新人研修で絶対マスターしたい!二分探索の完全テンプレート
 山崎講師
山崎講師プログラミングの研修を受けていると、避けては通れないのがアルゴリズムですよね。その中でも、特に重要で、かつ新人の皆さんが高確率でバグ(プログラムの不具合)を埋め込んでしまうのが二分探索です。
二分探索を完璧に理解して、一発で正解のコードを書けるようになりたくありませんか?今日は、Googleのエンジニアですら過去に間違えていたという驚きのポイントも含めて、初心者の方にも分かりやすく丁寧に解説します!
二分探索って何だろう?
二分探索とは、ソート(昇順や降順に並べ替え)されたデータの中から、目的の値を効率よく探し出す手法のことです。
例えば、辞書で「りんご」という言葉を探すとき、皆さんは最初のページから1枚ずつめくりますか?きっと、真ん中あたりをガバッと開いて、「ら行」より前か後ろかを確認しながら範囲を絞り込んでいくはずです。これが二分探索の基本的なアイデアです!
メリットとデメリット
二分探索には、他の探し方と比べてどんな特徴があるのでしょうか。
- メリット:とにかく速い!データが100万件あっても、わずか20回程度の比較で見つけ出せます。
- デメリット:データが必ずソート(整列)されていなければなりません。バラバラな並び順では全く役に立たないのです。
研修でそのまま使える!黄金のテンプレート
新人研修では、まずこの形を丸暗記する勢いで覚えてください。これが最もエラーが起きにくく、プロの現場でも使われる安全な形です。
public static int binarySearch(int[] nums, int target) {
int l = 0;
int h = nums.length - 1;
while (l <= h) {
int m = l + (h - l) / 2;
if (nums[m] == target) {
return m;
}
if (nums[m] < target) {
l = m + 1;
} else {
h = m - 1;
}
}
return -1;
}専門用語を高校生レベルで噛み砕こう
コードの中に登場した重要な用語を解説しますね。
1. 探索範囲の左右(l と h)
変数 l は left(左)、h は high(右、または high index)を指します。
これは「今、この範囲の中を探しているよ」という境界線です。最初は配列の端から端までをセットします。
2. 中央の値(m)
m は middle(中央)の略です。
探索範囲のど真ん中にあるデータの場所(添え字)を計算します。
3. 整数オーバーフロー
ここが一番のプロのこだわりポイントです!
通常、真ん中を求めるなら 
Javaの int という型には扱える数字の大きさに限界があります。もし l と h が非常に大きな数字だった場合、足した瞬間にその限界を超えてしまい、コンピュータが混乱してマイナスの値になってしまうのです。これを「整数オーバーフロー」と呼びます。
バケツ(型)から水(数値)が溢れてしまうイメージですね。これを防ぐために、
なぜ while (l <= h) なのか?
研修で一番多い質問が「なぜ < ではなく <= なのか?」という点です。
結論から言うと、イコールを忘れると「最後の1要素」を見逃してしまうからです!
例えば、データが [10, 20, 30] で 30 を探しているとしましょう。
計算を進めていくと、最終的に l も h も 2(30がある場所)になります。
もし条件が l < h だと、2 < 2 は間違いなので、そこで探索が終わってしまいます。目の前に答えがあるのに、チェックせずに帰ってしまうようなものです。もったいないですよね!
だからこそ、最後の一人までしっかり確認するために <= を使うのです。
驚異のスピード!計算量 O(log n) とは
二分探索の速さを表す言葉に O(log n)(オーダー・ログ・エヌ)があります。
これは、データが 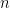
- 線形探索(端から探す):
- 二分探索:
回
| データ数 | 線形探索(最大) | 二分探索(最大) |
| 1,000 | 1,000回 | 約10回 |
| 1,000,000 | 1,000,000回 | 約20回 |
100万件のデータから、たった20回で見つけ出せるなんて、魔法みたいだと思いませんか?これがアルゴリズムの力です!
まとめと今後の学習指針
二分探索は、単に値を「探す」だけでなく、プログラミングにおける「境界線の考え方」や「計算効率」を学ぶ最高の題材です。
まずは今日紹介したテンプレートを、何も見ずに書けるようになるまで練習してみてください。それができたら、次は「同じ値が複数ある場合に、一番左にあるものを探すにはどうすればいいか?」といった応用問題にチャレンジしてみるのがおすすめです。
アルゴリズムの世界は奥が深いですが、一つずつ理解していけば必ず武器になります。一緒に頑張りましょう!
今回解説したオーバーフロー対策の書き方、明日から職場の先輩にドヤ顔で説明してみませんか?
