
【高校生必見】ChatGPTの中身は数学?AI技術「Transformer」を徹底解説!
 山崎講師
山崎講師
こんにちは。ゆうせいです。
みなさん、最近学校やSNSで「生成AI」という言葉を聞かない日はありませんよね。ChatGPTにGemini、Claudeなど、私たちの生活はあっという間に便利なAIたちで溢れかえりました。
「宿題の手伝いをしてもらった」
「暇つぶしの相手になってもらった」
そんな風に、すでに友達感覚で使っている人も多いのではないでしょうか。でも、ここで一つ質問です。みなさんは、その画面の向こう側にいるAIが「どうやって」言葉を紡いでいるのか、説明できますか。
実は、AIは魔法の箱ではありません。その正体は、みなさんが高校で習う「数学」の塊なんです。
今回は、現代のAIを支える革命的な技術「Transformer(トランスフォーマー)」について、数式アレルギーの人でも楽しめるように、とことん噛み砕いて解説していきます。教科書で見るあの退屈な記号たちが、実は世界を変える最先端技術の部品だったなんて、ちょっとワクワクしませんか。
それでは、ブラックボックスの蓋を開ける旅に出かけましょう!
第1章:現代教育におけるブラックボックスの解明と「情報I」の深化
AIを「魔法」のままにしておくのは危険?
2022年以降、生成AIの普及は凄まじいスピードで進みました。まるでSF映画の世界が現実になったかのようです。これを受けて、文部科学省も「学校でどうAIと付き合うか」というガイドラインを発表しています。
しかし、学校やニュースで議論されるのは、こんなことばかりだと思いませんか。
「どうすれば上手な回答がもらえるか(プロンプトの書き方)」
「宿題でズルをさせないためにはどうするか(利用制限)」
もちろん、使い方も大事です。でも、これだけではAIを「ただの便利な魔法の道具」として扱っているのと同じですよね。中身を知らないまま使い続けることには、実は大きなリスクが潜んでいます。
たとえば、AIは平気で嘘をつくことがあります。これを専門用語で「ハルシネーション(幻覚)」と呼びます。もしみなさんが、AIの仕組みを全く知らずに「AI様が言うことなら絶対だ」と信じ込んでいたらどうなるでしょうか。嘘を嘘と見抜けず、間違った情報を世界に拡散してしまうかもしれません。
だからこそ、これからの高校生に必要なのは「AIの使い方」だけではなく、「AIの仕組み」を理解する力なのです。
「情報I」と「数学C」が最強の武器になる
「仕組みなんて難しすぎて無理!」
そう思ったあなた、安心してください。実は、AIの仕組みを理解するための鍵は、すでにみなさんの手元にあります。それは、学校の教科書です。
特に、以下の科目がAI理解の土台となります。
- 情報I: データのデジタル化やアルゴリズムの基礎
- 数学C: ベクトル、行列
- 数学II: 三角関数、指数・対数関数
「ベクトルなんて矢印書いて何の意味があるの?」
「サイン・コサインなんて将来絶対使わないでしょ」
そんな風に思ったことはありませんか。正直に言うと、私も高校生の頃はそう思っていました。でも、驚いてください。ChatGPTのような超高度なAIの裏側では、まさにこの「ベクトル」や「行列」が主役として躍動しているのです。
言葉を「ベクトル(矢印)」に変換し、その意味を「行列」で計算する。
AIにとっての言葉とは、国語の問題ではなく、数学の計算問題なのです。
ブラックボックスを開ける鍵を手に入れよう
この連載記事では、ブラックボックスと化しているAIの中身を、高校生の知識を使って解き明かしていきます。
単なる技術の解説だけではありません。「なぜベクトルを使うのか?」「なぜ確率が重要なのか?」といった疑問を、直感的な「例え話」を使って紐解いていきます。
これを読み終える頃には、数学の授業が「退屈な時間」から「未来を作るためのトレーニング」に見えてくるはずです。そして、データサイエンスという分野への興味が湧き、将来の進路のヒントになるかもしれません。
さあ、準備はいいですか。AIという名の巨人の肩に乗るために、まずはその足元、基礎理論からしっかりと固めていきましょう。
次回は、いよいよAIがどうやって「言葉」を理解しているのか、その驚きの方法に迫ります。「言葉を計算する」とはどういうことなのか、一緒に考えていきましょう!
【高校生必見】AIは言葉がわからない?「意味」を数値化する驚きの方法【第2章】
前回は、AIが実は「数学の塊」であることをお話ししました。
「ChatGPTは魔法じゃない、数学だ」と言われても、まだピンとこない人もいるかもしれません。だって、AIはあんなに流暢に日本語を話しているじゃないですか。
でも、ここで衝撃的な事実をお伝えしなければなりません。
実は、コンピュータは「言葉」の意味をこれっぽっちも理解していません。
彼らが理解できるのは「0」と「1」の羅列、つまり「数値」だけです。では、なぜ彼らは私たちと会話ができるのでしょうか?
今回は、言葉を数値に変える魔法の翻訳機、「ベクトル」のお話です。数学Cで習うあの「矢印」が、ここで主役として登場しますよ!
