
【決定係数R2】数式アレルギーでも大丈夫!予測モデルの「賢さ」を測る方法
 山崎講師
山崎講師こんにちは。ゆうせいです。
みなさんは、AIや統計データが出す「予測」をどこまで信じていますか。
たとえば「明日の降水確率は80%です」と言われたら傘を持ち歩くでしょう。しかし「来月のあなたの売上は100万円です」とAIに言われたら、その根拠や精度が気になりませんか。予測がどれくらい当たっているのか、その「精度の良さ」を表す指標がなければ、私たちは数値を信頼できません。
そこで登場するのが、今回解説する決定係数です。統計学の世界では 
名前だけ聞くと難しそうに感じるかもしれませんね。でも安心してください。これは言わば、予測モデルの「成績表」のようなものです。テストで言えば100点満点中何点取れたか、という感覚で理解できます。
数式を見ると逃げ出したくなる方に向けて、専門用語をかみ砕きながら、高校生でもわかるように丁寧に解説していきます。さあ、一緒にデータの裏側を覗いてみましょう。
決定係数とは予測の「当てはまり具合」
決定係数とは、一言で言えば「その予測式が、実際のデータをどれくらい説明できているか」を表す数値です。
もっと直感的に言いましょう。作成した予測モデルが「どれくらい優秀か」を示すスコアです。
スコアは通常、0から1の範囲で表されます。
1に近いほど、そのモデルは実際のデータを完璧に捉えています。
逆に0に近いほど、そのモデルは全然見当違いな予測をしている、ということになります。
成績表でイメージしよう
想像してみてください。あなたは友人の「数学のテストの点数」を予想しようとしています。
- 勉強時間
- 過去の平均点
- 睡眠時間
これらの情報を使って予測式を作りました。
もし、実際の点数とあなたの予測がピタリと一致し続けたら、決定係数は 
逆に、予測がかすりもしなければ、決定係数は 
統計分析をする際、私たちは「回帰分析」という手法を使って予測線(モデル)を作りますが、その線がどれだけデータの点に近いかを示すのがこの指標なのです。
定義式を分解して理解する
では、ここから少しだけ背伸びをして、決定係数の正体に迫ります。数式が出てきますが、怖がる必要はありません。日本語に翻訳しながら読み解いていきます。
決定係数 R2 の定義式

決定係数を求める式は、言葉で表すと以下のようになります。
決定係数 

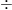
少し不思議な形をしていますね。「1から引く」という点がポイントです。なぜこんな形をしているのか、2つの重要な要素に分けて見ていきましょう。
1. 全変動(元々のデータのバラつき)
まず、予測など一切せずに、単に「みんなの平均点」を予想値とした場合を考えます。
実際のデータと平均値との差を二乗して合計したものを「全変動」と呼びます。これは、データが元々持っている「自然なバラつき」の大きさです。
2. 残差変動(予測が外れた分)
次に、私たちが一生懸命作った予測式を使います。
実際のデータと、予測式が弾き出した数値とのズレ(これを残差と呼びます)を二乗して合計したものを「残差変動」と呼びます。つまり、予測しきれずに残ってしまったミスの合計です。
数式の意味すること
もう一度、先ほどの日本語の式を思い出してください。
( 予測が外れた分
この部分は、「元々のバラつきに対して、どれくらいミスが残っているか」という「ミスの割合」を計算しています。
もし予測が完璧なら、外れた分はゼロになります。するとミスの割合もゼロです。
となり、決定係数は最大の
逆に、予測が平均値を使うのと変わらないくらい適当だと、ミスの割合は大きくなります。
もしミスの割合が
となり、決定係数は
つまり、決定係数とは「全体のバラつきのうち、予測式によって説明できた割合」を計算しているのです。だからこそ「寄与率」とも呼ばれるのですね。
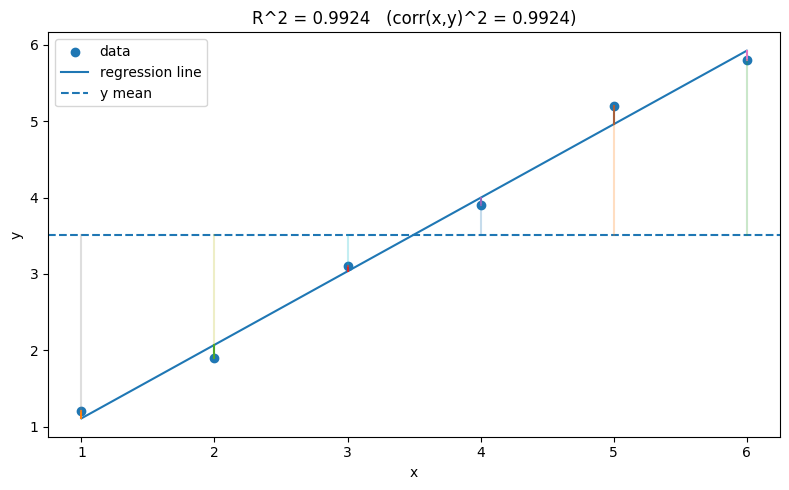
上図では、太い縦線で残差変動の元となる「残差」を、薄い縦線で「全変動」の元となる実際のデータと平均値との差を表現しています。この例では、決定係数がかなり1に近い(0.9924)であることが分かります。
豆知識:相関係数との不思議な関係
実は、もっと簡単に決定係数を知る裏技があります。
それは「相関係数を2乗するだけ」というものです。
例えば、相関係数 

