
新人エンジニア研修で知っておきたい配列の作り方と使い方
なぜ、配列の理解が重要なのか、その理由。
この記事では、弊社の新人エンジニア研修の参考にJavaを解説します。
前回は繰り返し処理について解説しました。コンピュータのすごさがあらためて感じられたのではないでしょうか?
今回は配列の作成と使用について解説します。これまで学んだとおり、プログラムでは基本的に変数に値を格納して処理を行います。では、変数が10個、20個、100個と増えていったらどうなるでしょうか?
名前を考えるだけでも大変ですね。そんな時に便利なのが配列です。
配列のイメージは同じ型の複数の値を入れる入れ物(変数)が並んだものです。(下図参照)
添字【index】を使って要素を指定しますからデータの探索も高速です。
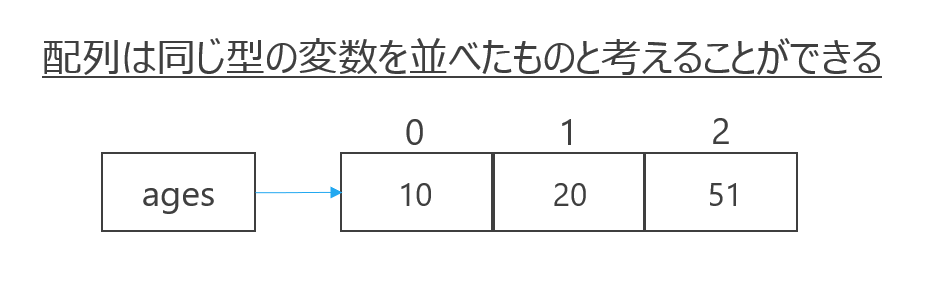
この章では以下のコードが書けることを目指します。
package chap06;
import java.util.Scanner;
import chap01.Kazuate;
public class KazuateArrayTest {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
Kazuate kazuate = new Kazuate();
int[] history = { -1, -1, -1, -1 };
System.out.println("0〜9の整数を当ててください!");
for (int i = 0; i < history.length; i++) {
System.out.print((i + 1) + "回目の予想:");
String str = sc.nextLine();
int guess = Integer.parseInt(str);
history[i] = guess;
kazuate.checkAnswer(guess);
System.out.println("結果:"
+ kazuate.getMessage());
System.out.println();
// 正解ならその時点で終了
if (guess == kazuate.getAnswer()) {
System.out.println("正解しました!ゲームを終了します。");
break;
}
}
// 結果のまとめ
for (int i : history) {
if(i == -1) {
break;
}
System.out.print(i + " ");
}
sc.close();
}
}1.配列の使い方
1.配列を表す変数を宣言します。
int[] ages;
データ型の後の[](角カッコ)が単なる変数ではなく配列であることを表しています。
2.配列の要素を確保します。[]の中の数値が要素数を表します。
ages = new int[3];
new演算子というものが使われています。new演算子はJavaでインスタンス化(実体化)を行う際に使われるものです。インスタンスについては後述します。
この段階では配列の中身は0が詰められている状態です。(下図参照)
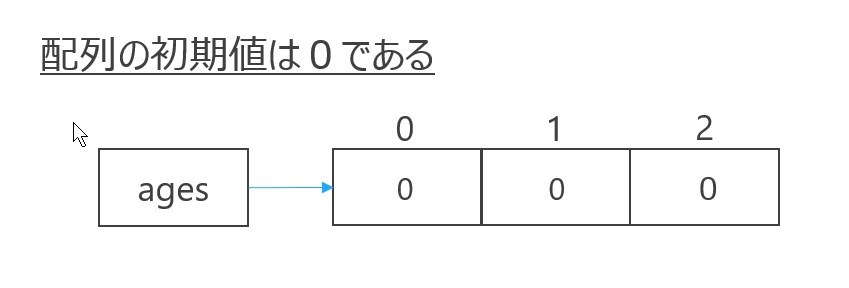
