
【SVD入門】複雑なデータを3つの「部品」に分解せよ!特異値分解の仕組みとメリットを解説
 山崎講師
山崎講師こんにちは。ゆうせいです。
みなさんは、子供の頃にラジオや時計を「分解」して遊んだことはありますか。
複雑に見える機械も、バラバラにしてみると「歯車」や「バネ」といったシンプルな部品の組み合わせでできていることがわかりますよね。部品ごとの役割が見えれば、その機械の仕組みがスッキリ理解できます。
実は、データ分析の世界でもこれと同じことができます。
巨大で複雑な表データ(行列)を、性質の異なる3つのシンプルな行列に分解してしまう。そんな魔法のような手法が、今日解説する 特異値分解 (Singular Value Decomposition、略してSVD)です。
「名前がいかつくて難しそう」と身構えないでください。
このSVDこそ、画像の圧縮からNetflixのような「おすすめ映画」の提案機能まで、現代のITサービスを裏側で支えている超重要テクニックなのです。
今日は、数式の細かい証明は脇に置いて、この技術が「何をどう分解しているのか」、そして「分解すると何が嬉しいのか」を、新人エンジニアのみなさんに直感的に伝わるようお話しします。
特異値分解ってなに
特異値分解(SVD)とは、「ある行列を、3つの特別な行列の掛け算の形に書き直すこと」 です。
数学の授業で習った「素因数分解」を思い出してください。
数字の「12」は 
ある行列 

急に記号が出てきましたが、安心してください。それぞれの役割を高校生でもわかるように翻訳します。
この式は、データを変換するプロセスを3つのステップに分けていると考えてください。
(回転): データをくるっと回転させる。
(伸縮): 軸に沿ってビヨーンと伸ばしたり縮めたりする。
(回転): もう一度、別の方向にくるっと回転させる。
つまり、どんなに複雑な行列による変換も、実は「回転して、伸ばして、また回転する」という単純な操作の組み合わせに過ぎない、と主張しているのがSVDなのです。
なぜ分解すると嬉しいのか
「分解できるのはわかったけど、それで?」と思いますよね。
SVDの最大のメリットは、真ん中の
この
ここが重要です。SVDには「特異値が大きい順(情報の重要度が高い順)に並べる」というルールがあります。
つまり、
メリット1:データの圧縮ができる
もし、特異値が極端に小さい部分があったらどうでしょうか。
「重要度が低いなら、捨ててしまってもバレないのでは?」と思いますよね。その通りです。
重要度の低い特異値をゼロにしてから、元の行列
これが、画像圧縮などの原理です。細かいノイズのような情報を捨てて、本質的な特徴だけを残すことができるのです。
メリット2:隠れた特徴が見つかる
例えば、AmazonのようなECサイトで「ユーザー」と「購入履歴」の巨大な行列があったとします。
これをSVDで分解すると、
「このユーザーはSF映画が好きそうだから、これを勧めよう」というレコメンドシステム(推薦システム)は、この考え方を応用して作られていることが多いのです。
練習問題:SVDでデータを「復元」&「圧縮」せよ
ある 

分解された3つの部品
- 左特異ベクトル
(今回は計算を簡単にするため、何もしない単位行列にしています)
- 特異値行列
(ここに注目!特異値は「4」と「1」です)
- 右特異ベクトル
※本来はもっと複雑な数字が入りますが、今回は「特異値の役割」に集中するために極限まで単純化しています。
問題1:元のデータを復元せよ
このバラバラになった3つの行列
行列の掛け算を行って、元の行列
計算式:

問題2:データを圧縮(近似)せよ
次に、SVDの醍醐味である「圧縮」を行います。
特異値行列
その状態で、もう一度3つの行列を掛け合わせ、圧縮された行列 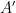
そして、問題1で求めた元の行列
解答と解説
計算お疲れさまでした。
「え、これだけでいいの?」と拍子抜けしたかもしれません。でも、この単純な計算の中にSVDのエッセンスが詰まっています。
解答1:完全な復元
まずは、そのまま掛け算をして元に戻します。

単位行列(1と0だけの行列)は何を掛けても相手を変えないので、結局真ん中の
答え:

これが元のデータです。左上の成分が「4」、右下の成分が「1」という情報を持っていたことがわかります。
解答2:次元削減(圧縮)による近似
ここからが本番です。
特異値は「4」と「1」でした。SVDのルールでは「大きい方が重要」なので、「4」が重要な情報、「1」は細かいノイズやあまり重要でない情報とみなせます。
そこで、思い切って 「1」を「0」にして捨ててしまいます。
新しい 

