
情報理論の迷宮を解き明かす!KLダイバージェンスと交差エントロピーの意外な関係
 山崎講師
山崎講師こんにちは。ゆうせいです。
みなさんは、AIや機械学習のニュースで、モデルが学習するという言葉を耳にしたことはありませんか。コンピュータが学習するとき、実は裏側では数学を使って、正解と自分の答えがどれくらい離れているかを計算しています。その距離を測る物差しとして使われるのが、今回ご紹介するKLダイバージェンスと交差エントロピーです。
これらは似たような場面で登場しますが、ある条件が揃うと同じ値になることを知っていましたか。まずはそれぞれの言葉の意味から、ゆっくり紐解いていきましょう。
そもそもKLダイバージェンスと交差エントロピーとは何か
難しい名前が出てきましたが、怯える必要はありません。これらはどちらも、2つの確率分布がどれくらい似ているかを数値にするための道具です。
KLダイバージェンス(カルバック・ライブラー情報量)
KLダイバージェンスは、ある基準となる分布に対して、別の分布がどれだけズレているかを表す指標です。
これを日常の例えで説明しましょう。あなたが、あるラーメン屋さんの味を完璧に再現しようとしている職人だと想像してください。基準となる本家のレシピが確率分布 

本家の味と自分の作った味が完璧に一致していれば、ズレはゼロですよね。しかし、隠し味が足りなかったり、麺の太さが違ったりすると、その分だけズレが生じます。この味の違和感の総量が、KLダイバージェンスだと考えてください。
交差エントロピー
一方の交差エントロピーは、情報の伝え効率の悪さを表す指標です。
例えば、あなたが誰かにメッセージを送るとき、相手が予想もしないような意外な情報を送るには、たくさんの言葉が必要になります。逆に、相手が次に何を言うか100パーセント予想できているなら、言葉はほとんどいりません。
交差エントロピーは、本当は分布
二つの値が一致する魔法の瞬間
では、本題に入りましょう。KLダイバージェンスと交差エントロピーが同じ値になるのはどのような時でしょうか。
その答えを理解するために、数学的な関係を見てみましょう。交差エントロピーは、実は次のような構成になっています。
交差エントロピー = KLダイバージェンス +
この式をじっくり眺めてみてください。左側の交差エントロピーと、右側のKLダイバージェンスが等しくなるためには、おまけとしてついている
エントロピーがゼロになるとは
エントロピーとは、情報の不確かさや乱雑さを表す言葉です。これがゼロになるというのは、一点の曇りもなく、次に何が起こるか完全に予測できる状態を指します。
具体的には、ある1つの結果だけが確率 

- コインを投げたら、100パーセントの確率で表が出る。
- サイコロを振ったら、絶対に1の目しか出ない。
このような極端な状況、つまり基準となる分布
なぜこの違いを知ることが重要なのか
なぜこんな細かい違いを気にする必要があるのでしょうか。それは、私たちが何を最小化したいかによって、使い分ける必要があるからです。
| 項目 | 特徴 |
| KLダイバージェンス | 2つの分布の純粋な距離。一致すれば必ず になる。 |
| 交差エントロピー | 基準となる分布自身の複雑さも含まれる。計算がシンプル。 |
機械学習の世界では、正解データ(ラベル)は通常、1つの正解以外はすべてゼロという形式(ワンホットベクトルと呼ばれます)で与えられます。この場合、正解データのエントロピーはゼロになるため、交差エントロピーを最小にすることは、そのままKLダイバージェンスを最小にすること、つまり正解に近づけることと同じ意味になるのです。
計算が楽な方を選んでいるだけ、と考えると少し身近に感じませんか。
簡単な計算問題をやってみよう
数学の用語だけだと、どうしても頭が痛くなってしまいますよね。そこで、今回はとってもシンプルな「お菓子セットの確率」を使って、暗算でできるレベルの数字で解説します。
想像してみてください。あなたは今、2種類のお菓子(チョコとガム)が入った袋を作っています。
基準となる正解の配分
まずは、お手本となる完璧な配分を決めましょう。
- チョコ:
- ガム:
「この袋にはチョコしか入れない!」という強い意志を感じる配分ですね。この場合、次に何が出るか完全に決まっているので、迷いや不確かさ(エントロピー)は
あなたが作った配分
次に、あなたがうっかり作ってしまった配分を見てみましょう。
- チョコ:
(50パーセント)
- ガム:
半分ガムを混ぜてしまいましたね。これではお手本とズレています。
暗算で比較してみよう
ここで、交差エントロピーとKLダイバージェンスを計算する公式を、言葉に置き換えてみます。
交差エントロピーの計算
交差エントロピーは「お手本の確率 
- チョコの分:お手本
(自分の配分
- ガムの分:お手本
(自分の配分
ガムの分はお手本が
したがって、交差エントロピーは 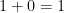
KLダイバージェンスの計算
KLダイバージェンスは「交差エントロピー 
- 交差エントロピーは、さっき計算した
- お手本の迷いは、チョコ
パーセントなので
引き算をすると、 
なぜ値が同じになったのか?
計算結果を見て驚きませんでしたか。どちらも「
これは、引き算の対象である「お手本の迷い」が 