次は、さらに一歩進んで「探索範囲の境界条件が異なるパターン」です。
探索範囲の「定義」を理解しよう
プログラミングにおいて、範囲の決め方は2種類あります。
- [l, h] : 両端を含む(閉区間)
- [l, h) : 右端を含まない(半開区間)
私たちが使っているテンプレートは 1番の「両端を含む」 スタイルです。 初期値を見てみましょう。
int h = nums.length - 1;
配列の最後のインデックスをしっかり指していますよね。つまり、「l から h までの間には、まだお宝(ターゲット)があるかもしれないよ!」という状態です。
運命の分かれ道:残り1要素のとき
一番ミスが起きるのは、探索の最後、候補がたった1つに絞られた瞬間です。
1. 最後の1要素の状態
例えば、配列 [10, 20, 30] から 30 を探しているとします。 計算が進むと、左端(l)も右端(h)も、30 が入っているインデックス「2」を指すことになります。
l = 2h = 2
このとき、探索範囲の中身はどうなっているでしょうか? インデックス2の「30」という要素が1つだけ残っています。
2. <= の場合(正解)
条件式が while (l <= h) だと、2 <= 2 は true です。 ループの中に入り、中央の値 m も 2 になります。 nums[2] をチェックして、「あった!30だ!」と見つけることができます。
3. < の場合(バグ)
条件式が while (l < h) だと、2 < 2 は false になってしまいます。 ループはここで終了。 「30」が目の前にあるのに、一度もチェックせずに「見つかりませんでした(-1)」と答えてしまうのです。
これこそが、新人が陥る「最後の1要素を見逃す罠」の正体です!
研修で役立つ「バグらせない」覚え方
もし迷ったら、こう自分に問いかけてみてください。
「l と h が同じ場所を指したとき、その場所の数字はもう調べたっけ?」
今回のテンプレートでは、ループの中で初めて nums[m] を調べるので、l == h になった瞬間はまだその場所を調べていません。だから、イコールをつけてもう一回だけループを回す必要があるんです。
まとめ:二分探索を極めるための指針
二分探索はシンプルに見えて、実は奥が深いアルゴリズムです。今後の学習では、以下のステップを意識してみてください。
- 基本の型を指に覚えさせる:今日紹介した安全なテンプレートを何も見ずに書けるようにする。
- 境界条件を意識する:なぜ
+1や-1をするのか、なぜ<=なのかを、図を書いて説明できるようにする。 - オーバーフローを意識する:
これができれば、あなたはもう初心者卒業です!現場で「この二分探索、オーバーフロー対策も完璧だね」なんて言われたら最高にカッコいいですよ。
「一番左のインデックスを返す」という処理は、実務でも非常によく使われます。例えば、大量のログデータから「ある時刻以降のデータがどこから始まるか」を特定するときなどに大活躍します。
この手法は専門用語で「Lower Bound(下限)」と呼ばれます。基本の二分探索と何が違うのか、図解を交えて優しく解説しますね!
1. 何が問題になるの?
通常の二分探索では、目的の値が見つかった瞬間に return m; して終了してしまいます。
例えば、[10, 20, 20, 20, 30] という配列から 20 を探す場合、運が良い(?)と真ん中のインデックス「2」を見つけてすぐに終わります。でも、私たちが知りたいのは「一番左の20」、つまりインデックス「1」ですよね。
「見つかってもすぐに帰っちゃダメだ!」というのが、このアルゴリズムの肝になります。
2. Lower Bound の考え方
基本のテンプレートを少しだけ改造します。ポイントは、ターゲットが見つかっても、さらに左側に候補がないか探し続けることです。
nums[m]がターゲット以上なら、その場所は「暫定的な答え」かもしれないけれど、もっと左にあるかもしれない。だから、右側の探索範囲を狭める(h = m)。nums[m]がターゲットより小さければ、左側には絶対に答えはない。だから、左側の探索範囲を狭める(l = m + 1)。
3. Lower Bound の安全なコード
新人研修で教える「最もバグが少ないLower Bound」の形がこちらです。
public static int lowerBound(int[] nums, int target) {
int l = 0;
int h = nums.length; // 注意:最後+1の範囲にする
while (l < h) {
int m = l + (h - l) / 2;
if (nums[m] >= target) {
h = m; // もっと左にあるかも!