これを使って再計算します。

答え:

結果の比較
元の行列
- 元データ:
- 圧縮データ:

一番大きな数字である「4」は完全に保たれていますね!
一方で、小さい数字の「1」は失われました。
しかし、行列全体の雰囲気(データの傾向)としては、「左上が大きくて右下は小さい」という特徴は維持されています。
もしこれが画像データなら、「画質は少し粗くなったけど、何が写っているかはハッキリわかる」という状態です。
データ量を半分(特異値を2個から1個に減らした)にしても、一番重要な「4」という情報は守られた。これがSVDによる圧縮の威力です。
計算のまとめ
今回の練習で、以下の2点が直感的に理解できたのではないでしょうか。
- 分解したものを掛ければ、元に戻る(可逆性)。
- 小さい特異値を捨てても、データの「骨格」は残る(近似)。
実際の現場で扱うデータは、数千・数万の行と列を持つ巨大な行列です。
それでもやっていることは同じです。「小さな特異値をバッサリ切り捨てて、計算を軽くしたりノイズを除去したりする」。この感覚を持っていれば、SVDを恐れることはありません。
デメリットと注意点
万能に見えるSVDにも、弱点はあります。
計算コストが高い
行列のサイズが大きくなると、分解にかかる計算時間が膨大になります。何百万ものユーザーがいるような超巨大データに対して、毎回真面目にSVDを計算していると、サーバーが悲鳴を上げてしまいます。そのため、実務では近似的な計算手法を使うことが一般的です。
中身の解釈が難しい
分解して出てきた「特徴」が、人間にとって意味のあるものとは限りません。
「特異値の1番目は『アクション映画好き』を表しているな」とわかることもあれば、「何だかよくわからないけど、数学的には重要な特徴」という場合もあります。AI特有のブラックボックス感に似ていますね。
今後の学習の指針
いかがでしたでしょうか。
特異値分解(SVD)は、単なる数式のパズルではありません。
「データの中に埋もれている『重要な本質』と『どうでもいいゴミ』を綺麗に分けるためのフィルター」 だと思ってください。
この概念を理解しておくと、機械学習で「次元削減(PCAなど)」や「自然言語処理(LSIなど)」を学ぶときに、「あ、これはSVDの親戚だな!」とすぐにピンと来るようになります。
次はぜひ、Pythonを使って実際に画像をSVDで圧縮してみる実験をしてみてください。
「NumPy」というライブラリを使えば、 numpy.linalg.svd というコマンド一発で分解できてしまいます。
自分の手元の写真が、少ない成分だけで見事に再現される様子を見ると、きっと感動しますよ。
データの「成分」を見抜く目を持って、エンジニアとしてのレベルを一段上げていきましょう。
セイ・コンサルティング・グループでは新人エンジニア研修のアシスタント講師を募集しています。
投稿者プロフィール
- 代表取締役
-
セイ・コンサルティング・グループ株式会社代表取締役。
岐阜県出身。
2000年創業、2004年会社設立。
IT企業向け人材育成研修歴業界歴20年以上。
すべての無駄を省いた費用対効果の高い「筋肉質」な研修を提供します!
この記事に間違い等ありましたらぜひお知らせください。
学生時代は趣味と実益を兼ねてリゾートバイトにいそしむ。長野県白馬村に始まり、志賀高原でのスキーインストラクター、沖縄石垣島、北海道トマム。高じてオーストラリアのゴールドコーストでツアーガイドなど。現在は野菜作りにはまっている。
最新の投稿
 新人エンジニア研修講師2026年6月19日Spring BootでセッションIDがアドレスバーに表示される理由と対策|新人エンジニア向けにJSESSIONIDを解説
新人エンジニア研修講師2026年6月19日Spring BootでセッションIDがアドレスバーに表示される理由と対策|新人エンジニア向けにJSESSIONIDを解説- 新人エンジニア研修講師2026年6月18日JavaのOptionalでnullを安全に扱う方法|NullPointerExceptionを防ぎ、DAOの戻り値をわかりやすくする
- 新人エンジニア研修講師2026年6月18日ローカルSMTPを使って問い合わせ完了メールを送る方法|新人エンジニア研修向けにSpring BootとJavaMailSenderを解説
- 新人エンジニア研修講師2026年6月18日DevToolsでHTTP通信・エラー・DOMを確認する方法|新人エンジニア向けにブラウザ開発者ツールを解説