計算はシンプルです。

これだけで、決定係数 
ただし、これには重要な条件があります。「説明変数が1つだけ(単回帰分析)」で、かつ「切片がある(原点を通るとは限らない)」場合限定です。
なぜこうなるのでしょうか。
相関係数は「データがどれくらい直線的に並んでいるか(関係の強さ)」を表します。
一方、決定係数は「予測直線でどれくらい説明できるか(当てはまり)」を表します。
変数が1つのシンプルな世界では、「直線状に並んでいること」と「直線で説明できること」は、実は表裏一体です。だからこそ、相関係数を2乗するだけで、決定係数へと変身できるのです。
複雑な計算をしなくても、相関係数さえ分かれば、その2乗でおよその予測精度が掴める。この関係性を知っておくと、データの見方がぐっと速くなりますよ!
決定係数を使うメリット
なぜ多くのデータサイエンティストやマーケターがこの数値を重視するのでしょうか。
直感的に評価できる
最大の利点は、わかりやすさです。「精度は 
モデルの説得力が増す
上司やクライアントに提案する際、「なんとなく当たりそうです」と言うより、「決定係数が 
知っておくべき注意点とデメリット
しかし、決定係数は万能ではありません。これだけを見て判断すると、痛い目を見ることがあります。
変数を増やすと勝手に上がる
ここが少し厄介な点です。予測に使うデータ(説明変数)の数を増やせば増やすほど、たとえそのデータが予測に全く関係なくても、決定係数は計算上高くなってしまう傾向があります。
例えば、テストの点数を予測するのに「今日の朝ごはんのメニュー」という無関係なデータを加えても、数値が少し上がってしまうことがあるのです。これを防ぐために、変数の数による影響を調整した「自由度調整済み決定係数」という指標を使うことが一般的です。
因果関係はわからない
決定係数が高くても、それは「計算上の相関が強い」というだけです。
「アイスクリームが売れると、プールでの溺れる事故が増える」というデータがあり、決定係数が高くても、アイスクリームが事故の原因ではありません(本当の原因は気温の高さです)。数値が高いからといって、そこに必ずしも因果関係があるとは限らないことを肝に銘じておきましょう。
まとめ
いかがでしたでしょうか。難しそうな数式も、中身を分解してみれば「どれだけミスを減らせたか」を計算しているだけだと分かりますね。
決定係数
- 予測モデルの成績表であり、1に近いほど優秀
- 全体のバラつきから、予測ミスの割合を引いて求める
- 変数を増やすだけで数値が上がる落とし穴があるため、過信は禁物
まずは手元のExcelなどで簡単な散布図を描き、近似曲線を表示させてみてください。そこに表示される
次のステップとしては、デメリットで触れた「自由度調整済み決定係数」や、実際にどれくらい予測がズレるかを具体的な数値で表す「RMSE(二乗平均平方根誤差)」について学んでみてください。これらを知ることで、あなたのデータ分析力はさらに磨かれていくはずです。
データ分析の旅を楽しんでくださいね!
セイ・コンサルティング・グループでは新人エンジニア研修のアシスタント講師を募集しています。
投稿者プロフィール
- 代表取締役
-
セイ・コンサルティング・グループ株式会社代表取締役。
岐阜県出身。
海外放浪の末、2000年創業、2004年会社設立。
IT企業向け人材育成研修歴業界歴20年以上。
すべての無駄を省いた費用対効果の高い「筋肉質」な研修を提供します!
この記事に間違い等ありましたらぜひお知らせください。
学生時代は趣味と実益を兼ねてリゾートバイトにいそしむ。長野県白馬村に始まり、志賀高原でのスキーインストラクター、沖縄石垣島、北海道トマム。高じてオーストラリアのゴールドコーストでツアーガイドなど。現在は野菜作りにはまっている。
最新の投稿
 山崎講師2026年8月1日コンピューターが数値計算の誤差に対処する仕組みと精度管理の方法
山崎講師2026年8月1日コンピューターが数値計算の誤差に対処する仕組みと精度管理の方法- 山崎講師2026年8月1日0乗が1になる理由を2乗の計算式から解説する指数法則の基礎
- 山崎講師2026年8月1日機械学習モデルの予測理由を解釈するSHAPとシャープレイ値の基礎
- 山崎講師2026年8月1日適合率と再現率の概念と初心者向けのわかりやすい再翻訳案