3.添字を用いて要素を指定し、配列に値を入れていきます。
ages[0] = 10;
ages[1] = 20;
ages[2] = 51;
このとき添字は0から始まるので、0,1,2と添字は2までしかないことに注意しましょう。
配列の添字(index)は0~(要素数-1)
4.配列に入っている値を添字を用いて参照します。
System.out.println(ages[2]);
51が表示されます。
初学者に多い間違いは配列の添字(上記の2)と要素(上記の51)を混同することです。気をつけましょう。
以下のExample01は配列の要素をfor文の繰り返しにより表示します。
package chap06;
public class Example01 {
public static void main(String[] args) {
int[] ages;
ages = new int[3];
ages[0] = 10;
ages[1] = 20;
ages[2] = 51;
for (int i = 0; i < 3; i++) {
System.out.println(ages[i]);
}
}
}<実行結果>
| 10 20 51 |
この例では、配列の要素を繰り返しによって表示させています。このように、配列とfor文は相性が良いです。
また、配列の大きさ(要素の数)は次のようにして確認できます。
変数名.length
変数名.lengthという表現を使えば、上記のfor文は以下のようにも書けます。
package chap06;
public class Example02 {
public static void main(String[] args) {
int[] ages;
ages = new int[3];
ages[0] = 10;
ages[1] = 20;
ages[2] = 51;
for (int i = 0; i < ages.length; i++) {
System.out.println(ages[i]);
}
}
}マジックナンバーが消えて意味が分かりやすく、また配列要素数の変更にも強いプログラムになりました。
また、以下Example03の6行目のように配列を一度に初期化する方法もあります。
package chap06;
public class Example03 {
public static void main(String[] args) {
int[] ages = {10, 20, 51};
for (int i = 0; i < ages.length; i++) {
System.out.println(ages[i]);
}
}
}<結果>は先と同じ。
この場合には、3という要素数は自動で決まります。
なお、デバッガで配列の要素を表示すると以下のように見えます。
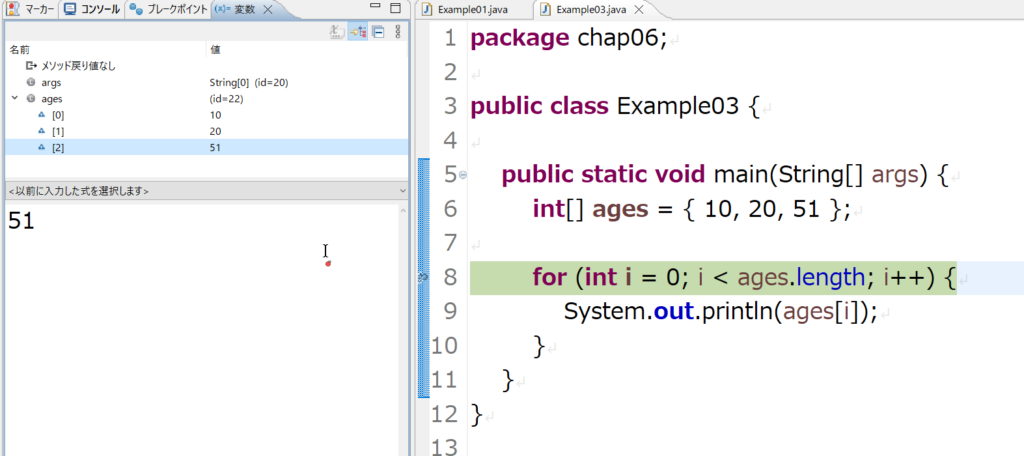
2.ArrayIndexOutOfBoundsException
以下のように配列の要素を3つ確保すると
ages = new int[3];
添字は0から始まるので、0,1,2の3つの要素が用意されるのでした。
では、以下のように存在しない要素を指定すると何が起こるでしょうか?
