
重回帰分析とは?
 山崎講師
山崎講師重回帰分析とは、複数の独立変数(予測に使用する要素)を使って、1つの従属変数(予測したい結果)を予測するための統計手法です。単回帰分析が1つの独立変数と1つの従属変数の関係を分析するのに対し、重回帰分析では2つ以上の独立変数を使って予測を行います。
たとえば、「家の広さ」「部屋の数」「築年数」など複数の要素を使って「家の価格」を予測する場合、これが重回帰分析になります。この手法を使うと、複数の要因がどの程度結果に影響を与えるかを同時に分析できるのです。
重回帰分析の基本的な考え方
重回帰分析では、予測したい従属変数 Y が、複数の独立変数 X1,X2,…,Xn の線形結合(足し合わせ)によって説明できると考えます。具体的には、次のような数式で表現されます。

この数式を見ると、各独立変数がどの程度従属変数に影響を与えているかがわかるのです。たとえば、家の価格を予測するモデルで「部屋の数」の係数 β1が大きければ、部屋の数が増えると家の価格も上がる傾向があることを示しています。
前提条件
重回帰分析(Multiple Regression Analysis)は、複数の独立変数を使って従属変数を予測する統計的手法ですが、この分析を適切に行うためにはいくつかの前提条件があります。以下に、重回帰分析で前提とされる主な条件を挙げます。
1. 独立変数と従属変数の線形性
- 独立変数と従属変数の関係が線形であることが前提です。これは、従属変数が独立変数の線形結合によって説明できることを意味します。
2. 残差の正規性
- 残差(予測値と実測値の差)が正規分布に従っていることが前提です。これは、モデルの予測誤差が特定のパターンを持たないことを示します。
3. 残差の等分散性(ホモスケダスティシティ)
- 残差の分散がすべての予測値に対して一定であることが前提です。等分散性が満たされていない場合、モデルの推定結果が信頼できない可能性があります。
4. 独立変数間の多重共線性の回避
- 独立変数間に強い相関がある場合、多重共線性の問題が生じ、推定結果の信頼性が低下します。多重共線性があると、モデルの係数の推定が不安定になる可能性があります。
5. 独立変数の独立性
- 観測データが相互に独立していることが前提です。つまり、ある観測データが他の観測データに影響を与えないという条件です。
6. アウトライヤーや異常値の影響がないこと
- 異常に高いまたは低い値(アウトライヤー)がモデルに過度の影響を与えると、結果が歪む可能性があります。
7. 独立変数と従属変数の相関関係
- 独立変数と従属変数の間に相関があることが前提です。相関がない場合、独立変数は従属変数の予測に役立ちません。
8. 独立変数の計測誤差がないこと
- 独立変数に誤差がある場合、結果の信頼性が低下する可能性があります。理想的には、独立変数は正確に計測されるべきです。
重回帰分析のメリットとデメリット
メリット:
- 複数の要因を同時に考慮できる: 現実世界では、1つの要因だけで何かを決めることは少なく、複数の要因が絡み合っています。重回帰分析を使うことで、そういった複雑な状況をモデル化できます。
- 予測力の向上: 独立変数を増やすことで、モデルがより正確に従属変数を予測できる可能性があります。
デメリット:
- 過剰適合のリスク: 独立変数を多く追加しすぎると、モデルが過剰にデータにフィットしすぎて、実際の予測力が低下することがあります。これは「オーバーフィッティング」と呼ばれます。
- 解釈の難しさ: 独立変数が多くなると、それぞれの変数が結果にどのように影響しているかを理解するのが難しくなることがあります。
重回帰分析の具体例
たとえば、ある大学の学生の学期末の成績を予測するとしましょう。この場合、「授業出席率」「課題提出率」「予習復習の時間」「アルバイトの時間」といった複数の独立変数を使って「学期末の成績」を予測できます。このように、学生の成績がどの要因に強く影響を受けているのかを分析することが可能です。
重回帰分析の精度を上げる方法
重回帰分析の精度を上げるためのいくつかの手法について詳しく解説します。
1. ダミー変数を使う
ダミー変数とは?
ダミー変数は、カテゴリカルデータ(質的データ)を重回帰分析に組み込む際に使われる技法です。カテゴリカルデータとは、例えば性別(男性、女性)、地域(東京、大阪、京都)など、数値としては表現されないが重要な情報を持つデータのことです。これらのデータは、直接回帰分析に使用することができないため、0または1の数値で表現されるダミー変数に変換する必要があります。
例: ダミー変数の使用
例えば、性別(男性と女性)を考えます。男性を0、女性を1とすることで、性別の影響を重回帰分析に組み込むことができます。もし、地域が3つ(東京、大阪、京都)ある場合、それぞれを表すために2つのダミー変数が必要になります。以下のように変換します。
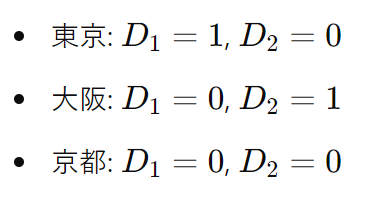
このようにして、カテゴリカルデータを回帰分析に含めることが可能になります。
なお、ダミー変数がすべて0のカテゴリ(この場合京都)のことを参照カテゴリ(または基準カテゴリ)と呼びます。
基準カテゴリーを使う理由は、ダミー変数の個数を減らして、過剰なマルチコリニアリティ(独立変数間の相関が非常に強い状態)を避けるためです。カテゴリカルデータにおけるすべてのカテゴリに対してダミー変数を作成すると、これらの変数は完全に相関する(合計が1になる)ため、回帰分析の計算に問題が生じます。
2. 対数変換を行う
対数変換の目的
対数変換は、データの分布が歪んでいる場合や、非線形な関係を線形化したい場合に使われます。特に、従属変数や独立変数の値が大きく変動する場合、対数を取ることでデータのばらつきを抑え、モデルの適合度を向上させることができます。
例: 対数変換の適用
例えば、収入と消費の関係を考えると、収入が増えると消費も増えるが、その増加は比例的ではなく、徐々に緩やかになることが一般的です。このような場合、消費額 Yと収入 Xの両方に対数を取ることで、次のようなモデルが得られます。
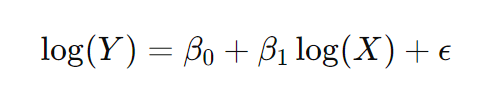
このモデルは、非線形な関係を線形に変換することで、より良いフィットを提供します。
3. ステップワイズ法を用いる
ステップワイズ法とは?