} else {
l = m + 1; // ターゲットより小さいので右へ
}
}
return l; // 最終的に l が「一番左のインデックス」を指す
}
4. ここが違う!3つのポイント
高校生の皆さんにも分かるように、基本形との違いを例え話で説明しますね。
① 範囲の最後を nums.length にする
基本形は「家(要素)の中」を探していましたが、Lower Boundは「家と家の間の境界線」を探すイメージに近いです。そのため、一番右端のさらに外側まで含めて考えておくと、全ての要素がターゲットより小さかった場合にも正しく対応できます。
② 条件を l < h にする
基本形では「最後の一人」をチェックするために <= を使いましたが、Lower Boundでは l と h が重なった場所が自動的に「答え」になるように設計されています。
③ h = m でキープする
ここが最大の魔法です!もし nums[m] がターゲットと同じだった場合、h = m とすることで、今見つけた場所を範囲の右端として残しつつ、さらに左側を調べに行きます。
5. メリットとデメリット
- メリット: 同じ値が並んでいても、必ず「ここからその値が始まる」という場所を特定できます。
- デメリット: 「その値が存在しない」場合でも、その値を入れるべき場所(挿入位置)を返してしまいます。値が存在するかどうかを知りたいときは、最後に
nums[l] == targetかどうかを確認する必要があります。
まとめと今後の学習指針
Lower Boundが理解できると、「二分探索は単に値を探すだけでなく、境界線を見つけるアルゴリズムなんだ!」という深い理解に繋がります。
今後の指針としては:
- 「一番右側のインデックス」を返す Upper Bound も自分で考えてみる。
- ライブラリの中身を見てみる: Javaの
Arrays.binarySearchなどがどのような挙動をするか調べてみると面白いですよ。
実は、Java標準ライブラリの Arrays.binarySearch は、私たちが学んできた「基本のテンプレート」と非常によく似ていますが、「見つからなかったときの返し方」にプロの知恵が詰まっています。
1. 基本的な挙動は「基本形」と同じ
Javaの Arrays.binarySearch は、基本的には最初にご紹介した「while (l <= h)」の形を採用しています。
- 値が見つかった場合:そのインデックス(
以上の値)を返します。
- 値が見つからなかった場合:負の数 を返します。
この「負の数」の正体こそが、Javaの設計者のこだわりポイントなんです!
2. 負の数に隠されたメッセージ
単に「見つからないなら 
具体的には、以下の計算式で返ってきます。 返り値} = - 挿入ポイント - 1
なぜこんな計算をするの?
もし単純にマイナスを付けるだけ( -挿入ポイント)だと、挿入ポイントが 
そこで、必ず負の数になるように
3. 実例で見てみよう
例えば、 [10, 20, 30] という配列があったとします。
- 20 を探す場合 インデックス「1」にあるので、そのまま
が返ります。
- 25 を探す場合 25は入っていませんが、もし入れるなら「20と30の間」、つまりインデックス「2」の場所ですよね。 このとき、返り値は -(2) - 1 = -3 となります。
もしプログラムの中で「見つからなかったけど、正しい位置に追加したい」と思ったら、 -(返り値 + 1) と計算すれば、瞬時に挿入場所が分かります。便利だと思いませんか?
4. 注意点:同じ値が複数あるとき
ここ、テストに出るくらい重要です! Arrays.binarySearch は、同じ値が複数ある場合に「どれを返すか保証されていない」という特徴があります。
[10, 20, 20, 20, 30] で 20 を探すと、一番左のインデックス「1」が返るかもしれないし、真ん中の「2」が返るかもしれません。 もし「必ず一番左が欲しい!」という場合は、前回学んだ Lower Bound を自作する必要があるんです。
まとめと今後の学習指針
Javaの標準ライブラリは、単に便利にするだけでなく「エラーを減らし、次のアクション(挿入など)に繋げやすくする」工夫がされています。
- ライブラリを過信しない:同じ値が並ぶときの挙動など、仕様をしっかり確認する癖をつけましょう。
- ソースコードを読んでみる:開発ツール(EclipseやIntelliJなど)を使えば、
Arrays.binarySearchの文字の上でクリックするだけで、実際にJavaを作った人が書いたコードが読めます。
「プロが書いた本物のコード」を読むことは、どんな参考書よりも勉強になりますよ!
セイ・コンサルティング・グループでは新人エンジニア研修のアシスタント講師を募集しています。
投稿者プロフィール
- 代表取締役
-
セイ・コンサルティング・グループ株式会社代表取締役。
岐阜県出身。
海外放浪の末、2000年創業、2004年会社設立。
IT企業向け人材育成研修歴業界歴20年以上。
すべての無駄を省いた費用対効果の高い「筋肉質」な研修を提供します!
この記事に間違い等ありましたらぜひお知らせください。
学生時代は趣味と実益を兼ねてリゾートバイトにいそしむ。長野県白馬村に始まり、志賀高原でのスキーインストラクター、沖縄石垣島、北海道トマム。高じてオーストラリアのゴールドコーストでツアーガイドなど。現在は野菜作りにはまっている。