
前回は検索を解説しました。
今回は、検索結果のソート、グループ化と集約関数を解説します。
1. 検索結果のソート
下図のようなcustomersテーブルに対して並べ替えを行ってみましょう。

本章で学ぶORDER BYを使わない限り、取得結果の並び順は保証されません。上記の例では、主キーであるcustomer_idの昇順に並べ替えがなされています。しかし、この並び順は保証されているわけではないのです。確実に意図した順番で表示したいときは並べ替えを行う必要があります。なお、並べ替えのことをソートとも言います。(そうとも言う笑)
問い合わせの結果を並べ替えるにはORDER BY句を使用します。また、並べ替えには昇順(ASC)と降順(DESC)があります。それぞれ、英語の【ascending】と【descending】の略です。
並べ替えキー列1 が同じ時には 並べ替えキー列2 で並べ替えが行われます。また、ASC,DESCを指定しなかった場合は ASCが指定されているものとみなされます。
ORDER BY句の例文 昇順
以下6_1.sqlは郵便番号の昇順で並べ替えるSQL文です。
SELECT
*
FROM
sip_a.customers
ORDER BY postalCode;<結果>

ORDER BY句の例文 降順
以下6_2.sqlは郵便番号の降順で並べ替えるSQL文です。
SELECT
*
FROM
sip_a.customers
ORDER BY postalCode DESC;<結果の例>
並べ替えでは照合順序が基準になるのですが、漢字の場合は意図しない結果になりますので気をつけましょう。
例えば、customersテーブルに対して以下6_3.sqlを発行したとします。
SELECT
*
FROM
customers
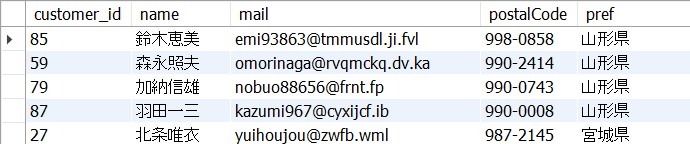
ORDER BY customers.nameすると下図の結果が得られました。

“いもと”さんと“まるた”さんの並び順が昇順になっていません。なぜ、このような並び順になるかということですが、それは文字コードの仕組みに秘密があります。
以下の表は文字コードを調べられるサイトを使って調べた8つの文字の文字コードです。
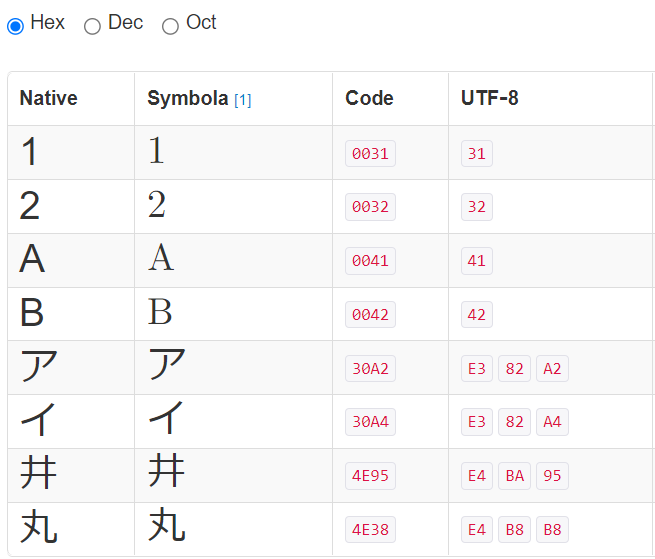
数値、アルファベット、カタカナまではCodeが読みの順に並んでいますが、漢字はそうなっていませんね。(もっとも漢字は色々な読み方がありますが…)というわけで漢字のフィールドを直接ソート対象にするのは避けるべきです。そこで実務では名前など並べ替えの必要のある項目はカタカナやひらがなのフィールドも作るのが一般的です。(今回は研修のため省略しています)
ORDER BY句の例文 抽出条件との組み合わせ
次に、prefが“愛知県”の顧客のcustomer_idを年齢の高い順に並べ替えてみましょう。
- 年齢が高いとは今回のcustomersテーブルの場合どういう風に判断できますか?
| あなたの答え: |
以下6_4.sqlを見てください。
SELECT
*
FROM
sip_a.customers
WHERE
pref = '愛知県'
ORDER BY birthday;年齢が高い人ほど生年月日(birthday)の値が小さくなります。したがって、ORDER BY birthday ASC で並べると年齢が高い順、ORDER BY birthday DESC で並べると若い順になります。
このように、ORDER BY句はWHERE句の後に来るということは覚えておきましょう。
<結果の例>

ORDER BY句の例文 キー列が複数
ORDER BYの第一条件の値が同じ場合、第二条件でさらに並べ替えられます。例えば、郵便番号で並べた後、同じ郵便番号内で誕生日が新しい順に並べるには以下のように記述します。
以下6_5.sqlを見てください。
SELECT
*
FROM
sip_a.customers
ORDER BY postalCode , birthday DESC;<結果の例>

今回名前や住所では並べ替えを行いませんでした。なぜなら、並べ替えの基準が文字コードだからです。アルファベットでしたらabc順に並べ替えることができます。しかし、日本語の場合はあいうえお順で並んでほしいのが一般的かと思います。その場合は、別途ひらがなフィールドを設けるなどの工夫が必要になるというのは前述のとおりです。
1.1. ソートの例題
例題
customers表を最初にprefの降順で並べ替え、同じ場合はbirthdayの昇順で並べ替えて全てのフィールドを抽出しなさい。(あまり意味はないが、、、)
<解答例>

