【SSD vs YOLO】物体検出のライバル対決!違いと使い分けを徹底解説
 山崎講師
山崎講師こんにちは。ゆうせいです。
みなさんは、スマートフォンのカメラを向けただけで、そこに写っているのが「犬」なのか「猫」なのか、瞬時に四角い枠で囲んで教えてくれる機能を使ったことがありますか?
あれは物体検出という技術なのですが、実はその裏側ですごい速さで計算している賢いモデルが存在します。今回紹介するのは、その名もSSDです。ソリッドステートドライブ(記憶媒体)のことではありませんよ。AIの世界でSSDといえば、Single Shot MultiBox Detectorのことなんです。
新人エンジニアのみなさんが、画像認識の世界に足を踏み入れるときに必ず出会うこの技術。今日はその仕組みを、数式だらけの教科書よりもわかりやすく、でも現場で使える知識としてしっかり解説していきます。
さあ、一緒にAIの目の仕組みをのぞいてみましょう!
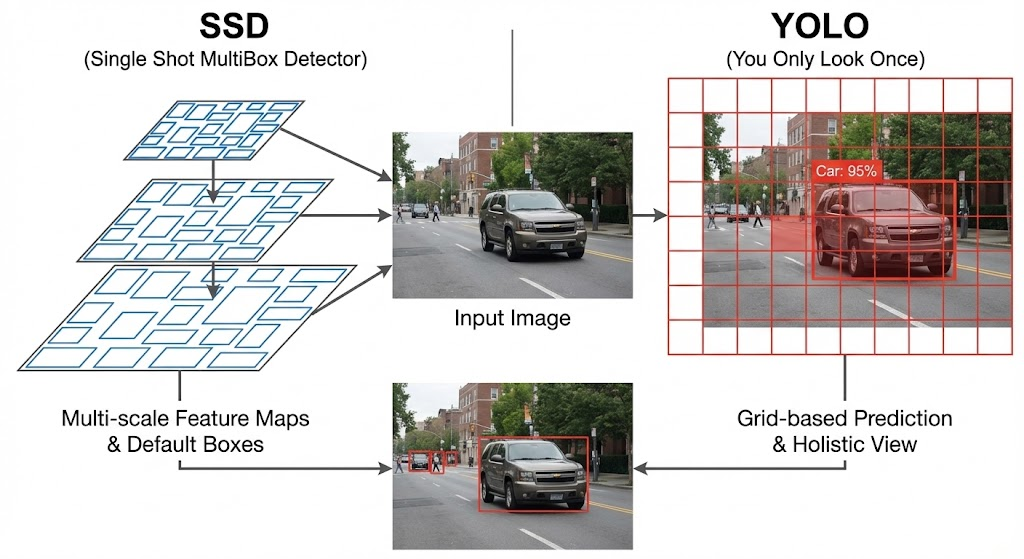
SSDってそもそも何?名前から読み解く正体
SSDは、画像の中に「何が」「どこに」あるかを高速に見つけ出すためのアルゴリズムです。2016年に発表されて以来、その速さと精度のバランスの良さから、多くの現場で愛用されてきました。
この長い名前、Single Shot MultiBox Detectorを分解すると、その特徴が手に取るようにわかります。
Single Shot(一発で!)
ここが最大の特徴です。画像を一回見るだけで(一回の処理で)、物体の位置と種類を特定します。昔の技術は、まず「物体がありそうな場所」を探して、そのあと「それが何か」を判断するという2段階の手順を踏んでいました。人間で例えるなら、部屋の中にある探し物を見つけるときに、部屋全体をくまなく歩き回って確認するのが昔の手法。対してSSDは、部屋の入り口からパッと全体を見渡しただけで「あそこに鍵、ここに財布!」と瞬時に把握するようなものです。
MultiBox(たくさんの箱で!)
画像の中に、あらかじめ決められたいろいろな形の「箱」を用意しておきます。これを専門用語でデフォルトボックスと呼びます。縦長の箱、横長の箱、正方形の箱などを画像全体に敷き詰めておき、その箱の中に物体がスッポリ入るかどうかをチェックするのです。
Detector(検出器!)
