
AI学習の心臓部!「連鎖律(Chain Rule)」がわかるとなぜAIが賢くなるかが見える
 山崎講師
山崎講師こんにちは。ゆうせいです。
ディープラーニングの学習、お疲れ様です! 勉強を進めていると、「誤差逆伝播法(バックプロパゲーション)」という言葉と、そのために「微分(びぶん)」が必須、という話に出会ったはずです。
その中でも、今日お話しする「連鎖律(れんさりつ)」、英語で言う「Chain Rule」は、ディープラーニングの学習メカニズムを理解する上で、もう本当に、最重要と言ってもいい概念なんです。
なぜなら、ニューラルネットワークが賢くなるための学習(=誤差逆伝播法)そのものが、この連鎖律というたった一つの数学ルールでできているからです。
「数学」と聞いただけでアレルギーが出そう...という新人エンジニアのあなたでも大丈夫!
連鎖律は一言でいうと「玉ねぎの皮をむくように、関数の”中身”を順番に微分していくルール」のこと。
この記事を読めば、AIが学習する仕組みの「一番おいしいところ」が理解できるはずです。
⚙️ なぜ連鎖律が必要なの?(直感的な理解)
そもそも「微分」とは何だったか、思い出してみましょう。
微分とは、「入力が ちょっと 変わったら、出力が どれくらい 変わるか?」という「変化の割合」を見ることでしたよね。
では、もし「関数の中に関数が入っている」という、マトリョーシカのような入れ子構造になっていたら、どう計算すればよいでしょうか?
ギア(歯車)の比率で例えると、とても分かりやすいですよ。
A、B、Cという3つのギアが連動していると想像してください。
- あなたがAを1回転させると、Bが3回転します
- Bが1回転すると、Cが2回転します
さて、ここで問題です。
「あなたがAを1回転させたら、最終的にCは何回転しますか?」
...簡単ですよね!
Aが1回転するとBが3回転し、そのBが(1回転につき2回転するCを)3回動かすので、Cは 
この「変化の割合を、掛け算でつないでいく」という考え方こそが、連鎖律のキホンです。
これを数学の言葉(微分)で書いてみましょう。
- CのBに対する変化率(Bが1動いたらCが2動く):
- BのAに対する変化率(Aが1動いたらBが3動く):


では、Aに対するCの変化率は?
$
間に「B( 

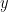
これが連鎖律です!
📝 どうやって計算するの?(簡単な数学)
ギアの例えで「掛け算すればいい」ことは分かりました。
では、実際の関数ではどう計算するのでしょうか?
連鎖律のルールは、こう覚えてください。
① 外側を微分する(中身はそのまま) $\times$ ② 中身を微分する
この「玉ねぎの皮むき」ルールさえ覚えればOKです!
簡単な例題で見てみましょう。
例題: 
この関数
- 外側の関数 (
): 「(なにか)を2乗する」という皮
- 内側の関数 (
): 「(なにか)」の中身
この「外側」と「内側」を、先ほどのルールで順番に微分して、掛け合わせます。
① 外側を微分する(中身はそのまま)
まず「外側」の皮、 

$\rightarrow$

② 中身を微分する
次に「内側」の
$\rightarrow$
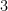
③ 2つを掛け合わせる
最後に、①と②の結果を掛け合わせます。
$
$
$
これで微分完了です!
(検算してみましょう)
ちなみに、 
これを普通に微分しても、 
🧠 なぜこれがAIエンジニアに最重要なのか?
さて、ここからが本題です。
「ギアとか 
「これがどうAIやディープラーニングと関係あるの?」
...めちゃくちゃ関係あるんです!
なぜなら、ニューラルネットワークは、この「関数の入れ子(合成関数)」の、超巨大なカタマリだからです。
ニューラルネットワークの処理の流れを、ものすごーく単純化すると、こんな感じです。
入力(x) $\rightarrow$ [層1 (A)] $\rightarrow$ [層2 (B)] $\rightarrow$ [層3 (C)] $\rightarrow$ 出力(y) $\rightarrow$ [損失関数 (L)]
「損失関数(L)」というのは、AIの「答え(y)」と「本当の正解」を比べて、AIがどれくらい「間違っているか」を計算する関数です。
AIを賢くする(学習させる)とは、「この『間違い (L)』を、できるだけ小さく(0に)したい!」ということです。
そのために私たちが知りたいのは、
「最終的な”間違い” (損失 $L$) を減らすために、例えば、一番最初の『層1の重み ( 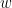
です。
これは、数学の言葉で言えば、
「 $L$ を $w$ で微分する( 
という計算をすることに他なりません。( 
でも、 $L$ と $w$ の間には、層C、層B、層A...と、たくさんの「関数」が挟まっていて、遠すぎます。
「 $w$ をちょっと変えたら、 $L$ がどれだけ変わるか」なんて、直接計算できそうにありません...!
そこで、連鎖律の出番です!
ギアの例えのように、「変化率」を、ゴール(L)からスタート(w)に向かって、掛け算でつないでいけばいいのです。
: 「最終的な間違いL」は「出力y」が変化したらどれだけ変わるか?
: 「出力y」は「層C」が変化したらどれだけ変わるか?
: 「層C」は「層B」が変化したらどれだけ変わるか?
: 「層B」は「層A」が変化したらどれだけ変わるか?
: 「層A」は「重みw」が変化したらどれだけ変わるか?
私たちが知りたい「 $w$ が $L$ に与える影響(
$
この計算を、L (Loss = 誤差) から逆向きに(Backward)、鎖(Chain)をたどるように計算していく。
これこそが、AIの学習アルゴリズムの王様、
「誤差逆伝播法(ごさぎゃくでんぱほう、Backpropagation)」
の正体です。
まとめと次のステップ
いかがでしたでしょうか?
連鎖律が、ただの数学の公式ではなく、AIが学習するための「設計図」そのものであることが、少しイメージできましたか?
- 連鎖律は「合成関数(関数の中に関数)」を微分するルール
- 計算は「①外側を微分 $\times$ ②中身を微分」と覚える
- ニューラルネットワークの学習(誤差逆伝播法)は、この連鎖律を使って「最終的な間違い」に対する「各部品(重み)の責任」を、逆向きに計算するプロセスそのものである
この概念がしっかりわかれば、ディープラーニングの学習の仕組みの半分は理解したと言っても過言ではありません!
連鎖律で「各部品がどっちに動けば間違いが減るか」が分かったら、次に知りたくなるのは「じゃあ、具体的にどうやって重みを更新(最適化)するの?」ですよね。
その答えが「勾配降下法(こうばいこうかほう)」です。
もしよければ、次は「勾配降下法」と、今日学んだ「微分」がどう関係するのかについて解説しましょうか?
セイ・コンサルティング・グループの新人エンジニア研修のメニューへのリンク
投稿者プロフィール