package chap06;
public class Example04 {
public static void main(String[] args) {
int[] ages;
ages = new int[3];
ages[3] = 10;
}
}以下のようなメッセージが出てプログラムの実行が中断されました。
| Exception in thread "main" java.lang.ArrayIndexOutOfBoundsException: Index 3 out of bounds for length 3 at chap06.Example04.main(Example04.java:7) |
このように存在しない要素にアクセスしようとした場合は、例外が発生します。今回発生した例外は、ArrayIndexOutOfBoundsExceptionという名前です。このとても長い名前を持つ例外は、
【Array:配列】の【Index:添字】が【OutOfBounds:範囲を超えた】【Exception:例外】という意味です。
配列は英語でarrayといいます。【set in array】「整列させる」という英語のイディオムを覚えた方もいるかも知れませんね。
これらのエラーメッセージにも意味がありますので、知らないものに遭遇したときには必ず、グーグルなどで調べるようにしてください。目を背けてはいけません。
「前もってIDEが例外の発生を教えてくれたらいいのに」と思ったかもしれません。しかし、詳しくは例外のところで後述しますが、この例外はコンパイラがチェックしてくれない例外なのです。コンパイラがチェックしてくれないので非チェック例外といいます。プログラマの責任で対処すべき例外なのです。
3.参照とハッシュ値
ところで、上記の例では、ages[0]には10が、ages[1]には20が、ages[2]には51が入っていました。
では、agesという変数には何が入っているのでしょうか?
System.out.println(ages);
としてみると、
[I@15db9742
上記の文字列が表示されました。(※上記は例です)
この文字列の@以降はハッシュコードと呼ばれるものです。ハッシュコードはデータの置き場所であるメモリのアドレスだと思っていただければ大きく違ってはいません。(以降、正確性を後退させ、分かりやすさを優先して、ハッシュコードはアドレスとして説明します)

ちなみにこのハッシュはごちゃまぜにするという意味でハッシュドビーフ【hashed beef】などと同じ語源です。
先頭の “[ ”は配列であることを意味しています。
ここまでのところを図解すると下図のようになります。
①JVMが管理するメモリ領域には大きく分けてスタック領域とヒープ領域の2つがあります。

スタック領域はローカル変数やメソッドが格納される領域です。【stack】には英語で「積み重ねた」という意味があります。積み重ねられた本のように、後から入れたものが先に取り出される構造をしています【Last-In First-Out(LIFO)】。

ヒープ領域はインスタンスが格納される領域です。英語の【heap】に「山積み、山盛り」という意味があり、メモリ容量が大きくなる可能性があるインスタンスはこのヒープ領域に格納されるのです。個人的には“インスタンス”領域と呼んでもいいと思うのですが、、、