つまり、正解が「これしかない!」と1点に決まっているとき、2つの物差しは完全に同じ動きをすることになります。AIの学習で「正解ラベル」を使うときは、まさにこの「これしかない!」という状態なので、どちらの言葉を使っても実質的な意味は変わらなくなるのです。
Pythonで確認
次に、実際にPythonなどのプログラミング言語を使って、簡単な確率分布を自作し、今回の式を計算させてみましょう。
import numpy as np
# 1. 神様の正解分布 P (100%晴れ)
p = np.array([1.0, 0.0])
# 2. あなたの予想分布 Q (50%ずつ)
q = np.array([0.5, 0.5])
# 交差エントロピーの計算
# 公式: -sum(p * log2(q))
# ※0で割るのを防ぐため、ごく小さな値を足すのが一般的です
cross_entropy = -np.sum(p * np.log2(q + 1e-9))
# KLダイバージェンスの計算
# 公式: sum(p * log2(p/q))
kl_divergence = np.sum(p * np.log2((p + 1e-9) / (q + 1e-9)))
print(f"交差エントロピー: {cross_entropy}")
print(f"KLダイバージェンス: {kl_divergence}")実行すると、どちらもほぼ 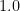

このコードで起きていること
このプログラムは、私たちが暗算でやったことを忠実に再現しています。
np.log2(q)で、あなたの予想に対する「驚き(情報量)」を計算しています。p * ...で、その驚きに「正解の重み」をかけています。np.sumで、それらを全部合計しています。
もし、あなたが神様と同じように「100パーセント晴れ!」と予想( ![[1.0, 0.0]](https://s0.wp.com/latex.php?latex=%5B1.0%2C+0.0%5D&bg=ffffff&fg=000&s=0&c=20201002)
交差エントロピーとKLダイバージェンスの使い分け
「結局、どっちも確率のズレを測るものじゃないの?」
その通りです。実はこの二つ、数学的には兄弟のような関係にあります。しかし、使いどころを間違えると、AIが何を学習すべきかを見失ってしまうこともあるのです。今回は、この絶妙な使い分けの理由を解き明かしましょう。
二つの指標を結ぶ「情報のパズル」
まず、言葉の意味を整理しましょう。
- 交差エントロピー:予測が正解からどれだけズレているか(コスト)
- KLダイバージェンス:二つの確率分布がどれだけ「似ていないか」(距離のようなもの)
数学的には、次のような関係式で結ばれています。
交差エントロピー 

