
標準誤差と標準偏差の違い
 山崎講師
山崎講師皆さんは「標準誤差」と「標準偏差」という言葉を聞いたことがありますか?
どちらも統計学でよく使われる言葉ですが、その違いについては、少しわかりづらいかもしれません。
言葉もよく似ていますしね。
今日は、この2つの概念について、わかりやすく説明していきますね。
結論
先に結論を言うと、次のようになります。
- 標準偏差: データのばらつきを示す。データがどれだけ平均値から離れているかを表す指標。
- 標準誤差: サンプルの平均値が母集団の平均値にどれくらい近いかを示す。標準偏差にサンプルサイズを反映させた指標。
以下に詳しく解説を加えます。
標準偏差とは?
まず、「標準偏差」について説明しましょう。標準偏差は、データのばらつき、つまりデータがどれくらい散らばっているかを示す指標です。例えば、クラスのテストの点数を考えてみてください。全員がほとんど同じ点数を取った場合、そのクラスの点数のばらつきは小さいと言えます。このばらつきを数値で表したものが標準偏差です。
標準偏差が大きい場合、そのデータは平均値から大きく離れた値が多いことを意味します。一方、標準偏差が小さい場合、そのデータは平均値に近い値が多いことを意味します。簡単に言うと、標準偏差が大きければ大きいほどデータの広がりが大きく、小さければ小さいほどデータは平均に集中しているということです。
標準偏差の計算方法
標準偏差を計算するためには、次の手順を踏みます。
- データの平均を求めます。
- 各データ点から平均を引き、その差を二乗します。
- その二乗した値の平均を取ります(これを分散と呼びます)。
- 分散の平方根を取ると、標準偏差が得られます。
例えば、以下のデータがあったとします。{5,7,9,10,11}\{5, 7, 9, 10, 11\}{5,7,9,10,11}
これらのデータの標準偏差を求める手順を表にまとめてみます。
| データ | 平均との差 | 平均との差の二乗 |
|---|---|---|
| 5 | -3.2 | 10.24 |
| 7 | -1.2 | 1.44 |
| 9 | 0.8 | 0.64 |
| 10 | 1.8 | 3.24 |
| 11 | 2.8 | 7.84 |
これらの二乗した差の平均を取ると、分散は4.68となり、その平方根が標準偏差です。つまり、この例の標準偏差は約2.16になります。
標準偏差の計算方法
標準偏差の計算式は次の通りです。
日本語で説明

統計の記号で説明
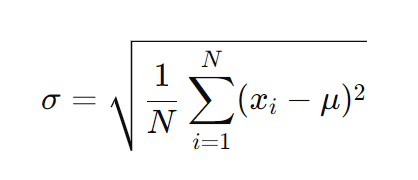
この数式は、母集団全体のデータが与えられた場合の標準偏差を計算する方法を示しています。データがサンプルの場合は、分母に N−1を使うことが一般的です。
標準誤差とは?
次に「標準誤差」についてです。標準誤差は、データの平均値がどれくらい正確であるかを示す指標です。これは少し難しいかもしれませんが、例えを使って説明しますね。
例えば、あなたがクラス全体の平均点を推測するために、クラスの一部の学生の点数を調査するとしましょう。その結果得られた平均点は、実際のクラス全体の平均点とは少し異なるかもしれません。このとき、調査したデータの平均がどれくらい本当の平均に近いかを測るのが標準誤差です。
標準誤差の計算方法
標準誤差を計算するには、標準偏差を使います。計算式は次の通りです。
日本語で説明


ここで、nはサンプルサイズ(調査したデータの数)です。つまり、サンプルサイズが大きければ大きいほど、標準誤差は小さくなり、平均値の推定がより正確になるということです。
または、サンプル標準偏差 sを用いる場合