文字通り、検出するものです。
つまりSSDとは、いろいろな形の箱を使って、たった一回の処理で物体を見つけ出す検出器ということになります。
高校生でもわかる!SSDが物体を見つける仕組み
では、具体的にどうやって見つけているのでしょうか。ここで少し専門的な話をしますが、安心してください。例え話で攻略しましょう。
SSDの頭脳には、CNN(畳み込みニューラルネットワーク)という技術が使われています。これは、人間の視覚野を模したもので、画像の特徴を抽出するのが得意なAIです。
SSDのすごいところは、画像の解像度を少しずつ荒くしながら(小さくしながら)、それぞれの段階で物体を探す点にあります。
想像してみてください。あなたは今、ビルの屋上から街を見下ろしています。
広い範囲をぼんやり見ているときは、大きなバスやトラックのような「大きな物体」が見つけやすいですよね。
逆に、双眼鏡を使って狭い範囲を詳しく見ているときは、歩いている人や犬のような「小さな物体」が見つけやすくなります。
SSDはこれと同じことをしています。
- 大きな画像データ(細かい特徴地図)では、小さな物体を探す
- 小さな画像データ(粗い特徴地図)では、大きな物体を探す
このように、異なる縮尺の地図(特徴マップ)を何枚も用意して、それぞれの地図で大小さまざまな物体を同時に探しているのです。だから、小さいものから大きいものまで、漏らさず見つけることができるわけですね。
ここで計算式をイメージしてみよう
物体検出では、AIがどれくらい自信を持って「これは車だ!」と言っているかを表すスコアや、予測した枠が正解とどれくらい重なっているかという計算が頻繁に行われます。
SSDの内部で行われている評価のイメージを簡単な式で表してみましょう。AIが出す最終的な検出の良さは、以下のような要素の掛け算で決まると考えてください。
検出の信頼度 

ここで、枠の重なり具合というのは、AIが予測した枠と、正解の枠がどれくらい一致しているかを示す指標です。専門用語ではIoU(Intersection over Union)と呼びます。
また、たくさんの箱(MultiBox)の中から不要なものを消去する際にも、計算が行われます。
残すべき箱 
このように、単純な掛け算や比較計算を高速に繰り返すことで、SSDはリアルタイムに物体を検出し続けているのです。
現場で役立つ!SSDのメリットとデメリット
どんな技術にも得意・不得意があります。エンジニアとして大切なのは、ツールの特性を理解して使い分けることです。
メリット
- とにかく速いSingle Shotの名前の通り、処理が一回で済むため非常に高速です。防犯カメラの映像解析や、自動運転車の歩行者検知など、リアルタイム性が求められる場面で真価を発揮します。
- 学習が比較的簡単構造がシンプルなので、プログラムの実装難易度もそこまで高くありません。初心者が最初に触るモデルとしても最適です。
デメリット
- 小さな物体が苦手なことがある構造上、画像の深い層(粗い地図)に行くほど細かい情報が失われてしまうため、遠くにある小さな鳥や、密集した小さな部品などを見つけるのは、他のモデルに比べて少し苦手です。
- 精度の限界処理速度を優先しているため、処理を2段階に分けるモデル(Faster R-CNNなど)と比較すると、厳密な精度では少し劣る場合があります。
ここまでで、物体検出界の優等生であるSSDについてお話ししました。一度の処理で、大きさの違う地図を使って物体を見つける賢い仕組みでしたね。
さて、今日はそのSSDの最大のライバルであり、AIエンジニアなら誰もが一度は耳にする超有名モデル、YOLOについて解説します。
「YOLO」と聞いて、ヒップホップ用語の「You Only Live Once(人生は一度きり)」を思い浮かべた方、勘が鋭いですね。実はこのAIの名前も、そこから文字って名付けられているんです。
You Only Look Once(一度見るだけでいい)。
なんとも強気でかっこいい名前だと思いませんか。SSDと同じく一度の処理で検出を行うこのモデル、一体何が違うのでしょうか。今日はこの二大巨頭を比較しながら、その仕組みと使い分けについて学んでいきましょう!
グリッドで世界を見るYOLOの仕組み
SSDは、いろいろな大きさの「箱(デフォルトボックス)」を用意して物体を探していましたね。それに対してYOLOは、画像を「グリッド(格子)」に分割して物体を探します。
イメージしてみてください。
あなたは一枚の絵の上に、将棋盤のようなマス目を引きます。そして、それぞれのマス目に対してこう質問するのです。
「ねえ、このマスの中に、何かの物体の『中心』はあるかな?」
もし「あるよ!」と答えたマス目があったら、そのマスが責任を持って「それは何の物体か」「どのくらいの大きさか」を予測します。
SSDが「大きさの違う地図」を用意して全体をくまなく探すのに対し、YOLOは「画像を均等なマス目」に区切って、ピンポイントで担当を決めるというアプローチを取ります。
数式で見る!YOLOの出力データ
ここで、YOLOがどのように答えを出しているのか、少しだけ数式っぽい表現で見てみましょう。
YOLOは画像を 
初期のモデルでは、よく 
それぞれのグリッド(マス目)は、以下の情報を計算して出力します。
出力情報

バウンディングボックスというのは、物体を囲む枠のことです。
一つのマス目が「ここに犬がいるよ!」と判断したとき、その犬がどれくらいの大きさで、どの位置にいるのかを数値で出します。
もし、一つのマス目が2つの枠(ボックス)を予測し、見分けたい物体が20種類(クラス)あるとしましょう。そうすると、最終的な出力データのサイズは以下のようになります。
データサイズ

ちょっと複雑に見えますが、要するに「マス目の数だけ、予測データの束がある」と思えば大丈夫です。この計算を一気に処理してしまうため、YOLOは爆発的に速いのです。
SSDとYOLO、決定的な違いはここ!
