
E資格合格のための聖典!深層学習の原典論文・徹底解説ロードマップ
 山崎講師
山崎講師ディープラーニングの世界を本当に理解するためには、解説書だけでなく、技術が産声を上げた瞬間の記録である「原論文」に触れることが一番の近道です。
E資格合格のための聖典!深層学習の原典論文・徹底解説ロードマップ
E資格の試験範囲は広大ですが、その核となるのは「なぜこの技術が生まれたのか」という研究者たちの試行錯誤の歴史です。二次情報(解説記事)だけで学習すると、数式の意味やパラメータの意図が抜け落ちてしまいがちです。
この記事では、JDLAのシラバスの中でも特に重要な「世界を変えた論文」を軸に、全6回の連載形式で再構成していきます。
記事構成の全体像:全6回でマスターする「原典」の世界
元の膨大な情報を、学習のステップに合わせて以下の6回に分割しました。各回で紹介する論文は、E資格で「その名前や数式が直接問われる」レベルのものばかりです。
- 第1回:最適化と正則化の原典(Dropout, Batch Norm, Adam)
- 第2回:画像認識CNNの進化(前編)(AlexNet, VGG)
- 第3回:画像認識CNNの進化(後編)(GoogLeNet, ResNet)
- 第4回:物体検出とセグメンテーションの革命(R-CNN, YOLO, U-Net)
- 第5回:自然言語処理のパラダイムシフト(Attention, Transformer, BERT)
- 第6回:生成モデルと深層強化学習の真髄(VAE, GAN, DQN)
今回は第1回として、ニューラルネットワークを正しく、そして速く学習させるための「三種の神器」に関する論文を紹介します!
第1回:最適化と正則化の原典〜迷宮を最速で抜けるために〜
深いネットワークの学習は、複雑な迷路を歩くようなものです。行き止まり(過学習)を避け、効率よくゴール(最適解)へたどり着くために、以下の3つの論文が道標となりました。
1. Dropout:あえて「サボり」を作って過学習を防ぐ
深層学習において最大の敵は、訓練データに馴染みすぎてしまう過学習です。
- 論文名: Dropout: A Simple Way to Prevent Neural Networks from Overfitting
- URL: http://jmlr.org/papers/v15/srivastava14a.html
- 著者: Srivastava, Hinton, et al. (2014)
この論文が提案したのは「学習のたびに、ランダムにニューロンを消去(ドロップアウト)する」という驚くほどシンプルな手法です。
数理的エッセンス
各層の出力に対して、確率
で 1 、
で 0 となるマスクを掛けます。
(
はベルヌーイ分布に従う変数)
これにより、特定のニューロンが特定のデータに依存しすぎるのを防ぎ、ネットワーク全体に「一人でも仕事をこなせる根性」を叩き込みます。
2. Batch Normalization:学習の「加速」と「安定」の標準
層が深くなると、データの分布がバラバラになり、学習が止まってしまう「内部共変量シフト」が発生します。
- 論文名: Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
- URL: https://arxiv.org/abs/1502.03167
- 著者: Ioffe & Szegedy (2015)
この論文の凄さは、ミニバッチごとにデータを平均 0 、分散 1 に強制的に整列させる(正規化する)仕組みを作ったことです。
学習可能なパラメータの導入
単に 0 と 1 に整列させるだけでなく、
という式を用いて、ネットワーク自身が「最適な分布」を再調整できるようにしました。
メリットは、学習が劇的に速くなること。デメリットは、ミニバッチのサイズに依存するため、あまりに小さなバッチサイズだと不安定になる点です。
3. Adam:適応的学習率の決定版
勾配を下る際、歩幅(学習率)をどう決めるかは永遠の課題でした。
- 論文名: Adam: A Method for Stochastic Optimization
- URL: https://arxiv.org/abs/1412.6980
- 著者: Kingma & Ba (2014)
Adamは「勢い(モーメンタム)」と「過去の勾配の大きさ(RMSProp)」を組み合わせたハイブリッド手法です。
バイアス補正の重要性
学習の開始直後は、過去のデータがないため計算が 0 に偏ってしまいます。
$latex \hat{m}{t} = m{t} / (1 - \beta_{1}^{t}) $
この式で割り戻すことで、最初の一歩を正確に踏み出せるようにしています。
論文比較テーブル:三種の神器の役割
| 論文技術 | 解決する主な課題 | E資格での注目ポイント |
| Dropout | 過学習(共適応) | 推論時の重みスケーリング計算 |
| Batch Norm | 内部共変量シフト | 学習時と推論時の挙動の違い |
| Adam | 学習の停滞・発散 | バイアス補正が必要な数学的理由 |
まとめ
これらの論文は、今ではライブラリで1行書くだけで呼び出せますが、その裏には「なぜこれでうまくいくのか」という数学的なドラマが詰まっています。
E資格の試験では、こうした「手法の併用」や「推論時の計算」がよく問われます。まずは各論文のURLをブックマークして、アブストラクト(要旨)だけでも眺めてみてください。
さて、次回はいよいよ画像認識の王道、CNNの歴史を塗り替えた論文たちを紹介します!
