのAIは、左側にある「エンコーダ」部分の構造を発展させたモデルです。検索エンジンの意図理解や、文章の分類などに活用されています。
出力生成に関するメリットとデメリット
線形変換とソフトマックスによる出力処理のメリットとデメリットを整理します。
メリット
- すべての語彙に対する確率を計算するため、単に一つの正解を出すだけでなく、次に正解に近い候補も把握でき、文脈に応じた多様な文章を生成できます。
- 確率分布を用いることで、AIがその単語を選んだ確からしさ(自信度)を数値として客観的に評価することが可能です。
デメリット
- AIが学習している辞書の大きさが数万から十数万語に及ぶ場合、すべての単語に対して線形変換とソフトマックスの計算を行うため、処理に大きな負荷がかかります。
- 最も確率の高い単語を順に選んでいく仕組みであるため、必ずしも事実に基づいた正確な単語が選ばれるとは限らず、誤った情報を生成するリスクが存在します。
連載のまとめと今後の学習ステップ
全体を通じたトランスフォーマー構造の学習ステップの総括は以下の通りです。
- 文章が数値化され、並列処理によって全体像として扱われるデータの入り口を理解しました。
- 自己注意機構によって文脈が計算され、情報が劣化せずに伝達される内部構造を把握しました。
- 最終的な確率計算による単語の出力と、デコーダやエンコーダを用いた現代AIへの応用方法を学びました。
基礎的な理論の理解が完了しました。次の学習ステップとしては、実際のプログラミング言語を用いて小規模な言語モデルを構築するなど、実践的な実装の学習へ進むことを推奨します。
最後までお読みいただき、ありがとうございました。
セイ・コンサルティング・グループでは新人エンジニア研修のアシスタント講師を募集しています。
投稿者プロフィール
- 代表取締役
-
セイ・コンサルティング・グループ株式会社代表取締役。
岐阜県出身。
海外放浪の末、2000年創業、2004年会社設立。
IT企業向け人材育成研修歴業界歴20年以上。
すべての無駄を省いた費用対効果の高い「筋肉質」な研修を提供します!
この記事に間違い等ありましたらぜひお知らせください。
学生時代は趣味と実益を兼ねてリゾートバイトにいそしむ。長野県白馬村に始まり、志賀高原でのスキーインストラクター、沖縄石垣島、北海道トマム。高じてオーストラリアのゴールドコーストでツアーガイドなど。現在は野菜作りにはまっている。
最新の投稿
 山崎講師2026年8月1日コンピューターが数値計算の誤差に対処する仕組みと精度管理の方法
山崎講師2026年8月1日コンピューターが数値計算の誤差に対処する仕組みと精度管理の方法- 山崎講師2026年8月1日0乗が1になる理由を2乗の計算式から解説する指数法則の基礎
- 山崎講師2026年8月1日機械学習モデルの予測理由を解釈するSHAPとシャープレイ値の基礎
- 山崎講師2026年8月1日適合率と再現率の概念と初心者向けのわかりやすい再翻訳案