コンピュータは「計算」しかできない
まず大前提として、コンピュータは超高速な計算機(電卓)です。「こんにちは」という文字を見ても、コンピュータにとってはただの記号の並びでしかありません。
かつてのAI研究者たちは、この問題を力技で解決しようとしました。
「辞書を丸ごと覚えさせて、文法ルールを全部プログラムすればいいじゃないか!」と考えたのです。これを「ルールベース」の手法と呼びます。
しかし、日本語はそんなに単純ではありません。
例えば、「やばい」という言葉。
「このラーメン、やばい(美味しい)」と、「テストの点数がやばい(悪い)」では、意味が正反対ですよね。前後の文脈や若者言葉の流行り廃りまで、すべてのルールを人間が手書きで教え込むのは不可能です。
そこで登場したのが、「大量のデータから勝手にルールを見つけ出させる」という機械学習のアプローチです。そして、その核心にあるのが「言葉を数値(ベクトル)に変換する」という技術です。
言葉の成分表を作ろう
言葉を数値にするって、どういうことでしょうか?
ここで、みなさんに馴染み深い「飲み物」で例えてみましょう。これを「言葉の成分表(フレーバープロファイル)」と呼ぶことにします。
カフェにある飲み物を、言葉ではなく「数値」で区別することを想像してください。
例えば、「甘さ」「炭酸」「カフェイン」「温度」という4つの特徴で点数(0.0〜1.0)をつけてみます。
| 飲み物(単語) | 甘さ | 炭酸 | カフェイン | 温度 |
| コーラ | 0.9 | 1.0 | 0.4 | 0.1 |
| コーヒー | 0.1 | 0.0 | 0.9 | 0.9 |
| 緑茶 | 0.0 | 0.0 | 0.5 | 0.8 |
| レモネード | 0.7 | 0.2 | 0.0 | 0.1 |
こうして表にしてみると、面白いことがわかります。
「コーラ」と「レモネード」は、「甘さ」の数値が高いので似ています。
一方で、「コーラ」と「緑茶」は、どの数値も全然違うので似ていません。
コンピュータは「コーラ」という文字は読めませんが、「 ![[0.9, 1.0, 0.4, 0.1]](https://s0.wp.com/latex.php?latex=%5B0.9%2C+1.0%2C+0.4%2C+0.1%5D&bg=ffffff&fg=000&s=0&c=20201002)
この数字のセットこそが、数学Cで学ぶ「ベクトル」の正体なのです。
AIの世界では、これを「単語埋め込み(Word Embedding)」と呼びます。
実際のChatGPTなどのAIは、この成分(次元)が4つどころではありません。数千、数万という膨大な項目の成分表を使って、言葉の微妙なニュアンスを表現しているのです。
「意味」を足し算・引き算する
言葉をベクトル(数値)に変換する最大のメリットは、なんと「意味の計算」ができるようになることです。
有名な例を紹介しましょう。
「王様」という意味のベクトルから、「男性」という意味を引き、「女性」という意味を足すと、どうなると思いますか?
数式で書くとこうなります。

(王様 


これは単なる言葉遊びではありません。
先ほどの飲み物の表で考えてみてください。「王様」という単語は「権力がある」「男性である」といった成分が高い数値を持っています。そこから「男性である」成分を引き算して、「女性である」成分を足し算すると、残るのは「権力がある」「女性である」という成分を持つ単語……つまり「女王」のベクトルになるのです。
AIは、言葉の意味を辞書の定義としてではなく、「空間上の位置関係」として捉えています。
「王様」と「女王」は近くにいて、「王様」と「一般市民」は遠くにいる。そんな広大な「意味の空間」の中で、AIは計算を行っているのです。
でも、これだけじゃ足りない?
「言葉をベクトルにすれば、AIは完璧に言葉を理解できるんだ!」
そう思ったあなた、実はまだ壁があります。
この方法だと、「銀行(Bank)」という単語が、「お金を預ける場所」なのか、「川の土手」なのか、文脈によって使い分けることができません。単語一つにつき、一つの成分表しか持てないからです。
人間は、前後の文脈を読んで言葉の意味を瞬時に判断しますよね。
その「文脈を読む」という離れ業を実現したのが、次回解説するAIの歴史を変えた技術たちです。
次回は、AIがどうやって文章を「読んで」いたのか、その進化の歴史と、ついに登場する革命児「Transformer」の前夜祭についてお話しします。
「伝言ゲーム」が得意なAIと、苦手なAIのお話です。お楽しみに!
【高校生必見】伝言ゲームはもう限界?AIの歴史を変えた「聖徳太子」革命【第3章】
前回は、言葉を「ベクトルの足し算・引き算」で操る方法について解説しました。「王様 
しかし、単語の意味がわかっただけでは、長い文章を理解することはできません。
「犬が猫を追いかける」と「猫が犬を追いかける」。
使っている単語(ベクトル)は全く同じですが、意味は逆ですよね。言葉の「順番」や「文脈」を理解しないと、正しい日本語にはならないのです。
今回は、2017年にAI界に激震を走らせた革命的な技術「Transformer」が登場する前のお話と、なぜTransformerがすごすぎるのか、そのパラダイムシフトについて解説します。
キーワードは「伝言ゲーム」と「聖徳太子」です。
昔のAIは「伝言ゲーム」をしていた
2017年より前、翻訳などの言語処理で主役だったのは「RNN(再帰型ニューラルネットワーク)」という技術でした。
名前は難しいですが、やっていることは非常にシンプルです。人間が文章を読むときと同じように、「先頭から順番に」単語を処理していたのです。
これをクラスのみんなでやる「伝言ゲーム」に例えてみましょう。
- 生徒が一列に並びます。これがAIの層です。
- 先頭の生徒(最初の単語担当)が、情報を読み取って、隣の生徒に耳打ちします。
- 隣の生徒は、その情報を聞いて、自分の持っている情報を加えて、さらに隣へ耳打ちします。
これがRNNの仕組みです。一見うまくいきそうですよね?
