
【初心者向け】Seq2Seq(シーケンス・トゥ・シーケンス)とは?仕組み・活用例・注意点までやさしく解説!
 山崎講師
山崎講師
こんにちは。ゆうせいです。
今回は「Seq2Seq(シーケンス・トゥ・シーケンス)」という、AIや自然言語処理の世界では非常に重要なモデルについて、エンジニア1年目の方にもわかりやすく解説していきます。
1. Seq2Seqってそもそもなに?
Seq2Seq(Sequence to Sequence)は、名前のとおり「ある時系列データ(シーケンス)を別の時系列データに変換するモデル」のことです。
たとえば次のような応用があります:
| 入力(Input) | 出力(Output) | 用途 |
|---|---|---|
| 英語の文章 | 日本語の文章 | 機械翻訳 |
| 質問文 | 回答文 | 質問応答システム |
| メールの本文 | 要約文 | テキスト要約 |
| 音声のスペクトログラム | 文字列(字幕など) | 音声認識 |
「英語→日本語」に翻訳する例で考えてみましょう。
これは、「英語という単語の並び(シーケンス)」を「日本語の単語の並び(別のシーケンス)」に変換する問題ですよね。こういう変換を得意とするのがSeq2Seqです!
2. Seq2Seqの基本構造を図で見てみよう!
基本は「Encoder-Decoderモデル」
Seq2Seqの仕組みは、エンコーダー(Encoder)とデコーダー(Decoder)の2つから成り立っています。
入力シーケンス → [Encoder] → 中間ベクトル → [Decoder] → 出力シーケンス
図にすると以下のようになります:
Input: [I] [like] [cats]
↓
┌──────────────┐
│ Encoder │(時系列の情報を圧縮)
└──────────────┘
↓
Context(文の意味ベクトル)
↓
┌──────────────┐
│ Decoder │(文を展開)
└──────────────┘
↓
Output: [私] [は] [猫] [が] [好き]
例えるなら…
Encoderは「話の内容をギュッと要点だけ覚えるメモ帳」
Decoderは「そのメモ帳を読みながら話を展開していくプレゼンター」
…みたいな関係です。
3. 数式で見てみよう(初心者向け表記付き)
エンコーダーは、入力シーケンスを1つのベクトルに変換します。 ht=f(xt,ht−1)h_t = f(x_t, h_{t-1})
(入力 $x_t$ と1つ前の状態 $h_{t-1}$ を使って、現在の状態 $h_t$ を計算)
その最後の状態 $h_T$ をコンテキスト(context vector)としてデコーダーに渡します: st=g(yt−1,st−1,hT)s_t = g(y_{t-1}, s_{t-1}, h_T)
(デコーダーでは、直前の出力 $y_{t-1}$、直前の状態 $s_{t-1}$、コンテキスト $h_T$ を使って次の出力 $s_t$ を予測)
この流れを1単語ずつ繰り返して、出力シーケンスを作っていくんですね!
4. よくある疑問:「なんでベクトルにするの?」
「文をベクトルにする」って、ちょっと不思議ですよね。
でもこれは、コンピュータにとっては「数値」で考えることがとても大切だからなんです。
ベクトルというのは、「意味」を数値で表現したもの。
たとえば「cat」は [0.4, 0.1, 0.7]、「dog」は [0.5, 0.2, 0.6] みたいに。
このように、似た単語は似たベクトルになります。なので、意味を保ったまま変換ができるのです!
Word2Vecとの関係