例えば、スタック領域に格納されるプリミティブ型のデータは大きくてもdouble型の64bitです。対して配列などのインスタンスはどれだけ大きくなるかわからないためヒープ領域に格納します。例えるなら、家具屋さんで、店頭にはカタログだけ用意して、大きな商品は倉庫に置いておくようなイメージでしょうか。
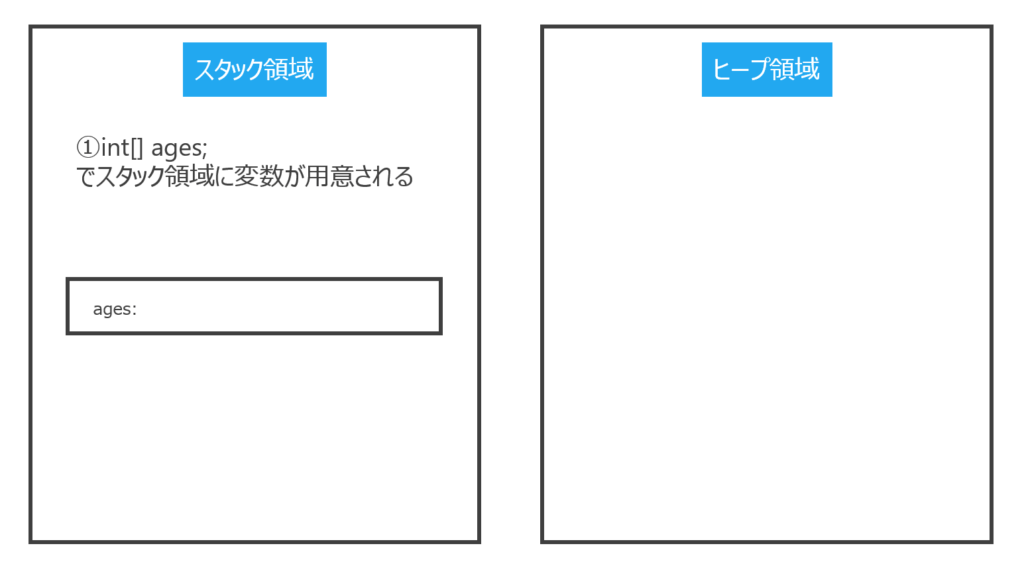
②メモリにはアドレスがあります。
ローカル変数に格納されるのは、配列が格納される予定のヒープ領域の先頭アドレス(ここでは15db9742)です。(下図参照)
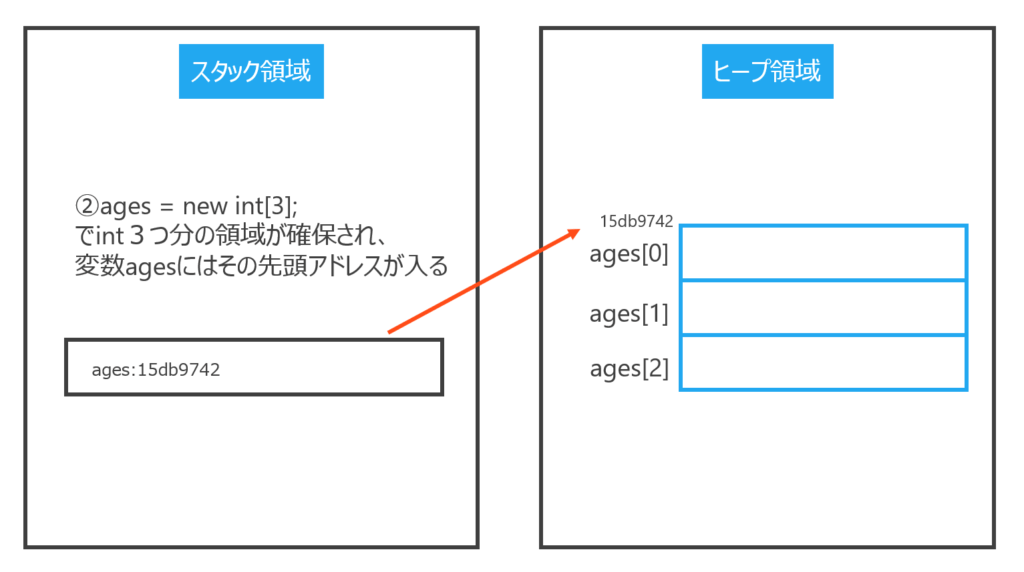
③要素がヒープ領域に格納されます。(下図参照)
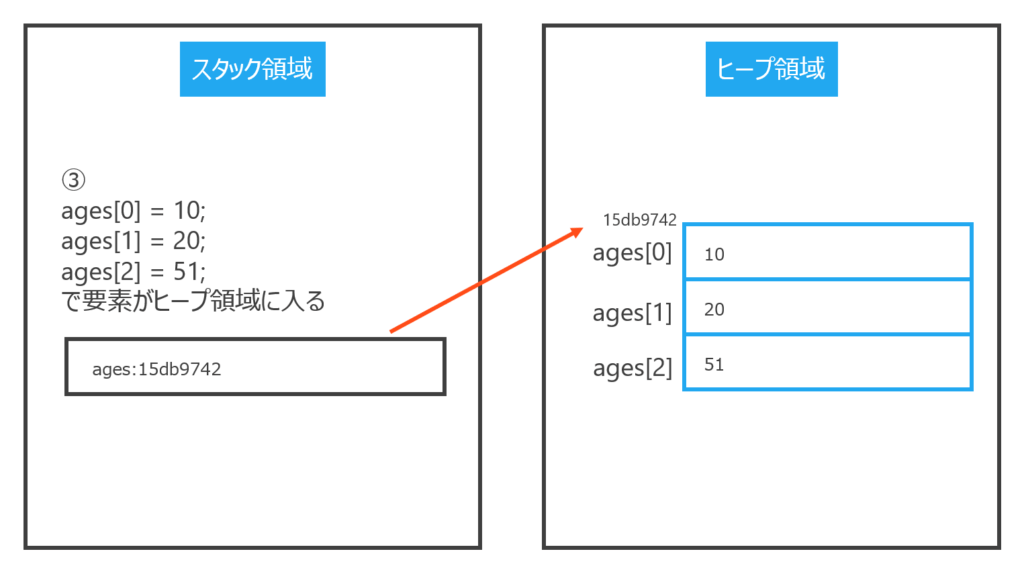
このような仕組みのため、
System.out.println(ages);
とすると以下の表示になるわけです。
[I@15db9742
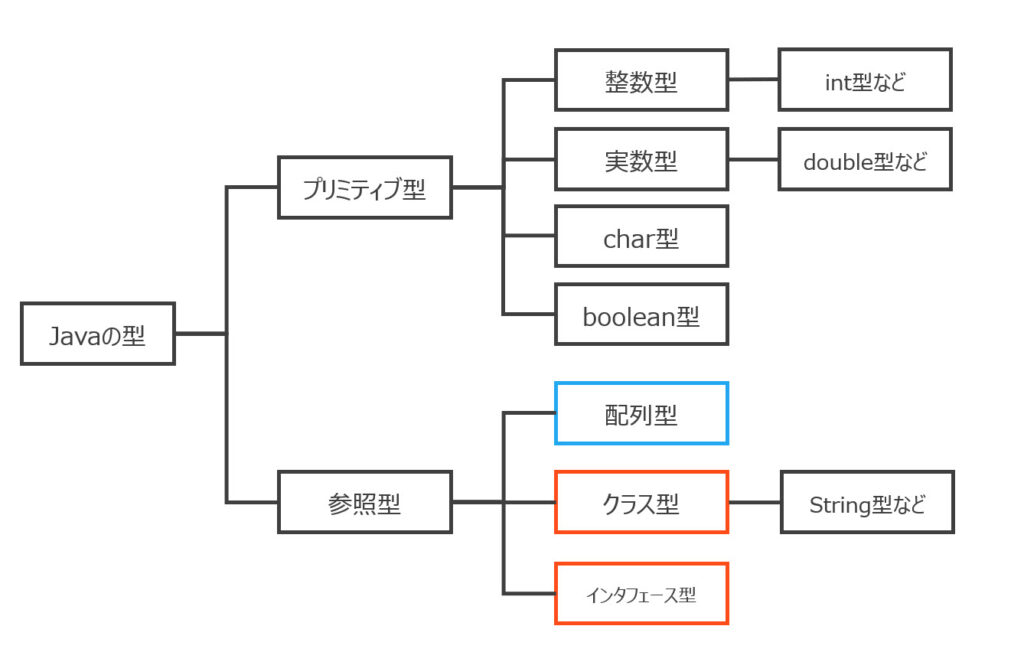
なお、Javaの参照型は以下の3つに整理されます。配列と、クラス(インスタンス)とインタフェースです。例えば、次回学ぶ文字列はクラス型に分類できます。これまでに学んだ型の知識を下図で整理しておきます。
4.配列の要素を一度に表示する
標準出力を使って配列の要素を一度に表示するにはどうしたらよいでしょうか?