しかし、このやり方には致命的な欠点がありました。
欠点1:話が長くなると忘れてしまう
伝言ゲームをやったことがある人ならわかると思いますが、列が長くなればなるほど、最初の内容は歪んで伝わります。
100人目の生徒に伝わる頃には、「太郎くんはリンゴが好き」という情報が、「誰かがパイナップルを持ってる」くらい変わってしまっているかもしれません。
専門用語ではこれを「勾配消失問題」や「長期依存性の欠如」と呼びます。
文章の最後に出てくる「彼」が、実は冒頭に出てきた「太郎」を指している。人間なら簡単にわかりますが、昔のAIにとって、遠く離れた単語の関係性を理解するのは至難の業だったのです。
欠点2:リレー走は待ち時間が長い
もう一つの弱点は「計算の遅さ」です。
前の人が耳打ちを終えるまで、次の人は何もできませんよね。
どれだけ計算が得意なスーパーコンピュータ(GPU)をたくさん用意しても、結局は「バトンパス」を待たなければなりません。これを「リレー走」に例えると、どんなに足の速いランナーを集めても、バトンが来るまで走れないのと同じです。
「並列処理(みんなで一気に作業すること)」ができない。これが、AIの進化を阻む大きな壁となっていました。
壁をぶち壊した「円卓会議」システム
そこで登場したのが、今回の主役「Transformer」です。
Transformerは、「前から順番に」という常識を完全に捨て去りました。
その解決策は、「伝言ゲーム」をやめて「円卓会議」を開くことでした。
聖徳太子のように全てを同時に聞く
Transformerの画期的な点は、文章中のすべての単語を「一気に」処理することです。
- 一斉処理: 文章中の全単語が、円卓を囲んで同時に座ります。
- 全結合: どの単語も、他のすべての単語と直接会話ができます。
昔のRNNでは、文頭の単語と文末の単語は、物理的に遠く離れていました。しかし、Transformerの円卓会議なら、文頭も文末も「隣の席」に座っているのと同じです。距離なんて関係ありません。
「太郎」という単語は、遠く離れた「彼」という単語と、瞬時に情報を交換できます。
これを日本の歴史上の人物に例えるなら、一度に多くの人の話を聞き分けたとされる「聖徳太子」のようなものです。
GPUの本気を引き出す
さらに、この仕組みはコンピュータにとっても最高に都合が良いのです。
「前の人の処理を待つ」必要がないため、最新のGPUを使って、すべての単語の計算を「せーの!」で同時に実行できます。
これを「並列化」と言います。これにより、AIの学習速度は劇的に向上し、これまでとは比較にならないほど大量のデータを読み込めるようになりました。ChatGPTのような超巨大AIが生まれたのは、この「並列化」のおかげなのです。
まとめ:ルールから自由へ
昔のAI(RNN)は、真面目にコツコツと順番を守る「リレー走」でした。
しかし、新しいAI(Transformer)は、全員で一斉に議論する「円卓会議」へと進化しました。
これにより、
「長い文章でも文脈を忘れない」
「計算速度が爆発的に速い」
という2つの武器を手に入れたのです。
でも、ここで疑問が湧きませんか?
「全員が一斉に喋り出したら、うるさくて何が重要かわからなくなるんじゃない?」
ご名答です。
聖徳太子なら聞き分けられるかもしれませんが、ただの計算機には難しいはずです。
そこで重要になるのが、騒がしい会議の中で「誰の話に耳を傾けるべきか」を自動で判断する仕組み。
それこそが、Transformerの心臓部であり、最強の機能である「Attention(注意)機構」です。
次回、いよいよTransformerの中核技術「Attention」の秘密に迫ります。
「カクテルパーティー効果」や「Google検索」の例えを使って、AIがどうやって重要な情報だけを拾い上げているのか、詳しく解説していきます。
数式も少し出てきますが、怖がらないでくださいね。高校数学の「行列」が、世界を変える瞬間を目撃しましょう!
【高校生必見】AIの心臓部「Attention」を解説!行列計算が思考を作る【第4章】
前回は、AIが「伝言ゲーム(RNN)」を卒業し、全員で一斉に話し合う「円卓会議(Transformer)」に進化したお話をしました。
でも、ここで一つ疑問が残りましたよね。
「クラス全員が一斉に喋り出したら、誰の話を聞けばいいかわからなくなるんじゃない?」
その通りです。聖徳太子ならぬAIにとっても、ただ騒がしいだけでは意味がありません。
そこで登場するのが、Transformerの心臓部とも言える最重要機能、その名も「Self-Attention(自己注意機構)」です。
今回は、このAttention(アテンション)がどのようにして言葉の関係性を紐解いているのか、高校数学Cで学ぶ「行列」を使って解説します。「行列なんて何の役に立つの?」と思っていた人、今日その答えが見つかりますよ!
カクテルパーティー効果とAI
まず、「Attention(注意)」とは何でしょうか?
