
AI・数学入門:コサイン類似度はなぜ「単位ベクトルの内積」と同じなのか?
 山崎講師
山崎講師こんにちは。ゆうせいです。
新人エンジニアとしてAIやデータ分析の勉強を始めると、「コサイン類似度(Cosine Similarity)」という言葉を本当によく耳にしますよね。
そして、同時に「コサイン類似度とは、ベクトルを単位ベクトル化(正規化)してから内積をとったもの」という説明もよく聞くはずです。
「...え、なんでその2つが同じなの?」
「そもそも、なんでそんな面倒なことをするの?」
そんな疑問を抱えているあなたのために、今日はこの2つが数学的に全く同じであることを数式でスッキリ証明しちゃいます!
さらに、なぜAIの世界ではベクトルの「大きさ」をあえて無視して「方向」だけを見たいのか、その理由も具体的な例でしっかり解説しますよ。
証明:「コサイン類似度」と「単位ベクトルの内積」が等しい理由
「数学」と聞くと身構えてしまうかもしれませんが、大丈夫。一つ一つ順番に見れば、とってもシンプルです。
まず、比較したい2つのベクトル、 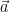
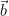
A. コサイン類似度の「定義」を確認しよう
まず、教科書に載っているコサイン類似度 
$
それぞれの記号の意味はこうなっています。
:
:
:
この式は、「2つのベクトルの内積を、それぞれの大きさ(長さ)の積で割る」ことを意味しています。
これがコサイン類似度を計算する「普通の」やり方です。
B. 「単位ベクトル化してから内積」を計算してみよう
次に、あなたが疑問に思っている「ベクトルを単位ベクトル化してから内積を取る」操作を、そのまま数式にしてみましょう。
1. 
まず「単位ベクトル」とは何でしょうか?
これは「大きさが1のベクトル」のことです。向きは元のベクトルと全く同じですが、長さだけが 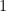
作り方は簡単で、元のベクトル
$
2. 
$
3. 単位ベクトル
準備ができました。この2つの単位ベクトルの内積 
$
この計算では、
内積の計算では、スカラーは自由に分母や分子にまとめることができます。
なので、分母を 
$
結論:2つの式が完全に一致!
さあ、AとBの最終結果を見比べてみてください!
- A(コサイン類似度の公式):
- B(単位ベクトルの内積):
...どうでしょう?
見事に、2つの式が完全に一致しましたね!
これが、「コサイン類似度を計算すること」と「両方のベクトルを単位ベクトル(長さ1)に正規化してから内積を計算すること」が、数学的に全く同じ(等価)である理由です。
スッキリしましたか?
「大きさ」を無視して「方向」だけを見る仕組み
数式で同じになることは分かりました。
では、直感的には、なぜこの操作がベクトルの「大きさ」を無視して「方向」だけを見ることになるのでしょうか?
単位ベクトル化 = 長さを強制的に「1」に揃える
「単位ベクトル化」という操作は、さっきも説明した通り、ベクトルの「方向」は一切変えずに、その「長さ(大きさ)」だけを強制的に
どんなに長いベクトルも、どんなに短いベクトルも、全て「長さ1」のベクトルに作り変えてしまうわけです。
全てのベクトルを、原点(0,0)から半径1の円(3次元なら球)の表面に、ぐいっとマッピングするイメージですね。
長さが「1」だと、内積は「コサイン」そのものになる
ここで、中学校や高校で習った「内積のもう一つの定義(幾何学的な定義)」を思い出してみましょう。
こんな式、見覚えがありませんか?
$
この式は、「2つのベクトルの内積は、2つのベクトルの大きさの積に、間の角度のコサイン
では、もし、 

さっき作った単位ベクトル
$


$
$
すごい!
単位ベクトル同士の内積を計算すると、間の角度のコサイン
ベクトルの「大きさ」という要素が 
これが、「大きさ」を無視して「方向」だけを見ている、という直感的な理由です。
実践:なぜベクトルの「大きさ」を無視したいの?
「方向だけ見るのは分かったけど、なんでわざわざ大きさを捨てるの?情報が減っちゃうじゃん!」
そう思いますよね。
その答えは、「大きさ」がノイズ(邪魔な情報)になってしまうケースが、AIの世界には非常に多いからです。
具体例:単語の「意味」を比べたい時
自然言語処理(NLP)で、単語をベクトルで表現する「単語ベクトル」の例を考えてみましょう。
AIが「王様」「女王」「リンゴ」という単語を、意味を捉えたベクトルとして表現したとします。
(※実際は数百次元ですが、ここでは分かりやすく2次元で考えますね)
(リンゴ) = [1, 5] (「人間/王族」軸が1、「食料」軸が5)
この時点で、「王様」と「女王」は似た方向を、「リンゴ」は全然違う方向を向いているのが分かります。
もし「大きさ」がノイズになったら?
ここで、学習に使ったデータ(教科書)の中で、「王様」という単語だけが、たまたま他の単語より非常〜に頻繁に出現したとします。
その結果、AIが「王様」のベクトルだけ、やたらと大きな値(長いベクトル)で学習してしまいました。
(すごく頻繁な王様) = [16, 4] (
さあ、大変です。
私たちは単語の「意味」が似ているか知りたいのに、「単語の出現頻度」という無関係な情報が、ベクトルの「大きさ」という形でノイズとしてのっかってしまいました。
「大きさ」を無視する(コサイン類似度)と!
ここでコサイン類似度の登場です!
コサイン類似度は、計算の過程で強制的にベクトルを「単位ベクトル(長さ1)」に直してくれます。
この2つのベクトル、大きさは 
コサイン類似度で計算すると、
その結果、こうなります。
(すごく頻繁な王様 vs 王様)→ 方向が全く同じなので、値は
になります。(類似度MAX!)
(すごく頻繁な王様 vs 女王)→ $\vec{d}$ と $\vec{b}$ は非常に近い方向を向いているため、
(すごく頻繁な王様 vs リンゴ)→ $\vec{d}$ と $\vec{c}$ はかなり異なる方向を向いているため、
に近い値(例: 0.3)になります。
これです!
「出現頻度が多いからベクトルが大きくなってしまった」という「大きさ」のノイズを完全に無視して、「王様」と「女王」は意味的に(=方向が)似ている、と正しく判断できました。
まとめと今後の学習指針
今日のポイントをまとめますね。
- コサイン類似度の計算は、数学的に「ベクトルを単位ベクトル化(長さ1に正規化)してから内積を取る」ことと全く同じ(等価)です。
- 単位ベクトル同士の内積は、ベクトルの「大きさ」の影響が
で消え、純粋な「角度(方向)」の情報
- AIやNLPの分野では、「単語の出現頻度」のようなベクトルの「大きさ」に出てくるノイズを無視し、「意味」のような「方向」だけを比べたいことが多いため、コサイン類似度が大活躍するのです。
コサイン類似度は、今日お話しした単語ベクトルの比較だけでなく、推薦システム(あなたと「好み」の方向が似ている人を探す)や、文章の類似度判定など、本当に色々な場所で使われている基本技術です。
もし、あなたがさらにAIと数学の世界を探求したいなら、次は「ユークリッド距離」と「コサイン類似度」の違いについて調べてみるのがオススメです。
「近さ」を測るのになぜ「2点間のまっすぐな距離(ユークリッド距離)」を使わず、わざわざ「角度(コサイン類似度)」を使うのか?
その答えを探求してみると、AIがデータをどのように「見て」いるのか、さらに深く理解できるはずですよ!
一緒に頑張りましょう!
セイ・コンサルティング・グループの新人エンジニア研修のメニューへのリンク
投稿者プロフィール