では、エンジニアとして気になる「違い」について深掘りしましょう。どちらも「1回見るだけ(Single Shot)」なのに、何が異なるのでしょうか。
背景の誤検出が少ないYOLO
YOLOは、処理の途中で画像全体を広く見る構造になっています。そのため、「背景」を「物体」だと勘違いするミス(False Positive)が、SSDなどの他のモデルに比べて少ないと言われています。全体の文脈を読むのが得意なんですね。
小さい物体への対応力
昔の話をすると、初期のYOLOは「1つのマス目につき1つの物体」しか扱えなかったため、鳥の群れのような「小さくて密集しているもの」を見つけるのが苦手でした。
この点においては、大きさの違う地図を持つSSDの方が優秀でした。
ただし!最新のYOLO(v3以降やv8など)は進化を重ねており、SSDと同じような「多重スケール」の考え方を取り入れています。そのため、現在ではこの弱点はかなり克服されています。
メリットとデメリットの比較まとめ
現場で選定する際に役立つ比較ポイントを整理しました。
YOLOのメリット
- 圧倒的な速度処理がシンプルで、動画などのリアルタイム検出において最強クラスの速さを誇ります。
- 全体の雰囲気を掴むのが上手い画像全体を見て判断するため、背景と物体の区別が得意です。
- 進化のスピードが速いYOLO v1から始まり、v3, v4, v5, ... v8と、世界中の研究者が改良を続けており、常に最新の技術が取り入れられています。
YOLOのデメリット
- 位置ズレが起きやすいグリッドという大雑把な区切りで位置を決めるため、SSDに比べると、枠の位置が微妙にズレることがあります。
- 小さな物体の検出(旧バージョン)先ほど触れた通り、古いバージョンを使う場合は、遠くの小さな物体を見落とす可能性があります。
SSDとの使い分け
- 速度最優先ならYOLO自動運転やドローンの映像解析など、1ミリ秒でも速く処理したい場合はYOLOが第一候補です。
- 安定と実装のしやすさならSSD速度はそこそこで良く、小さな物体も丁寧に拾いたい場合、あるいは学習用データが少ない場合などは、挙動が枯れていて(安定していて)扱いやすいSSDを選ぶことも多いです。
今後の学習の指針
ここまで、SSDとYOLOという二つの強力な武器について学びました。
理論はなんとなく分かった!という状態になったら、次は実践あるのみです。
これからのステップとして、以下をおすすめします。
- YOLOの公式サイトやGitHubを見て、デモ動画を眺めてみる(その速さに感動しますよ!)
- Google Colaboratoryなどの無料環境を使って、自分の手持ちの動画をYOLOで解析してみる
- SSDとYOLO、同じ動画を読み込ませて、検出結果の違いを見比べてみる
「百聞は一見に如かず」と言いますが、AIの世界では「百読は一実行に如かず」です。
エラーが出ても大丈夫。それはあなたが前進している証拠ですからね。
最強の物体検出モデルを使いこなして、世の中を驚かせるようなアプリケーションを作ってみてください。
それでは、また次の記事でお会いしましょう。
セイ・コンサルティング・グループでは新人エンジニア研修のアシスタント講師を募集しています。
投稿者プロフィール
- 代表取締役
-
セイ・コンサルティング・グループ株式会社代表取締役。
岐阜県出身。
2000年創業、2004年会社設立。
IT企業向け人材育成研修歴業界歴20年以上。
すべての無駄を省いた費用対効果の高い「筋肉質」な研修を提供します!
この記事に間違い等ありましたらぜひお知らせください。
学生時代は趣味と実益を兼ねてリゾートバイトにいそしむ。長野県白馬村に始まり、志賀高原でのスキーインストラクター、沖縄石垣島、北海道トマム。高じてオーストラリアのゴールドコーストでツアーガイドなど。現在は野菜作りにはまっている。