これを理解するために、「カクテルパーティー効果」という心理学用語を思い出してください。
ガヤガヤと騒がしいパーティー会場でも、自分の名前を呼ばれたり、興味のある話題(推しの話など)が聞こえたりすると、不思議とそこだけ聞き取れることってありませんか? 人間の脳は、無意識のうちに「自分にとって重要な情報」だけに「注意(Attention)」を向け、それ以外の雑音をボリュームダウンさせています。
AIもこれと同じことをやっています。
例えば、「彼は全力でボールをバットで打った」という文章をAIが読むとします。
AIが「打った」という単語を理解しようとする時、ただ辞書にある「打撃」という意味だけでは不十分です。
「誰が?(彼)」「何を?(ボール)」「何で?(バット)」
これらの情報とセットになって初めて、「打った」の本当の意味(文脈)が決まります。
AIは「打った」という単語から、「彼」「ボール」「バット」という単語に対して強いスポットライト(注意)を当て、逆に関係の薄い「は」や「で」といった単語へのライトを弱めているのです。
検索エンジンで理解する「Q、K、V」
では、どうやって「どれが重要か」を計算しているのでしょうか?
ここで登場するのが、3つの謎のベクトル、


- Query(クエリ):
- Key(キー):
- Value(バリュー):
これだけ聞くと難しそうですが、みなさんが毎日使っている「Google検索」や「YouTube検索」に例えると一発でわかります。
1. Query(クエリ) = 「検索ワード」
あなたが知りたいこと、探しているものです。
「打った」という単語は、「ねえ、主語と目的語はどこにあるの?」という質問(クエリ)を投げかけます。
2. Key(キー) = 「タグ・見出し」
検索結果に表示される動画のタイトルやタグです。
文章中の各単語は、自分がどんな役割を持っているかというタグ(キー)を持っています。
「彼」という単語は「僕は主語になれるよ」というタグを、「ボール」は「僕は目的語だよ」というタグを持っています。
3. Value(バリュー) = 「中身」
動画そのもの、つまり情報の中身です。
「彼」という単語が持つ「男性、人間」といった実質的な意味データのことです。
AIが行う「マッチング計算」
AIは、この3つを使って以下のように計算します。
- 検索(
):「打った」の質問(
- 重み付け(Softmax):計算された相性の良さを、パーセント(確率)に直します。「彼」には40%、「ボール」には30%、「バット」には20%、「は」には1%……といった具合です。これを「Attention Weight(注意の重み)」と呼びます。
- 取り込み(
):最後に、そのパーセントの分だけ、相手の中身(
こうして、最初はただの「打った」だったベクトルが、周りの情報を吸収して「彼がバットでボールを打った動作」というリッチな意味を持つベクトルに進化します。これがSelf-Attentionの正体です。
数式で見る「行列」の威力
少しだけ、実際の数式を見てみましょう。教科書に出てくる行列の式にそっくりですよ。

うわっ、と思った人、逃げないでください! よく見るとシンプルです。
: クエリ行列とキー行列の掛け算です。これ一発で、文章中のすべての単語同士の相性診断を同時に行っています。ここが行列計算のすごいところです。
: 相性スコアを0〜1の確率(合計100%)に変換しています。
- 最後の
高校数学Cで「行列の積」を習うとき、「こんな計算いつ使うんだよ」と思うかもしれません。でも、この計算こそが、ChatGPTがあなたの質問を理解するための思考プロセスそのものなのです。
一人じゃ不安?なら「チーム」で考えよう
人間が文章を読むとき、一度にいろいろなことを考えますよね。
「誰がしたことか(文法)」
「ポジティブな話かネガティブな話か(感情)」
「『それ』は何を指しているか(文脈)」
たった一つのAttention(視点)だけで、これら全てを捉えるのは無理があります。
そこでTransformerは、このAttentionを複数同時に走らせます。これを「Multi-Head Attention(マルチヘッド・アテンション)」と呼びます。
イメージは「専門家チームの会議」です。
- ヘッド1(文法係): 「誰が」「何を」の関係だけを必死に探します。
- ヘッド2(感情係): 「楽しい」「悲しい」といった感情語だけに注目します。
- ヘッド3(文脈係): 代名詞のつながりを追跡します。
それぞれのヘッド(頭)が別の視点で分析を行い、最後にリーダーが全員の意見をまとめて(結合して)、結論を出します。
「三人寄れば文殊の知恵」と言いますが、AIは何十、何百という「頭」を使って、文章を多角的に深く理解しているのです。
まとめと次回の予告
いかがでしたか。
AIは「検索(Query)」と「タグ(Key)」のマッチング(内積)を行い、重要な情報だけを「中身(Value)」から吸い上げている。そして、それを複数の視点(Multi-Head)で行っている。
これが、AIが言葉を理解する核心部分です。
行列やベクトルが、ただの数字遊びではなく、言葉の意味をつなぐ架け橋になっていることに感動しませんか?
さて、これで「言葉の意味」と「関係性」はバッチリ理解できました。
しかし、円卓会議方式(並列処理)にしたことで、実は一つだけ重大な情報が失われてしまっているんです。
それは「言葉の順番」です。
「犬が猫を追う」と「猫が犬を追う」。
Transformerにとっては、このままではどちらも同じ意味になってしまいます。
次回、この問題を解決するために、なんと高校数学IIの「サイン・コサイン(三角関数)」が登場します。
波のグラフが言葉の順番を表す? まさかそんなことが……あるんです。
次回も、数学の美しさに触れる旅を続けましょう!
