
重回帰分析の様々なテクニック
 山崎講師
山崎講師重回帰分析は、複数の独立変数(予測変数)を用いて、1つの従属変数(結果変数)を予測するための統計手法です。単純な線形回帰と異なり、複数の要因が絡み合うデータを解析できるため、現実世界の複雑な問題を扱うのに役立ちます。しかし、現実のデータには様々な問題が含まれることが多く、これを解決するためにいくつかのテクニックが必要です。
今回は、その中でもよく使われる「対数変換」や「重回帰分析のその他のテクニック」について解説していきます。
対数変換とは?
対数変換(log transformation)は、データが非線形な関係を持っている場合に、それを線形化するための方法です。対数変換を行うと、元の変数の急激な変動が緩和され、より扱いやすい形になります。
例:収入と消費の関係
例えば、収入が増えるにつれて、消費も増えると仮定しましょう。ただし、収入が低いときは消費の変化が大きいですが、収入が高くなると、その変化は次第に小さくなることが一般的です。このような場合、単純に収入と消費を線形回帰でモデル化しようとしても、うまくいかないことがあります。対数変換を使うことで、変動のパターンを滑らかにし、回帰モデルが適切に当てはまるようにできます。
具体的には、次のような式に変換されます:
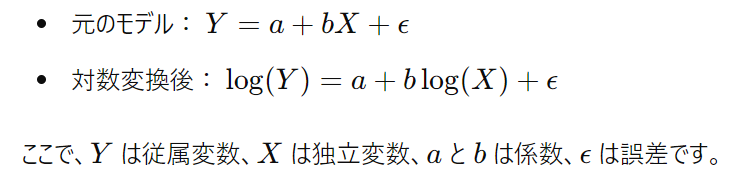
対数変換のメリット
- 線形性の確保: 多くの実際のデータは、直線ではなく曲線的な関係を持っています。対数変換を行うことで、直線的な関係に近づけることができます。
- 外れ値の影響を軽減: 大きな値を持つデータ(例:極端に高い収入など)は、重回帰分析において問題を引き起こすことがあります。対数変換を行うと、これらの外れ値の影響が小さくなります。
- データの分布の正規化: 回帰分析では、データが正規分布に従っていることが理想的です。対数変換を使うと、分布が歪んでいる場合でも、正規分布に近づけることができます。
対数変換のデメリット
- 負の値に対して使用できない: 対数変換は、0や負の値に対して適用できません。そのため、すべての変数に対して使えるわけではなく、適切な前処理が必要です。
- 解釈が難しくなることがある: 対数変換後の結果を解釈する際、元のスケールに戻す必要があり、その変換過程が初心者には混乱を招くことがあります。
その他の重回帰分析のテクニック
対数変換以外にも、重回帰分析ではさまざまなテクニックが用いられます。それぞれの手法を簡単に説明します。
1. 多重共線性への対処(VIF: Variance Inflation Factor)
多重共線性とは、複数の独立変数が互いに強い相関を持つ状態です。これが起こると、回帰係数の推定が不安定になり、モデルの解釈が難しくなります。
この問題を解決するためには、VIF(分散膨張因子)を用いて相関の強い変数を特定し、除去するか、合成変数に置き換える方法があります。
2. 交互作用項の追加
ある変数が他の変数に対してどのように影響を与えるかを考慮するために、交互作用項をモデルに追加することがあります。例えば、年齢と収入が消費に影響を与えるとしますが、若い人と年配の人で収入が消費に与える影響は異なるかもしれません。このような場合、年齢と収入の交互作用項(年齢 × 収入)を追加することで、より適切なモデルを構築できます。
3. 標準化(Standardization)
重回帰分析では、異なるスケールの変数が混在することがあります。例えば、年収が何百万単位で表される一方、年齢は数十単位です。このような場合、スケールの大きさがモデルに影響を与えることがあるため、標準化(平均を0、標準偏差を1に揃える変換)が有効です。
実際のデータでの活用例
仮に、ある企業が広告費(独立変数)をもとに売上(従属変数)を予測しようとしたとしましょう。広告費が少ないときは、売上が大きく変動しますが、広告費が増えるにつれて、その影響は小さくなっていくことが考えられます。このようなケースでは、対数変換を行うことで、広告費と売上の関係をより適切にモデル化することができます。
今後の学習の指針
重回帰分析には、今回紹介したテクニック以外にも、さまざまな前処理やデータ変換の方法があります。まずは、対数変換や多重共線性への対処、交互作用項などの基本的な手法を理解することから始めましょう。そして、次にモデルの精度向上や解釈力を高めるための手法(例:Lasso回帰やRidge回帰など)も学んでみると、より高度なデータ解析ができるようになるでしょう。
データの性質に応じた適切な手法を選ぶことが、信頼できる予測モデルを構築するためのカギです。
投稿者プロフィール
- 代表取締役
-
セイ・コンサルティング・グループ株式会社代表取締役。
岐阜県出身。
2000年創業、2004年会社設立。
IT企業向け人材育成研修歴業界歴20年以上。
すべての無駄を省いた費用対効果の高い「筋肉質」な研修を提供します!
この記事に間違い等ありましたらぜひお知らせください。
学生時代は趣味と実益を兼ねてリゾートバイトにいそしむ。長野県白馬村に始まり、志賀高原でのスキーインストラクター、沖縄石垣島、北海道トマム。高じてオーストラリアのゴールドコーストでツアーガイドなど。現在は野菜作りにはまっている。
最新の投稿
 新人エンジニア研修講師2026年6月19日Spring BootでセッションIDがアドレスバーに表示される理由と対策|新人エンジニア向けにJSESSIONIDを解説
新人エンジニア研修講師2026年6月19日Spring BootでセッションIDがアドレスバーに表示される理由と対策|新人エンジニア向けにJSESSIONIDを解説- 新人エンジニア研修講師2026年6月18日JavaのOptionalでnullを安全に扱う方法|NullPointerExceptionを防ぎ、DAOの戻り値をわかりやすくする
- 新人エンジニア研修講師2026年6月18日ローカルSMTPを使って問い合わせ完了メールを送る方法|新人エンジニア研修向けにSpring BootとJavaMailSenderを解説
- 新人エンジニア研修講師2026年6月18日DevToolsでHTTP通信・エラー・DOMを確認する方法|新人エンジニア向けにブラウザ開発者ツールを解説