2. グループ化
同じ値を持つデータごとにグループ化するにはGROUP BY句を使用します。
GROUP BY句を使ったグループ化
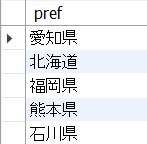
例えば、以下6_7.sqlはcustomersテーブルに存在しているprefをグループ化して抽出します。
※GROUP BYは、特定の列ごとにデータをグループ化するためのSQL句です。ORDER BYを指定しない場合、結果の並び順は保証されません。
SELECT
pref
FROM
sip_a.customers
GROUP BY pref;<結果の例>
以下6_8.sqlのようにGROUP BY句でグループ化の基準にしていないカラム(例: name)を、集計関数(SUMやAVGなど)で囲まずにSELECT句に指定することは、標準SQLのルールに反します。なぜなら、グループ化された結果、1行にまとまったデータの中から、どの行の『name』を表示すればいいのかデータベースが判断できないからです。
SELECT
pref, name
FROM
sip_a.customers
GROUP BY pref;
GROUP BY句を使用した場合にSELECT文の後ろのフィールド名に指定できるのは、
- GROUP BY句 でグループ化の対象になっているフィールド
- SUM(フィールド名)のように集計関数の対象になっているフィールド
のいずれかでなければなりません。なぜなら、表示の整合性が保たれないからです。
WHERE句とGROUP BY句の組み合わせ
以下6_9.sqlは生年月日が2001-01-01以降の人がいる都道府県をグループ化して抽出します。(YYYY-MM-DD形式なので文字列比較でも日付順と一致しています)
SELECT
pref
FROM
sip_a.customers
WHERE
birthday >= '2001-01-01'
GROUP BY pref;<結果の例>

3. 集約関数
合計や平均を求めるには集約関数を使います。集約関数は1つの列グループに対して演算結果を抽出します。列グループを指定しない場合はテーブル全体が列グループになります。
| 集約関数 | 意味 |
| SUM(引数列) | 引数列の合計値を取得する |
| AVG (引数列) | 引数列の平均値を取得する |
| MAX (引数列) | 引数列の最大値を取得する |
| MIN (引数列) | 引数列の最小値を取得する |
| COUNT (引数列) | 引数列のデータの件数を取得する |
以下の例を見てください。
以下6_10.sqlはcars表から、priceの合計、平均、最大値、最小値、件数を抽出します。
SELECT
SUM(price), AVG(price), MAX(price), MIN(price), COUNT(price)
FROM
sip_a.cars;<結果の例>
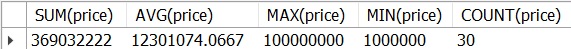
COUNTは引数に「*」を指定するとレコード数を取得します。(NULL値を含む全ての行がカウントされる)
また、COUNT引数にフィールド名を指定するとNULL値の行を除くすべての行がカウントされます。ちなみに、SUM, AVG などの集約関数も NULL を無視します。
以下6_11.sqlはcars表から、cars表のレコード件数とdeleted_atの件数を抽出します。
SELECT
COUNT(*), COUNT(deleted_at)
FROM
sip_a.cars;<結果の例>

例題
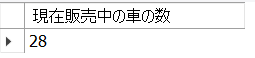
cars表から「現在販売中の車の数」を取得しなさい。
3.1. 集約関数とグループ化の組み合わせ
集約関数は先に見たグループ化と組み合わせて使用することが良くあります。グループ化と集約関数を組み合わせることにより「○○ごとの××」といった集計が可能になります。例えば、「商品ごとの売上合計」や「クラスごとの平均点数」といった集計です。
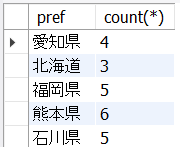
以下6_12.sqlはcustomers表から、都道府県ごとの人数を取得します。
SELECT
pref, count(*)
FROM
sip_a.customers
GROUP BY pref;<結果の例>
グループ化した結果を並べ替えることもできます。
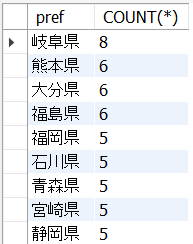
以下、6_13.sqlはcustomers表から、都道府県ごとの人数を取得し、人数が多い順に並べ替えています。
SELECT
pref, COUNT(*)
FROM
sip_a.customers
GROUP BY pref
ORDER BY COUNT(*) DESC;<結果の例>
例題
customers表から以下のように都道府県ごとの、人数、一番若い人の誕生日、一番歳をとった人の誕生日を取得し、人数の降順に並べ替えなさい。

3.2. グループ化した結果に抽出条件を加える
GROUP BY句でグループ化した結果に対して抽出条件で絞り込みを行いたい場合はHAVING句を使います。WHERE句の抽出条件と似ていますが、 1件1件のレコードではなく、グループ化した結果に対して条件で絞り込んで抽出するところがポイントです。
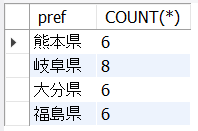
以下の6_14.sqlはcustomers表から、都道府県ごとの人数を取得し、5人超の prefと人数を抽出します。
SELECT
pref, COUNT(*)
FROM
sip_a.customers
GROUP BY pref
HAVING COUNT(*) > 5;<結果の例>
このようにGROUP BYと組み合わせて使うのが HAVING句です。WHEREは1行ごとのデータを対象に条件を指定し、HAVINGはグループ化されたデータに条件を適用します。
以上、検索結果のソート、グループ化と集約関数について見てきました。
次回は「複数テーブルに対する検索」の方法を見ていきましょう。