【高校生必見】「サイン・コサイン」が言葉の順番を決める?AIと三角関数の意外な関係【第5章】
ここまで、AIが「円卓会議」で一気に文章を理解する仕組み(Transformer)について解説してきました。
しかし、この「一気にやる」という素晴らしい方法には、たった一つだけ、致命的な副作用があります。
それは……「言葉の順番がわからなくなる」ことです。
今回は、この問題を解決するために、みなさんが数学IIで習う「三角関数(サイン・コサイン)」がまさかの登場を果たします。
「波のグラフなんて、物理以外でいつ使うの?」
そう思っていたあなた。実は、AIが正しい文章を話せるのは、あの波のおかげなんです。
「円卓会議」の落とし穴
Transformerの最大の特徴は、文章の最初から最後までを同時に処理する「並列処理」でした。
しかし、これには困った問題があります。
例えば、以下の2つの文を見てください。
A:「犬 が 猫 を 追う」
B:「猫 が 犬 を 追う」
使われている単語(ベクトル)は、「犬」「猫」「追う」「が」「を」で、全く同じセットですよね。
これを袋の中に全部放り込んでガシャガシャと混ぜてから広げたとしたらどうでしょう? どっちが「追う側」で、どっちが「追われる側」か、区別がつかなくなってしまいます。
前の章で紹介した「Attention」は、単語同士の「関連度」は見抜けますが、「どっちが先に書かれていたか」という情報は持っていないのです。このままだと、AIは「犬」と「猫」の関係を逆に理解してしまうかもしれません。
言葉に「住所」を書き込もう
そこで研究者たちは考えました。
「単語の意味ベクトルに、『君は何番目にいるよ』という位置情報を足してあげればいいじゃないか!」
これを「Positional Encoding(位置エンコーディング)」と呼びます。
例えば、「犬」という単語のベクトルに、「1番目」という情報を足す。
「猫」という単語のベクトルに、「3番目」という情報を足す。
そうすれば、AIは「ああ、この『犬』は文の最初にいるやつだな」と理解できます。
なぜ「1, 2, 3...」じゃダメなの?
ここで鋭い高校生ならこう思うはずです。
「単純に、1番目の単語には 

しかし、それはNGです。
もし文章が1万文字あったらどうなるでしょうか? 最後のほうの単語には 
AIが扱う「意味ベクトル」の数値は、だいたい0から1くらいの小さな世界です。そこにいきなり「10000」なんて巨大な数字を足したら、元の「意味」がかき消されてしまいます。「犬」の意味が消えて、ただの「10000番目の何か」になってしまうのです。
ここで登場! サイン・コサインの「波」
「数字を大きくしすぎずに、無限に続く順番を表現したい……」
そんな無理難題を解決する魔法の道具。それこそが「周期関数」、つまり「サイン( 
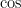
アナロジー:たくさんの「時計の針」
三角関数を使った位置情報の付け方は、「時計」をイメージすると完璧に理解できます。
今が「何時何分何秒」かを知りたいとき、私たちは3本の針を見ますよね。
- 秒針(高周波): 素早くグルグル回る。細かい時間を表す。
- 分針・時針(低周波): ゆっくり回る。大まかな時間を表す。
もし「秒針」しかなかったら、「1周回った後の15秒」なのか「2周回った後の15秒」なのか区別がつきません。
でも、「時針」や「分針」と組み合わせることで、「3時15分15秒」という世界に一つだけの時刻(ユニークな位置)を特定できます。
AIもこれと同じことをやっています。
Transformerは、いろいろなスピード(周期)で振動する「サイン波」と「コサイン波」をたくさん用意します。
- ある波は、素早くプラスとマイナスを行き来する。
- ある波は、ゆったりと変化する。
この「波の組み合わせ」を単語に足し合わせることで、それぞれの単語に「固有の指紋(タイムスタンプ)」を刻み込むのです。
数式で見る「美しさ」
実際に使われている数式はこんな感じです。教科書で見た形に似ていませんか?


難しそうに見えますが、大事なのは
波のグラフはずっと 

これによって、AIは元の単語の「意味」を壊すことなく、「順番」の情報だけを綺麗に上乗せすることができるのです。
数学IIが「言葉」に命を吹き込む
もしサイン・コサインがなかったら、AIは「今日はいい天気」と「天気はいい今日」の区別がつかず、支離滅裂な文章を生成していたでしょう。
無機質な波のグラフが、実は「言葉の順序」という、文章にとって最も大切なリズムを生み出していたのです。
楽譜において「音符(単語)」と「小節(位置)」が揃って初めて音楽になるように、Transformerは「意味」と「位置」をセットにすることで、初めて流暢な言葉を紡ぎ出せるようになりました。
数学の授業で「周期」や「波」を習うとき、ぜひ思い出してください。
「この波が、僕のスマホの中にいるAIの『文脈』を作っているんだな」と。
さて、ここまででTransformerの「中身」の解説はほぼ完了です!
次回は、いよいよこれらを組み合わせた全体像のお話です。
実は、現在のAI(ChatGPTなど)は、Transformerの「ある半分」だけを使って作られているって知っていましたか?