毎回、繰り返し処理を使って表示させるのもおっくうです。そんな時に便利なのが配列の要素を文字列化してくれるArraysクラスのtoString()メソッドですArrays.toString()の意味は【Arrays】「配列を」【toString】「文字列へ」ということで、名が体を表すネーミングですね。デバッグ時に便利ですので覚えておいてください。
以下のExample05は配列の要素を一度に表示します。
package chap06;
import java.util.Arrays;
public class Example05 {
public static void main(String[] args) {
int[] ages = {10, 20, 51};
System.out.println(Arrays.toString(ages));
}
}※パッケージ宣言とクラス宣言の間に「import java.util.Arrays;」という一文を挿入する必要があります。IDEを使うと簡単に挿入できますので講師に教わってください。 また、importの意味は、2回目の記事でお話ししました。
<実行結果>
| [10, 20, 51] |
5.拡張for文
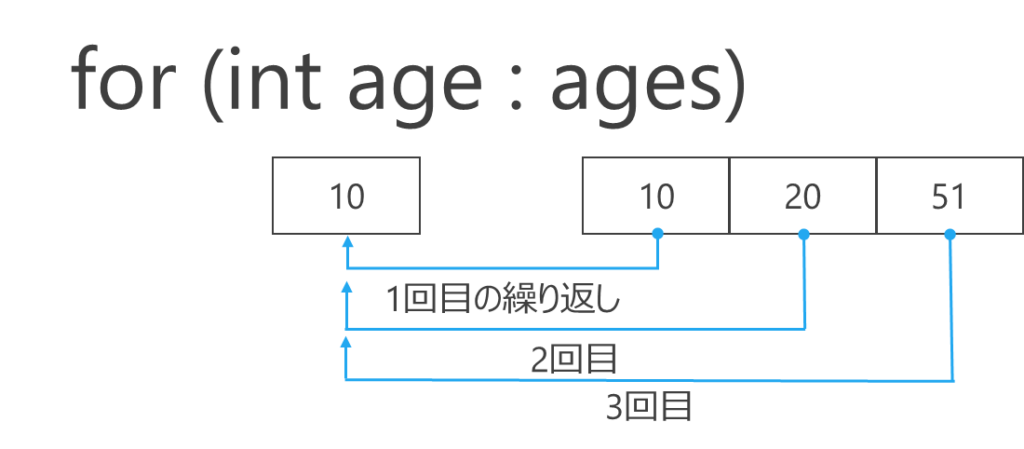
配列と相性が良いのが拡張for文です。拡張for文は、配列の先頭から最後までを連続して処理するときに簡潔に書ける構文です。配列の要素を0番目から一つずつ一時的な変数に格納して処理します。まずはイメージです。(下図参照)
<構文>
for(一時変数の宣言 : 配列の変数)
初学者の方はforの()の中の変数宣言と配列の変数指定の順番を逆にしないように気をつけてください。また、区切りは;(セミコロン)ではなく(:コロン)ですので間違えないようにしましょう。もっとも便利なIDEのコードテンプレートを使えば間違いないですが。なお、この(:コロン)は「中の」といった程度の意味です。
以下のExample06で確認してみましょう。
package chap06;
public class Example06 {
public static void main(String[] args) {
int[] ages = { 10, 20, 51 };
for (int age : ages) {
System.out.println(age);
}
}
}<実行結果>
| 10 20 51 |
このようにほんの少しですがシンプルに書くことができました。この拡張for文は、後に学ぶコレクション(ArrayList)でも活用されるため、今のうちに慣れておきましょう。
繰り返し処理をするために一時的に“使い捨て”の変数ageを使っています。この変数の値を繰り返し処理の中で変更しても元の配列には影響しませんので注意してください。以下はそのことを示すサンプルコードです。配列の要素をそれぞれ2倍にしたつもりですが、できていません。
package chap06;
public class Example07 {
public static void main(String[] args) {
int[] ages = {10, 20, 51};
for (int age : ages) {
System.out.println(age);
age *= 2;
}
for (int age : ages) {
System.out.println(age);
}
}
}<実行結果>
| 10 20 51 10 20 51 |
変数ageがローカル変数である以上、当然といえば当然ですが間違えやすいところです。
通常のfor文と比較した場合の拡張for文のメリットは、i ,j などのローカル変数が不要になり、先ほどのArrayIndexOutOfBoundsExceptionが発生する危険も無くなります。
一方、通常のfor文と比較した場合の拡張for文の制限は、必ず配列の先頭からの処理となることです。配列の後ろから処理をしたい場合は、直接対応できません。あらかじめ逆順にソートしておく前処理が必要になります。
