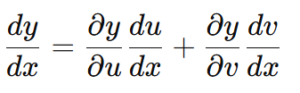機械翻訳の評価指標BLEUとは?名前の由来から仕組みまで初心者向けにやさしく解説
 山崎講師
山崎講師こんにちは。ゆうせいです。
みなさんは、Google翻訳やDeepLといった翻訳ツールを普段使っていますか?海外のニュースを読んだり、仕事でメールを書いたりと、今や生活に欠かせない存在になっていますよね。
でも、ふと疑問に思ったことはありませんか。
「この翻訳、本当に合ってるのかな?」
「GoogleとDeepL、どっちが賢いんだろう?」
実は、こういった「翻訳の質」を測るための通知表のようなものが存在します。それが今回解説する BLEU(ブルー) という指標です。
青色という意味のブルーではありませんよ。今日はこのBLEUについて、なぜそんな名前がついているのか、どうやって計算しているのか、一緒に学んでいきましょう。
BLEUの名前には「代役」という意味がある
まず、この少し変わった名前の由来からお話しします。BLEUは「Bilingual Evaluation Understudy」の頭文字をとった言葉です。
ここで注目してほしいのが、最後の Understudy という単語です。あまり聞き慣れない言葉かもしれませんが、これは演劇用語で「代役」を意味します。
なぜ翻訳の評価に「代役」が登場するのでしょうか。
本来、翻訳の良し悪しを判断する最高の方法は「人間が読むこと」です。バイリンガルの専門家が一つひとつ文章を読んで、「これは素晴らしい」「これは不自然だ」と採点するのが一番確実ですよね。
しかし、AIの研究開発では何千、何万という文章を扱います。そのすべてを人間がチェックしていたら、時間もお金もいくらあっても足りません。
そこで登場するのがBLEUです。
「人間の代わりに、機械が自動で採点してくれないかな?」
そんな願いから生まれたため、人間の評価者の「代役(Understudy)」という名前が付けられたのです。とてもユーモアのあるネーミングだと思いませんか?
どうやって点数をつけているの?
では、この代役さんはどのようにして翻訳の採点をしているのでしょうか。
仕組みはとてもシンプルです。「AIが翻訳した文章」と「人間が翻訳した正解の文章(参照訳)」が、どれくらい似ているかをチェックしています。
ここで重要なキーワードが登場します。 N-gram(エヌグラム) です。
なんだか難しそうな言葉が出てきたな、と身構えないでくださいね。これは、文章を「単語の塊」に区切る方法のことです。
たとえば、「I have a pen」という文章で考えてみましょう。
- 単語を1つずつ区切る(ユニグラム)
- I / have / a / pen
- 隣り合う2語で区切る(バイグラム)
- I have / have a / a pen
BLEUは、このように文章を細かく分解し、パズルのピース合わせのように「正解の文章と一致するピースがいくつあるか」を数えているのです。
数式で見てみよう
言葉だけだとイメージしづらいかもしれませんね。簡単な計算式で表してみましょう
基本的な考え方は、以下のようになります。
適合率 
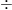
たとえば、AIが5つの単語を出力して、そのうち3つが正解の文章にも含まれていれば、3割る5で0.6、つまり60点ということになります。
実際には、単語1つのレベルだけでなく、2語、3語、4語といった長い塊での一致率も計算し、それらを掛け合わせて最終的なスコアを出します。
さらに、短すぎる文章が有利にならないようにペナルティを与えるなど、細かい調整も行われています。この計算式は少し複雑なので、ここでは「単語の並びが正解とどれだけ重なっているかを見ているんだな」と理解しておけば十分です。
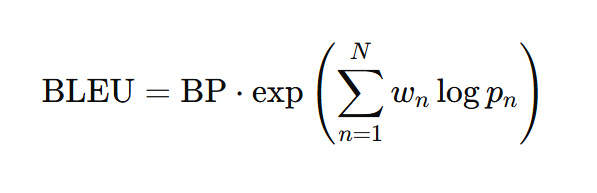
BLEUのメリットとデメリット
どんなに優れた指標にも、得意なことと苦手なことがあります。ここを理解しておくと、AIのニュース記事などを読むときにとても役立ちますよ。
メリット:速くて安い
最大のメリットは、名前の由来通り「人間の代役」として、大量の翻訳結果を瞬時に採点できることです。
人間なら数日かかる作業を、コンピュータなら一瞬で終わらせることができます。これにより、AIの研究者は新しいモデルを作ってすぐに性能を確認し、開発のスピードを上げることができるのです。
また、言語に依存しないという特徴もあります。英語でも日本語でもフランス語でも、単語の並びさえ比較できれば計算可能です。
デメリット:意味までは理解していない
一方で、BLEUには弱点もあります。それは「意味が合っているか」ではなく「単語が一致しているか」しか見ていない点です。
たとえば、「とても美味しい」を翻訳する場合を想像してください。
- 正解の文章:It is very delicious.
- AIの翻訳:It is so tasty.
この二つは意味としてはほぼ同じですよね。人間なら「正解!」と言うでしょう。しかし、BLEUから見ると「very」と「so」、「delicious」と「tasty」は別の単語です。そのため、「単語が一致していない」と判断され、スコアが低くなってしまうのです。
逆に、文法がめちゃくちゃでも、正解の文章に含まれる単語がたくさん入っていれば、高いスコアが出てしまうこともあります。
つまり、BLEUの点数が高いからといって、必ずしも人間にとって自然で優れた翻訳だとは限らないのです。ここには十分注意してくださいね。
まとめと次のステップ
いかがでしたか。
今回は機械翻訳の評価指標であるBLEUについて解説しました。
- BLEUは人間の評価者の「代役(Understudy)」という意味
- N-gramという仕組みで、単語の並びがどれくらい一致しているかを計算する
- 計算は速いが、言葉の意味やニュアンスまでは理解できない
この3つのポイントを覚えておけば、もうBLEUは怖くありません。
もしこれからさらに深く学んでみたいと思ったら、次は「METEOR(メテオ)」や「COMET(コメット)」といった、BLEUの欠点を補うために開発された新しい評価指標について調べてみるのがおすすめです。意味の類似性を考慮できるこれらの指標を知ることで、AI翻訳の進化をより深く理解できるはずです。
ぜひ、興味の赴くままに学習を続けてみてくださいね!
セイ・コンサルティング・グループでは新人エンジニア研修のアシスタント講師を募集しています。
投稿者プロフィール