「読む専門」と「書く専門」に分かれたAIの進化系統樹について解説します。お楽しみに!
【高校生必見】ChatGPTは「半分」だけ?AIモデルの進化と「創発」の謎【第6章】
これまで、ベクトル、行列、確率、そして三角関数と、AIを動かす数学の部品たちを一つずつ見てきました。
まるでプラモデルのパーツを並べてきたような気分ですね。
今回、いよいよそれらのパーツを合体させて、巨大ロボット……もとい、「Transformer」の全体像を完成させます。
でも、ここで驚きの事実をお伝えしなければなりません。
みなさんが普段使っているChatGPTなどの生成AIは、実はオリジナルのTransformerの「半分」しか使っていないことがほとんどなんです。
「えっ、手抜きなの?」
いいえ、違います。あえて「半分」に特化することで、とんでもない能力を手に入れたのです。
今回は、AIの進化の歴史と、今のAIがなぜこれほど賢くなったのか、その「進化系統樹」を紐解いていきます。
元祖Transformerは「2人組」だった
2017年に発表された最初のTransformerは、主に「翻訳(英語→ドイツ語など)」をするために作られました。
翻訳という作業を想像してみてください。
- まず、英文を読んで意味をしっかり理解する(インプット)。
- 次に、それをもとにドイツ語を書き出す(アウトプット)。
この役割分担をするために、Transformerは「Encoder(エンコーダ)」と「Decoder(デコーダ)」という2つのパートで構成されていました。
Encoder(読み手):カンニングOKな優等生
Encoderの仕事は、入力された文章を読んで、その意味を完全に理解することです。
彼は「円卓会議(Self-Attention)」を使って、文章の最初から最後までを自由に見渡せます。「未来の単語」も「過去の単語」も全部見ながら(カンニングしながら)、言葉の関係性を分析し、完璧な「意味の設計図」を作ります。
Decoder(書き手):未来が見えない小説家
Decoderの仕事は、その設計図を受け取って、翻訳先の言葉を一単語ずつ生成することです。
彼には厳しいルールがあります。それは「カンニング禁止」です。
文章を書いている最中に、まだ書いていない「未来の単語」を見ることはできません。これまで書いた単語だけを見て、「次に来る単語は何か?」を必死に予測して出力します。
AIの進化系統樹:君はどのタイプ?
この「2人組」から始まったTransformerですが、その後、用途に合わせて改造され、大きく3つのタイプに進化しました。
1. 読み込み特化:Encoder-Only(例:BERT)
「書く機能はいらないから、とにかく文章を深く理解したい!」というニーズから生まれました。
Decoderを切り捨てて、Encoderだけを鍛えたモデルです。
- 得意技: 読解問題、感情分析(ポジティブかネガティブか)、重要単語の抽出。
- イメージ: 黙って本を読み込み、テストの穴埋め問題で満点を取る「ガリ勉タイプの優等生」。
2. 生成特化:Decoder-Only(例:GPT-4, Claude, Llama)
「読むことより、とにかく流暢に喋らせたい!」というニーズから生まれました。
今の生成AIブームの主役です。Encoderの機能を一部取り込みつつ、基本的にはDecoderの構造(次を予測する仕組み)だけで動いています。
- 得意技: おしゃべり、小説の執筆、プログラミングコードの生成。
- イメージ: 即興で物語を無限に語り続けられる「天才ストーリーテラー」。
3. バランス型:Encoder-Decoder(例:T5, 翻訳AI)
元祖のスタイルを受け継いだ正統派です。
- 得意技: 翻訳、文章の要約。
- イメージ: 相手の話を最後まで聞いてから、別の言葉で丁寧に伝える「プロの通訳者」。
なぜ今のAIは「Decoder-Only」が最強なのか?
ここで不思議に思いませんか?
「読む専門のEncoderがあったほうが、賢いんじゃないの? なんでChatGPTはDecoder(書く専門)ベースなの?」
ここがAI研究の最も面白いところです。
実は、Decoderにひたすら「次の単語を予測する」という特訓(しりとりみたいなもの)をさせ続け、勉強させるデータ量を爆発的に増やしていった結果、奇跡が起きました。
「次に来る言葉を正確に当てるためには、文脈を完璧に理解し、論理的に推論し、時には常識も知っていなければならない」
AIは、単語当てクイズに正解したい一心で、勝手に「論理的思考力」や「翻訳能力」、さらには「プログラミング能力」まで身につけてしまったのです。
これを専門用語で「創発(Emergence)」と呼びます。
意図して教えたわけではないのに、量質転化によって突然賢くなる。これが、Decoder-Onlyモデル(GPTシリーズなど)が世界を席巻している理由です。
まとめ:予測マシンの進化
今のAIは、基本的には「超高性能な次単語予測マシン」です。
しかし、その予測の精度があまりにも高すぎて、まるで人間のように思考しているように見える(あるいは、実際に思考のようなプロセスが生まれている)のです。
「たかが予測、されど予測」。
高校生のみなさんが日々勉強していることも、いつか量が質に変わり、思いもよらない能力として「創発」する日が来るかもしれませんよ。
さて、仕組みの話はこれで完璧です!
次回からは、この技術が実際の社会でどう使われているのか、もっと身近な例を見ていきましょう。
実は、あの中毒性のある「TikTok」や「YouTube」のオススメ機能も、このTransformerの親戚だって知っていましたか?
