
機械学習の「縁の下の力持ち」!標準偏差がデータ前処理で最強な理由を徹底解説
 山崎講師
山崎講師こんにちは。ゆうせいです。
「機械学習」と聞くと、なんだかAIが自動で賢くなっていく、魔法のようなイメージがありませんか? でも実は、その「魔法」をしっかり機能させるために、非常に地味ですが大切な「下ごしらえ」が必要なんです。
そして、その下ごしらえで大活躍するのが、学生時代に統計で習ったかもしれない「標準偏差」。
「え、あの地味な標準偏差が?AIと何の関係が?」
そう思った新人エンジニアのあなた。大アリなんです!
この記事では、標準偏差が機械学習、特に「データの前処理」というステップで、どれほど重要な役割を果たしているのかを、例えをたくさん使いながら解説していきますね。
そもそも「標準偏差」って何だっけ?
まずは復習からいきましょう。標準偏差(Standard Deviation、略してSDとも言います)とは、一言でいうと「データのばらつき具合を示す数値」です。
平均値だけでは見えないことが、標準偏差でわかります。
例え1:クラスのテストの点数
例えば、A組とB組、どちらもクラスの平均点は70点だったとします。
- A組:標準偏差が 5点
- これは、みんなの点数が平均点(70点)の近くにギュッと集まっている状態です。だいたい65点〜75点の間にほとんどの生徒がいるイメージですね。
- B組:標準偏差が 20点
- これは、点数のばらつきが非常に大きい状態。30点の生徒もいれば、100点の生徒もいる。点数が広い範囲に散らばっているのがわかります。
平均点は同じ「70点」でも、データの「顔つき」は全然違いますよね? この「顔つき=ばらつき度」を教えてくれるのが標準偏差なんです。
例え2:的当て(ダーツ)
あなたがダーツを10回投げたとします。
- 標準偏差が小さい:10本の矢が、中心のブルの周りにキュッと集まっている状態。狙いが定まっています。
- 標準偏差が大きい:10本の矢が、ボード全体に散らばってしまっている状態。狙いが定まっていません。
標準偏差は、データがどれだけ「平均」という中心から離れて散らばっているかの「平均的な距離」だとイメージしてください。
機械学習と標準偏差の「密接な関係」
さて、本題です。この「ばらつき具合」が、どう機械学習に関係するのでしょうか。
最大の活躍場所は、「データの前処理」、その中でも特に「標準化(Standardization)」と呼ばれる作業です。
機械学習モデルは「単位」に弱い
機械学習モデルの多くは、実は「単位」や「数値のスケール(大きさの尺度)」を区別するのが苦手です。
例え3:優秀な社員を評価するAI
あなたがAIを作るとしましょう。目的は、「2人の候補者のうち、どちらがより優秀か」を判定することです。
データとして、以下の2つを使います。
- 身長(単位:メートル。例:1.7m, 1.8m)
- 年間売上(単位:円。例:500,000,000円, 550,000,000円)
このデータをそのままAIに投入すると、何が起きるでしょう?
AIは数値の「大きさ」に引っ張られてしまいます。「身長」は1.7や1.8という小さな数値なのに、「年間売上」は5億、5億5千万という巨大な数値です。
AIは「うわっ!年間売上っていうデータ、数値がめちゃくちゃデカい!これは超重要なデータに違いない!」と勘違いしてしまうんです。
身長も売上も、どっちが重要かなんて、まだわからないはずですよね?
このように、データの「単位」や「スケール」が違いすぎると、AIは「数値が大きい特徴量(データ項目)=重要」というバイアスを持って学習を始めてしまいます。これでは、公平な判断ができません。
そこで登場!「標準化」
この問題を解決するのが「標準化」です。
標準化とは、「すべてのデータを、平均0、標準偏差1のスケールに揃えてしまう」という作業です。
先ほどの「身長」も「年間売上」も、計算によって「平均0、標準偏差1」の姿に変換します。
例え4:国際的な料理コンテスト
想像してください。アメリカ人審査員(ヤード・ポンド法)と、日本人審査員(メートル法)がいます。
それぞれが自分の国の単位で採点したら、点数がバラバラで比較できませんよね?