ステップワイズ法は、重回帰分析における独立変数の選択を自動化する手法です。すべての可能な独立変数を含めると過剰適合(オーバーフィッティング)になり、精度が低下する可能性があります。ステップワイズ法は、この問題を回避するために最適な変数の組み合わせを見つけます。
ステップワイズ法の種類
- 前進選択法(Forward Selection): 最初は変数を1つも含まないモデルから始め、ステップごとに最も有効な変数を追加していきます。
- 後退除去法(Backward Elimination): すべての変数を含むモデルから始め、ステップごとに最も効果の薄い変数を除去していきます。
- ステップワイズ選択法(Stepwise Selection): 前進選択と後退除去を組み合わせ、変数の追加と削除を繰り返しながら最適なモデルを選択します。
例: ステップワイズ法の適用
例えば、複数のマーケティング手法が売上に与える影響を分析したい場合、ステップワイズ法を使うことで、どの手法が最も効果的であるかを特定できます。無駄な変数を削除し、モデルの精度を高めることができます。
4. 交互作用項を考慮する
交互作用項とは?
交互作用項は、2つ以上の独立変数が一緒に従属変数に影響を与える場合に考慮される項です。個々の変数が与える影響とは別に、変数同士の相互作用が重要な場合があります。
例: 交互作用項の使用
例えば、広告費用(X1)と価格設定(X2)が売上(Y)に与える影響を考えると、単純にそれぞれの変数の影響を考えるだけでなく、広告と価格が組み合わさるとどのような効果が生まれるかを分析するために、交互作用項 X1×X2をモデルに含めることができます。
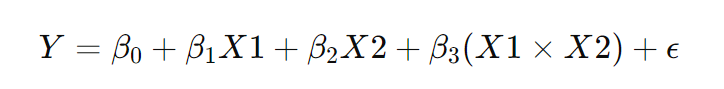
このようにすることで、より現実的なモデルが作成できる場合があります。
5. 変数の標準化を行う
変数の標準化とは?
変数の標準化は、独立変数のスケール(単位)を揃えるための手法です。特に、異なるスケールの変数を含む場合、標準化を行うことで、モデル内での変数間の比較が容易になります。一般的には、各変数をその平均で引き、標準偏差で割ることで標準化します。
例: 変数の標準化の必要性
例えば、売上(ドル単位)と従業員数(人数)が両方とも重回帰モデルに含まれる場合、それぞれのスケールが異なるため、標準化することで影響力を均等に比較できるようになります。
6. 多重共線性を回避する
多重共線性とは?
多重共線性は、独立変数間で強い相関がある場合に発生し、モデルの推定結果に悪影響を与える問題です。これが発生すると、推定された係数の信頼性が低下し、予測精度が下がる可能性があります。
例: 多重共線性の検出と対策
多重共線性は、VIF(Variance Inflation Factor)などの指標を使って検出します。VIFが高い場合、その変数は他の変数と強い相関があることを示します。この場合、以下の対策が考えられます。
- 相関の強い変数を除去する
- 主成分分析(PCA)を使って次元削減を行う
重回帰分析を学ぶ際のポイント
これから重回帰分析を学んでいく際には、まず単回帰分析を理解することから始めると良いでしょう。その後、複数の独立変数を取り入れた場合にどのように分析が複雑になるかを学んでいくと、重回帰分析の理解が深まります。また、統計ソフトやプログラミング言語(例えば、RやPython)を使って実際にデータを分析してみるのも効果的です。
統計学やデータサイエンスの分野では、重回帰分析は非常に強力なツールです。しっかりと理解し、活用できるようになると、様々な分野で役立つ知識になります。
投稿者プロフィール
- 代表取締役
-
セイ・コンサルティング・グループ株式会社代表取締役。
岐阜県出身。
海外放浪の末、2000年創業、2004年会社設立。
IT企業向け人材育成研修歴業界歴20年以上。
すべての無駄を省いた費用対効果の高い「筋肉質」な研修を提供します!
この記事に間違い等ありましたらぜひお知らせください。
学生時代は趣味と実益を兼ねてリゾートバイトにいそしむ。長野県白馬村に始まり、志賀高原でのスキーインストラクター、沖縄石垣島、北海道トマム。高じてオーストラリアのゴールドコーストでツアーガイドなど。現在は野菜作りにはまっている。