次回は、AIがあなたの「好み」を心を読んでいるかのように当ててくる、そのカラクリに迫ります。お楽しみに!
【高校生必見】TikTok中毒もAIのせい?オススメ機能と「嘘」の秘密【第7章】
前回は、今のAIが「次の単語を予測する」という特訓の末に、人間のような賢さを手に入れたお話をしました。
「へえ、すごいね。でも文章を書くAIなんて、宿題以外で使わないし関係ないかな」
もしそう思っているなら、大間違いです。
実は、みなさんが毎日何時間も夢中になっているTikTokやYouTube、Instagram。あの「やめられない止まらない」中毒性の裏側でも、全く同じ技術が動いているんです。
今回は、身近なアプリに使われているAIの秘密と、AIがたまにつく「もっともらしい嘘」についてお話しします。これを知れば、スマホを見る目が少し変わるかもしれませんよ。
あなたの行動は「文章」である
TikTokやYouTubeショートを見ているとき、みなさんは次々と動画をスワイプしますよね。
「動画Aを最後まで見た」
「動画Bは一瞬でスキップした」
「動画Cにはいいねを押した」
この一連の行動、AIにとっては「文章」と同じなんです。
動画A という単語の次は 動画B、その次は 動画C……。
AIは、あなたの視聴履歴を一つの長い文章(シーケンス)として読み込みます。
そして、前回解説した「Transformer」の出番です。
文章生成AIが「次に来る単語」を予測するのと同じように、レコメンドAIは「次に見せたら絶対に見る動画(Value)」を予測しているのです。
AIはあなたの「無意識」を見抜いている
ここで威力を発揮するのが、あの「Attention(注意)機構」です。
AIは、あなたが過去に見た動画(Key)と、今の気分や直前の行動(Query)を照らし合わせます。
「この人は、普段はゲーム実況(Key)が好きだけど、今は深夜だから癒やし系の猫動画(Key)に長く滞在しているな」
AIは、あなたが自分でも気づいていないような興味の移り変わりを、数学的な「相性計算」によって瞬時に見抜きます。
そして、数億本ある動画の中から、「今のあなた」が見る確率が最も高い一本を差し出してくるのです。
TikTokを見始めたら止まらなくなるのは、あなたの意志が弱いからではありません。
世界最高峰の数学モデルが、あなたの脳内をハッキングして、一番欲しいものを目の前に置き続けているからです。
仕組みを知ると、ちょっと怖いくらいですよね。これからは「AIに操られている」のではなく、「AIが必死に計算して私を楽しませようとしている」と、一歩引いて見てみましょう。
AIは平気で嘘をつく?「ハルシネーション」の正体
さて、話は変わって、ChatGPTなどの生成AIを使うときの注意点です。
みなさんは、AIに質問して、自信満々に嘘をつかれたことはありませんか?
例えば、「架空の歴史上の人物」について質問すると、さも実在するかのような経歴をペラペラと語り出すことがあります。
これを専門用語で「ハルシネーション(幻覚)」と呼びます。
なぜ、こんなことが起きるのでしょうか?
それは、AIが「検索エンジン(Google)」ではなく、「確率マシン」だからです。
「確率の罠」にハマるAI
AIは、事実を知っているわけではありません。
「日本の首都は」と言われたら、学習データの中でその後に続く確率が一番高い「東京」という単語を出しているだけです。
では、学習データに正解がない「知らないこと」を聞かれたらどうなるでしょうか。
AIは「わかりません」と言う代わりに、文脈的に「繋がりそうな単語」を確率だけでつなぎ合わせます。
「〇〇という将軍は」 
単語のつながりとしては自然(確率は高い)ですが、内容は大嘘です。
AIにとっては「事実かどうか」よりも「文章として自然かどうか」のほうが優先順位が高いのです。
これを人間に例えるなら、「答えを知らないのに、口が達者だからそれっぽいことを言ってその場を乗り切ろうとする人」みたいなものです。
悪気はないのですが、自信満々に言うのでたちが悪いですよね。
AIを「神様」にするな
文部科学省が「AIの仕組みを知ろう」と言っている最大の理由は、ここにあります。
中身が「確率計算」だと知っていれば、「AIが言ってるから絶対正しい!」なんて盲信することはなくなりますよね。
「こいつは物知りだけど、たまに知ったかぶりをするから、裏取り(ファクトチェック)は必須だな」
それくらいの距離感で付き合うのが、AIネイティブ世代の賢い態度です。
まとめ
今回は、身近な動画アプリの裏側と、AIの嘘のメカニズムについて解説しました。
- レコメンド機能は、行動を「文章」に見立てて、次の「欲しいもの」を予測している。
- ハルシネーションは、AIが事実よりも「確率的なつながり」を優先するために起こる。
さて、いよいよ次回は最終回です。
これまで学んできた知識は、みなさんの将来にどう役立つのでしょうか?
「データサイエンス学部」という選択肢や、2025年以降の社会で求められるスキルについて、これからのキャリアの話をします。
数学や情報の授業が、実は最強の「武器」になる。そんな希望の話で締めくくりたいと思います。お楽しみに!