さらに、配列の要素を一つおきに飛ばして処理を加えたい場合などにはあまり向かないでしょう。
そもそも配列やコレクションフレームワークが無ければ拡張for文は使えません。したがって通常のfor文が不要になるわけではありませんが、拡張for文が使える場面では拡張for文を優先させて下さい。
拡張for文は、このあとコレクションフレームワークというものを学ぶと重宝しますので。
調べてみましょう
2次元配列
ここまで作成してきた配列は1列でしたので1次元配列と呼ばれます。それに対して、2次元以上の配列を多次元配列といいます。ここでは、例として2次元配列を見ていきましょう。イメージとしてはエクセルの表に少し似ています。ただし、下図のように本当は1次元の配列を複数用意したものです。
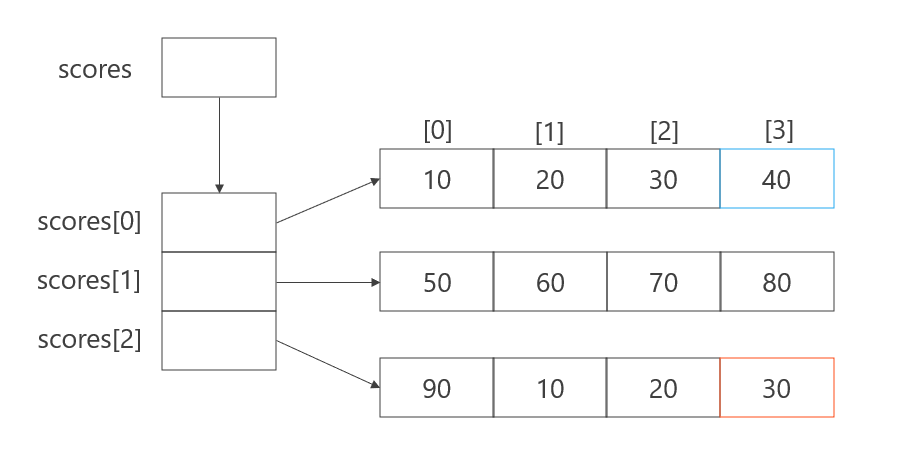
以下のExample08は2次元配列の例です。
package chap06;
public class Example08 {
public static void main(String[] args) {
int[][] scores = {
{10, 20, 30, 40},
{50, 60, 70, 80},
{90, 10, 20, 30}
};
System.out.println(scores[0][3]);
System.out.println(scores[2][3]);
for (int[] score : scores) {
for (int i : score) {
System.out.print(i + ",");
}
}
}
}<実行結果>
| 40 30 10,20,30,40,50,60,70,80,90,10,20,30, |
このようにシンプルに書けるのが拡張for文の良いところです。なお、拡張for文を入れ子にしていたところも大事です。
調べてみましょう
配列とオブジェクト指向
なお、配列の利用場面はかつてほどではありません。なぜなら、配列は要素数を後から変更できません。また、型の異なるデータを同じ配列に入れることもできません。これら配列の弱点を克服したArrayListについては後で学びましょう。(Javaでは、可変長リストを扱う際は ArrayList を使用するのが一般的ですが、固定長のデータ管理や高速アクセスが必要な場合には配列も有用です。)
昔は(といっても1990年代です)、オブジェクトという考え方が一般的でなく配列を使った処理を多用していました。例えば、以下は5名の生徒の成績を管理するプログラムです。
package chap06;
public class Example09 {
public static void main(String[] args) {
String[] label = {"Tom", "John", "Mary", "Ken", "Jimmy"};
int[] scores = {80, 75, 100, 90, 80};
for (int i = 0; i < scores.length; i++) {
System.out.println(label[i] + "'s score is " + scores[i]);
}
}
}<実行結果>
| Tom's score is 80 John's score is 75 Mary's score is 100 Ken's score is 90 Jimmy's score is 80 |
イメージは下図の通りです。

しかし、現代では1人分のデータは1人分のオブジェクト(より正確にはインスタンス)として表現することが一般的です。この点は何度も繰り返しお伝えしていくテーマなので、今は用語に慣れる程度で結構です。
以上、今回は「配列を使い大量データを便利に扱う」方法について見てきました。
次回は、「文字列を扱ってユーザーにメッセージを伝える」です。