ここで登場する「単語をベクトルに変換する技術」の中でも、非常に有名なのが Word2Vec(ワード・トゥー・ベック) です。
Word2Vecは、単語と単語の関係性を学習して、意味的に近い単語を「近いベクトル」で表現できるようにするモデルです。
たとえば、
king - man + woman ≈ queen
のように、「王様から男性性を引いて女性性を足すと、女王に近くなる」なんてこともベクトル計算で表せるのです。
このWord2Vecのような単語埋め込み(word embedding)は、Seq2Seqモデルの中でも最初のステップとしてよく使われています。
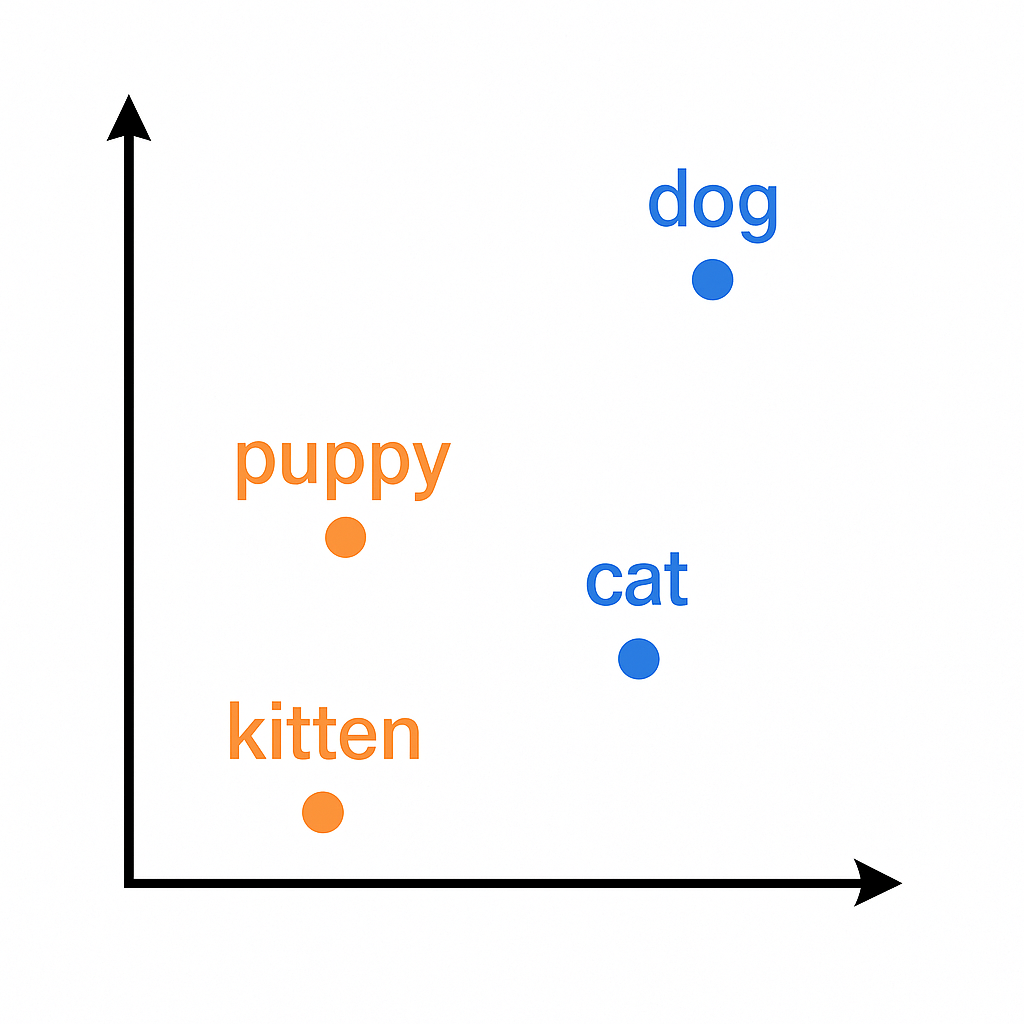
なぜかというと…
エンコーダーに渡す前の単語は、ただの文字列("cat" や "dog")です。このままでは数値計算ができないので、まずはベクトルに変換する必要があるんですね。そこで、Word2Vecなどで「意味を含んだ数値」に変換してから、Seq2Seqの処理がスタートするのです。
他にも似た技術があるよ!
現在は、Word2Vecの他にも、
- GloVe(グローブ)
- FastText(ファストテキスト)
- BERT(コンテキストを考慮した埋め込み)
といった技術も使われていますが、Word2Vecはその基礎を築いた大事なモデルとして、今でも多くの場面で活用されています。
このように、Word2VecとSeq2Seqは直接は別の技術だけど、実は密接に関係しているんですね!
5. Seq2Seqのデメリット・注意点
もちろん良いことばかりではありません。以下のような課題もあります:
| 課題 | 内容 |
|---|---|
| 長い文の処理が苦手 | 全体を1つのベクトルに圧縮するため、文が長くなると意味を失いやすい |
| 学習に時間がかかる | エンコーダーとデコーダーの両方を訓練する必要があり、コストが高い |
| 翻訳の精度に限界がある | 前の出力だけを見て次を予測するので、前後の文脈を見逃すことがある |
6. 改良技術:Attention(アテンション)
この課題を解決するために登場したのが「Attention(アテンション)機構」です!
ざっくり言うと、「文の中でどこを注目すればいいかを自動で判断してくれる技術」。
まるで「英語の文のどの単語が、どの日本語に対応してるかを地図のように教えてくれる感じ」です。
7. どんな分野で使われているの?
以下のように幅広い分野で活用されています。
- 機械翻訳(Google翻訳など)
- 音声認識(スマホの音声入力)
- 自動要約(ニュースの要約)
- チャットボット(会話AI)
- プログラムのコード生成
最近は、このSeq2Seqをベースにして発展した「Transformer」や「ChatGPTのような大規模言語モデル」が登場して、より高精度な変換が可能になっています。
8. 今後の学習のヒント
ここまで読んで、「なんとなくわかったけど、もっと深く知りたい!」と思った方も多いのではないでしょうか?
次は以下のキーワードを順に調べてみると、より理解が深まりますよ!
- RNN(再帰型ニューラルネットワーク)
- LSTM(長短期記憶)
- Attention(アテンション)
- Transformer(トランスフォーマー)
- BERT、GPTといった大規模言語モデル
さらに、PythonやPyTorchを使って簡単なSeq2Seqモデルを自作してみると、理解が一気に深まります!
気軽に試して、どんどん疑問を持って、手を動かしていきましょう。応援しています!
生成AI研修のおすすめメニュー
投稿者プロフィール

