
もっとシンプルに、もっと速く!LSTMの進化系「GRU」を徹底解釈
 山崎講師
山崎講師こんにちは。ゆうせいです。
前回の記事では、複雑なゲートを操るLSTMについてお話ししましたね。「仕組みはわかったけれど、計算が重そうで大変そう……」と感じた方も多いのではないでしょうか?
そんなあなたに朗報です!今回は、LSTMの強力な記憶力を保ちつつ、構造をスッキリとスリム化させた「GRU(Gated Recurrent Unit)」をご紹介します。
AIの世界でも「断捨離」は重要なんですよ!
GRUは「引き算」の美学
GRUは、2014年に提案された比較的新しい構造です。LSTMには3つ(あるいは4つ)のゲートがありましたが、GRUはそれをたったの2つに絞り込みました。
「えっ、減らしても大丈夫なの?」と思うかもしれません。しかし、これが驚くほど効率的なんです。
1. リセットゲート:過去をどのくらい無視するか
まず1つ目の門が「リセットゲート」です。これは、新しい入力を受け取るときに、これまでの記憶をどれだけチャラにするかを決めます。
計算式:
![r_{t} = \sigma ( W_{r} \cdot [ h_{t-1}, x_{t} ] + b_{r} )](https://s0.wp.com/latex.php?latex=r_%7Bt%7D+%3D+%5Csigma+%28+W_%7Br%7D+%5Ccdot+%5B+h_%7Bt-1%7D%2C+x_%7Bt%7D+%5D+%2B+b_%7Br%7D+%29+&bg=ffffff&fg=000&s=0&c=20201002)
例えば、文章の途中で「句読点」が来たとき、それまでの細かい文脈をリセットして新しいフレーズに備えるようなイメージです。
シグモイド関数 


という制御を、数学的に行っているわけですね。
2. アップデートゲート:新旧のバランスを調整
2つ目が、GRUの真骨頂である「アップデートゲート」です。これは、LSTMの「入力ゲート」と「忘却ゲート」をひとつにまとめたような役割を持っています。
計算式:
![z_{t} = \sigma ( W_{z} \cdot [ h_{t-1}, x_{t} ] + b_{z} )](https://s0.wp.com/latex.php?latex=z_%7Bt%7D+%3D+%5Csigma+%28+W_%7Bz%7D+%5Ccdot+%5B+h_%7Bt-1%7D%2C+x_%7Bt%7D+%5D+%2B+b_%7Bz%7D+%29+&bg=ffffff&fg=000&s=0&c=20201002)
このゲートが「どれくらい過去の情報を残し、どれくらい新しい情報を取り込むか」の比率を決定します。
面白いのは、この比率の使い道です。
新しい状態を 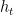
計算概念:

わかりますか? 



GRUを選ぶメリットとデメリット
研修でもよく「LSTMとどっちが良いですか?」と聞かれます。それぞれの特性を比較してみましょう。
GRUのメリット
- 計算が速い:ゲートが少ない分、計算量が抑えられ、学習時間が短縮されます。
- パラメータが少ない:重みの数が少ないため、データセットが小さい場合でも過学習(学習データにだけ強くなりすぎて応用が利かなくなること)しにくい傾向があります。
- 構造がシンプル:実装やデバッグが比較的スムーズです。
GRUのデメリット
- 表現力の限界:非常に複雑な長期依存関係を持つデータでは、ゲートが多いLSTMの方が高い精度を出すことがあります。
- 歴史が浅い:長年使われてきたLSTMに比べると、文献や事例がわずかに少ない場合があります。
結局、どちらを使えばいいの?
結論から言うと、まずは「GRU」を試してみるのが現代流の賢い選択です!
計算効率が良いため、試行錯誤のサイクルを速く回せます。そこで精度が足りないと感じたら、満を持して「LSTM」へ移行するという流れがスムーズですよ。
さて、数式の裏側にある「情報の取捨選択」のドラマ、感じていただけましたか?
これにてRNN三部作(勾配消失・LSTM・GRU)は完結です!
次なるステップとして、これらのネットワークをさらに進化させた「双方向RNN(Bi-RNN)」や、最近のトレンドである「Attention(注意機構)」の世界を覗いてみませんか?
まずは、KerasやPyTorchで layers.GRU と1行書いて、モデルを作ってみることからスタートしましょう!応援していますよ!
セイ・コンサルティング・グループでは新人エンジニア研修のアシスタント講師を募集しています。
投稿者プロフィール
- 代表取締役
-
セイ・コンサルティング・グループ株式会社代表取締役。
岐阜県出身。
海外放浪の末、2000年創業、2004年会社設立。
IT企業向け人材育成研修歴業界歴20年以上。
すべての無駄を省いた費用対効果の高い「筋肉質」な研修を提供します!
この記事に間違い等ありましたらぜひお知らせください。
学生時代は趣味と実益を兼ねてリゾートバイトにいそしむ。長野県白馬村に始まり、志賀高原でのスキーインストラクター、沖縄石垣島、北海道トマム。高じてオーストラリアのゴールドコーストでツアーガイドなど。現在は野菜作りにはまっている。
最新の投稿
 山崎講師2026年8月2日自然対数eはどこから生まれたのか:歴史から理解する定数の意味
山崎講師2026年8月2日自然対数eはどこから生まれたのか:歴史から理解する定数の意味- 山崎講師2026年8月2日片側検定と両側検定の使い分け方を具体例から学ぶ
- 山崎講師2026年8月1日コンピューターが数値計算の誤差に対処する仕組みと精度管理の方法
- 山崎講師2026年8月1日0乗が1になる理由を2乗の計算式から解説する指数法則の基礎