そこで、「全員、100点満点で採点し直してください」とルールを決めるようなものです。
標準化は、まさにこの「ルールの統一」。データの単位やスケールの違いを吸収し、「同じ土俵」で比較できるようにする作業なんです。
標準化の計算式
この標準化を行うときに、標準偏差が必須になります。
標準化された値(zスコアとも言います)は、以下の式で計算されます。



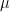
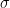
元の値を「平均からどれだけ離れているか?」で測り、それを「標準偏差(平均的な離れ具合)の何倍か?」という値に変換しているわけです。
この計算のおかげで、身長も売上も、まったく同じ「平均0、標準偏差1」という土俵に立つことができるのです。
標準化のメリットと注意点
メリット
- 公平な学習一番のメリットは、先述の通り「AIが公平に学習できる」ことです。数値の大きさに惑わされず、各データの特徴をフラットに見てくれるようになります。
- 学習の高速化少し難しい話になりますが、多くの機械学習アルゴリズム(特に勾配降下法を使うもの)は、データのスケールが揃っている方が、答え(最適なモデル)にたどり着くスピードが圧倒的に速くなります。
注意点:標準化が不要なモデルもある
ただし、どんなモデルでも標準化が必要かというと、そうではありません。
例えば、「決定木」や「ランダムフォレスト」といったモデルは、データの大小関係(例:身長が175cmより高いか低いか)で判断を分岐させていくため、元の数値のスケールには影響されません。
「どのモデルに標準化が必要で、どれに不要か」を理解することも、エンジニアとしての一歩になります。
他にもある!標準偏差の使い道
標準化以外にも、標準偏差は活躍します。
1. データの理解(EDA)
まず、データ全体を眺めるとき。「このデータ、どれくらいばらついてるんだろう?」を把握するのに使います。標準偏差が極端に大きければ、「もしかして、とんでもない値(外れ値)が混じってるかも?」と疑うきっかけになります。
2. 外れ値の検出
「平均から標準偏差の3倍以上(または3倍以下)離れているデータは、異常値(外れ値)とみなす」という「3シグマ法」というシンプルなテクニックがあります。これも標準偏差を使っていますね。
まとめと今後の学習
いかがでしたか?
地味に見えた「標準偏差」が、機械学習モデルの性能を左右する「標準化」という超重要な前処理に不可欠な存在であることが、お分かりいただけたでしょうか。
データの前処理は、派手なAIモデルを作る影で、非常に重要な作業です。「ゴミを入れればゴミが出てくる(Garbage In, Garbage Out)」という言葉があるように、AIに「キレイで食べやすい」データを渡してあげるのが、私たちの仕事です。
標準偏差は、そのための最強の道具(包丁や計量カップ)の一つなのです。
次のステップ
- 実際にやってみよう!Pythonのライブラリ scikit-learn には、この標準化を一行でやってくれる StandardScaler という便利な機能があります。まずは使ってみて、データがどう変わるか見てみましょう。
- 「正規化」との違いを学ぼう標準化と似た作業に「正規化(Normalization)」があります。これはデータを0〜1の範囲に押し込める手法です。標準化とどう使い分けるのか、調べてみると理解が深まりますよ。
- モデルごとの必要性を整理しよう「SVMやk-NNは標準化がほぼ必須」「ランダムフォレストは不要」といったように、モデルと前処理の関係を整理していくと、実践で迷わなくなります。
統計の知識は、機械学習を支える土台です。ぜひ仲良くなってくださいね!
セイ・コンサルティング・グループの新人エンジニア研修のメニューへのリンク
投稿者プロフィール