ここせなぜ、サンプルサイズのnをルートに入れるのか疑問に思った方もいるかも知れません。
標準誤差の計算においてサンプルサイズ nの平方根(ルート)を使う理由は、サンプルサイズが増加するとサンプル平均のばらつきが小さくなるという統計的な性質に基づいています。
具体的には、サンプル平均は各データ点の平均値なので、サンプルサイズが大きくなるほど、各データ点の個々の変動(ばらつき)が相殺され、平均値が母集団の真の平均に近づいていきます。この「近づき方」は、サンプルサイズ nの平方根に反比例する形で表されるため、標準誤差を計算するときには nの平方根を使います。
この性質は「中心極限定理」とも関連しており、サンプルサイズが大きくなるとサンプル平均の分布が正規分布に近づき、そのばらつきが nの平方根で小さくなることを意味しています。
要するに、サンプルサイズが増えることで個々のデータ点の影響が小さくなり、サンプル平均が母平均に近づく速度を調整するために平方根を用いています。
もう一度、標準偏差と標準誤差の違いをまとめると
標準偏差と標準誤差の違いをまとめると、次のようになります。
- 標準偏差: データのばらつきを示す。データがどれだけ平均値から離れているかを表す指標。
- 標準誤差: サンプルの平均値が母集団の平均値にどれくらい近いかを示す。標準偏差にサンプルサイズを反映させた指標。
このように、標準偏差はデータそのものの広がりを測るのに対し、標準誤差はそのデータから計算された平均値がどれだけ信頼できるかを測るために使われます。
データ量を4倍にしたら標準偏差や標準誤差はどうなるか?
まずは結論です。
- 標準偏差: サンプルサイズを4倍にしても変化しません。
- 標準誤差: サンプルサイズを4倍にすると半分に減少します。
例えば、データ量を4倍にしたときに標準偏差や標準誤差がどうなるかを考えてみましょう。
データ量を4倍にした場合、標準偏差と標準誤差がどのように変化するかについて説明します。
1. 標準偏差(Standard Deviation)
標準偏差は、データのばらつきを示す指標で、データの各値が平均からどの程度離れているかを表します。標準偏差はサンプルサイズに依存せず、データの分布そのものの特徴を表すため、データ量を4倍にしても標準偏差は変化しません。
つまり、サンプルサイズが増えても、データのばらつき(標準偏差)が一定であれば、標準偏差はそのままです。
2. 標準誤差(Standard Error, SE)
標準誤差は、サンプルの平均が母集団の平均に対してどの程度ばらついているかを示す指標です。標準誤差は以下のように計算されるのでしたね。
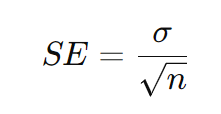
ここで、σは母集団の標準偏差、nはサンプルサイズです。
サンプルサイズが4倍になると、標準誤差の計算に使用される分母が以下のように変化します。

つまり、データ量(サンプルサイズ)を4倍にすると、標準誤差は元の値の半分になります。
標準偏差はデータの分布そのものの特徴を示すため、サンプルサイズに依存しませんが、標準誤差はサンプルサイズに依存し、サンプルサイズが大きくなると標準誤差は小さくなり、推定の精度が向上することを意味します。
まとめと今後の学習の指針
標準偏差と標準誤差は、統計学において非常に重要な指標です。データのばらつきを理解するために標準偏差が使われ、一方でそのデータから得られる平均の信頼性を評価するために標準誤差が使われます。これらを理解することで、データ分析の際により正確な結論を導き出すことができるでしょう。
今後は、これらの指標を使って実際のデータ分析に挑戦してみてください。何度も練習することで、統計の理解が深まるはずです。
投稿者プロフィール
- 代表取締役
-
セイ・コンサルティング・グループ株式会社代表取締役。
岐阜県出身。
海外放浪の末、2000年創業、2004年会社設立。
IT企業向け人材育成研修歴業界歴20年以上。
すべての無駄を省いた費用対効果の高い「筋肉質」な研修を提供します!
この記事に間違い等ありましたらぜひお知らせください。
学生時代は趣味と実益を兼ねてリゾートバイトにいそしむ。長野県白馬村に始まり、志賀高原でのスキーインストラクター、沖縄石垣島、北海道トマム。高じてオーストラリアのゴールドコーストでツアーガイドなど。現在は野菜作りにはまっている。