ここで重要なのは、普通の分類問題(犬か猫か当てるなど)では、正解は「100パーセント猫」のように固定されているという点です。固定された数値(正解の複雑さ)を微分してもゼロになるため、学習の効率としては交差エントロピーもKLダイバージェンスも結果は変わりません。
では、なぜわざわざ「KL」を使う場面があるのでしょうか。
KLダイバージェンスが選ばれる理由
それは、正解(ターゲット)自体が固定されておらず、動的に変化する場合です。
師匠と弟子の稽古に例えてみましょう
交差エントロピーは「テストの採点」です。正解の解答用紙(100点)が決まっていて、そこから何点引かれたかを計算します。
一方で、KLダイバージェンスは「師匠の動きを完コピする弟子」の稽古に似ています。
- 師匠(先生AI)も人間のように柔軟な確率で動いている
- 弟子(生徒AI)は、師匠の「迷い」や「分布の形」そのものを真似したい
- 師匠の動きも刻々と変わるため、単純な正解・不正解ではなく「二つの個性の差」を測る必要がある
1. 知識蒸留(モデルの軽量化)
巨大で賢いAI(先生)の知識を、スマホでも動く小さなAI(生徒)に引き継がせるとき、生徒は先生が出す「これは90パーセント猫で、9パーセントは犬に見えるかも」という繊細な確率分布を丸ごと真似しようとします。この「分布の形の差」を測るには、KLダイバージェンスが最適なのです。
2. 生成AI(VAEなど)
画像を生成するAIなどは、データの背後にある「確率的な広がり」を学習します。データが特定の型(ガウス分布など)にどれくらい似ているかを強制したいとき、KLダイバージェンスを使って「分布を特定の形にギュッと寄せる」操作を行います。
メリットとデメリット
メリット
- 分布の形状を比較できる単なる正解当てではなく、データの「バラつき方」や「雰囲気」を模倣させることができます。
- 相対的な評価が得意二つの未知の勢力がどれくらい似ているかを測る羅針盤になります。
デメリット
- 非対称性「Aから見たBのズレ」と「Bから見たAのズレ」が一致しません。測る方向を間違えると、意図しない学習結果になることがあります。
- 計算の不安定さ片方の確率がゼロに近い場所にデータがあると、計算が無限大に飛んでしまうリスクがあり、取り扱いに注意が必要です。
まとめとこれからのステップ
いかがでしたか。単なる正解探しなら交差エントロピーで十分ですが、AIに「ニュアンス」や「分布の形」を教えたいときにはKLダイバージェンスが必須の道具になるのですね。
今回のポイントを整理します。
- 交差エントロピーとKLダイバージェンスは親戚関係
- 正解が「形」として与えられる場合(蒸留や生成)はKLが活躍する
- 「分布の差」を縮めることが、高度なAIの知能を作っている
さて、これでAIがどうやって間違いを定義し、それをリレー形式で伝え、偏微分で修正していくのか……という一連の流れが繋がりましたね!
ここからは、より実践的な「AIをどうやって効率よく、かつ安定して動かすか」という最適化のアルゴリズム(AdamやSGDなど)に目を向けてみると、さらに視界が開けるはずです。
セイ・コンサルティング・グループでは新人エンジニア研修のアシスタント講師を募集しています。
投稿者プロフィール
- 代表取締役
-
セイ・コンサルティング・グループ株式会社代表取締役。
岐阜県出身。
海外放浪の末、2000年創業、2004年会社設立。
IT企業向け人材育成研修歴業界歴20年以上。
すべての無駄を省いた費用対効果の高い「筋肉質」な研修を提供します!
この記事に間違い等ありましたらぜひお知らせください。
学生時代は趣味と実益を兼ねてリゾートバイトにいそしむ。長野県白馬村に始まり、志賀高原でのスキーインストラクター、沖縄石垣島、北海道トマム。高じてオーストラリアのゴールドコーストでツアーガイドなど。現在は野菜作りにはまっている。
最新の投稿
 山崎講師2026年8月1日コンピューターが数値計算の誤差に対処する仕組みと精度管理の方法
山崎講師2026年8月1日コンピューターが数値計算の誤差に対処する仕組みと精度管理の方法- 山崎講師2026年8月1日0乗が1になる理由を2乗の計算式から解説する指数法則の基礎
- 山崎講師2026年8月1日機械学習モデルの予測理由を解釈するSHAPとシャープレイ値の基礎
- 山崎講師2026年8月1日適合率と再現率の概念と初心者向けのわかりやすい再翻訳案