【高校生必見】数学が「最強の武器」になる?データサイエンスと未来の進路【最終章】
これまで7回にわたり、AIの裏側にある「ベクトル」「行列」「確率」「三角関数」について解説してきました。
最初は「ただの記号」に見えていた数式たちが、今では少し違って見えませんか。それらは、世界を変える巨大ロボット「AI」を動かすための、一つ一つの重要な歯車だったのです。
さて、最終回となる今回は、これまで学んだ知識を、みなさんの「未来」にどう繋げるかというお話です。
「AIの仕組みはわかったけど、それが進路に関係あるの?」
大いにあります。実は今、みなさんが学校で学んでいる「数学C」や「情報I」が、大学入試や就職活動において、英語や国語と同じくらい、いやそれ以上に強力な武器になりつつあるのです。
ブラックボックスを開けたその先にある、ワクワクする未来の地図を一緒に広げてみましょう。
「データサイエンス学部」の爆発的増加
みなさんは、「データサイエンス学部」という言葉を聞いたことがありますか。
数年前までは珍しい存在でしたが、2025年現在、日本中の大学で新設ラッシュが起きています。滋賀大学が日本で初めてデータサイエンス学部を作ったのを皮切りに、武蔵野大学、関西大学など、多くの大学がこの分野に力を入れています。
では、そこで何を学ぶのでしょうか。
カリキュラムを見て驚かないでくださいね。
- 線形代数(ベクトル・行列)
- 確率・統計
- プログラミング(Pythonなど)
そうです。この連載記事で解説してきたことそのものです。
Transformerを理解するために学んだ「言葉をベクトルにする」「確率で予測する」という考え方は、データサイエンスの基礎中の基礎なのです。
もし、みなさんがこれまでの話を読んで「ちょっと面白いかも」「意外とわかるかも」と思えたなら、あなたにはデータサイエンスの才能があります。文系だから、理系だからという区分けはもう関係ありません。AIは「言葉(文系)」を「数学(理系)」で解く学問ですから、両方の視点が必要なのです。
2025年以降に求められる「AIスキル」とは
では、高校生の今、具体的に何をすればいいのでしょうか。単にChatGPTとおしゃべりするだけでは不十分です。一歩先を行くためのアクションプランを提案します。
1. Python(パイソン)に触れてみる
AI開発の共通言語と言えば、プログラミング言語の「Python」です。
「難しそう」と構える必要はありません。今は「Google Colab」という無料のサービスを使えば、高校生のノートパソコンやタブレットからでも、世界最先端のAIモデルを動かすことができます。
教科書通りのプログラムを書くだけでなく、「Hugging Face」というサイトからTransformerのモデルを借りてきて、自分で動かしてみる。それができた瞬間、あなたはただのユーザーから「クリエイター」へと進化します。
2. 「探究学習」でAIを研究する
学校の「総合的な探究の時間」で、何をしようか迷っていませんか。
ぜひ、AIをテーマにしてみてください。
ただし、「AIを使って調べました」ではなく、「AIそのもの」を研究対象にするのです。
たとえば、「校則をAIに読み込ませて、矛盾点を分析させる」とか、「古文をAIに翻訳させて、プロの現代語訳と比較する」といったテーマはどうでしょう。
高校生科学技術チャレンジ(JSEC)などのコンテストでも、AIを活用した研究は高く評価されています。仕組みを知っているあなたなら、表面的な使い方ではなく、AIの特性(ハルシネーションやバイアス)を踏まえた、鋭い考察ができるはずです。
3. 「倫理観」という最強の盾を持つ
第7章でお話しした通り、AIは平気で嘘をつきますし、使い方次第では誰かを傷つける道具にもなります。
技術的なスキル以上に大切なのが、「AIに何をさせるべきか」「その結果に責任を持てるか」という倫理的な判断力です。
「AIが言ったから」と言い訳をする大人はカッコ悪いです。「AIはこう計算したけれど、最終的な判断は人間である私がする」と言える大人になってください。
結論:AIネイティブ世代の責任と希望
長い旅の終わりに、一つだけ伝えておきたいことがあります。
Transformerという技術は、人類が初めて手にした「言葉の意味を計算可能な形にする」魔法のツールです。
みなさんは、この魔法が当たり前に存在する世界で大人になります。
もし、中身を知らないままでいれば、AIは「得体の知れない怖いもの」や「自分を操ってくる魔法の箱」になるでしょう。
しかし、その中身が 
明日からの数学の授業で、黒板に書かれる 

それは、ただの試験勉強のための記号ではありません。
未来のAIを作り、社会を動かし、世界をより良くするための「未来のパーツ」そのものです。
「なんだ、数学って世界の役に立ってるじゃん」
そう感じて、教科書を開く手が少しでも軽くなれば、私のゴーストライターとしての仕事は成功です。
数学と言葉の力を信じて、新しい時代を切り拓いていってください。
それでは、またどこかの記事でお会いしましょう!
読んでくれてありがとうございました。
読了後の次のステップ
記事の内容を実際の行動に移してみませんか?
- 「情報I」の教科書を見返す: 第2章の「データの活用」や「アルゴリズム」のページをめくってみてください。Transformerの基礎がそこにあります。
- Google Colabを検索する: 無料でPythonを書き始められます。「Python Hello World」から始めてみましょう。
- 大学のシラバスを見る: 気になる大学の「データサイエンス学部」のホームページを見て、どんな授業があるかチェックしてみてください。
あなたの知的好奇心が、未来を作る原動力になりますように。
セイ・コンサルティング・グループの新人エンジニア研修のメニューへのリンク
投稿者プロフィール