VGGやResNetといった、美しくも力強いネットワーク構造の裏側に迫ります。
第2回:視覚を支えるCNNの進化(前編)〜深層化の幕開け〜
画像認識の世界には、その歴史を大きく塗り替えた「優勝モデル」たちが存在します。今回は、第3次AIブームの火付け役となったモデルと、その後の設計指針を決定づけた超重要論文の2本立てです。
1. AlexNet:深層学習時代の幕開け
2012年、画像認識のコンペティション(ILSVRC)で、それまでの常識を覆す圧倒的な精度で優勝したのがこの論文です。
- 論文名: ImageNet Classification with Deep Convolutional Neural Networks
- URL: https://proceedings.neurips.cc/paper/2012/file/c399862d3b9d6b76c8436e924a68c45b-Paper.pdf
- 著者: Krizhevsky, Sutskever, Hinton (2012)
AlexNetは、現代の私たちが当たり前に使っている技術を「組み合わせて勝てること」を証明しました。
革新的なポイント
- ReLU関数の採用: 昔の主流だったSigmoidではなく、
というシンプルな関数を使うことで、計算を速くし、勾配が消えてしまうのを防ぎました。
- GPUの並列処理: 当時はメモリが少なかったため、2つのGPUに分割して計算するという力技を実現しています。
- データ拡張(Data Augmentation): 画像を反転させたり切り抜いたりして、無理やり学習データを増やす工夫もここから本格化しました。
2. VGGNet:3 × 3 フィルタの魔法
AlexNetの登場後、「どうすればもっと精度が上がるのか?」という問いに対し、「構造をシンプルにして、とにかく深くしよう」と答えたのがこの論文です。
- 論文名: Very Deep Convolutional Networks for Large-Scale Image Recognition
- URL: https://arxiv.org/abs/1409.1556
- 著者: Simonyan & Zisserman (2014)
VGGの最大の特徴は、すべての畳み込み層で 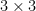
なぜ大きなフィルタを使わないのでしょうか?実は、 
E資格頻出!パラメータ計算の例
チャネル数が
のとき
畳み込み1層の重み:
なんと、同じ範囲を見ているのにパラメータ数を約半分に節約できるんですね。

論文の比較:設計思想の違い
| 項目 | AlexNet (2012) | VGGNet (2014) |
| 主な貢献 | 深層学習の有効性を証明 | 構造の定型化( の積層) |
| 活性化関数 | ReLUをいち早く採用 | ReLUを多層に重ねて表現力向上 |
| 受容野の考え方 | 層ごとにサイズがバラバラ | 小さなフィルタの積層で代用 |
| E資格のツボ | LRN(側抑制)の概念 | パラメータ数の削減計算 |
まとめ
AlexNetが「深層学習の扉」を開き、VGGが「深くするためのルール」を作ったという流れ、ワクワクしますよね。
特にVGGの「小さなフィルタを重ねる」というアイデアは、現代のあらゆるモデルの基礎になっています。もしあなたが今、複雑な問題に直面しているなら、それを細かく分解して積み重ねていくVGGの精神がヒントになるかもしれませんよ!
今後の学習の指針:
VGGの章で紹介した「受容野とパラメータ数の関係」は、計算問題として本当によく出ます。
さて、次回はさらに進化して、ネットワークの中に「バイパス(近道)」を作ることで100層を超える深さを実現したResNetなどの論文を紹介します。
第3回:画像認識CNNの進化(後編)〜効率性と超深層への到達〜
「もっと深くしたい、でも計算量が足りない」「深くすると逆に精度が落ちる」……そんな絶望的な状況を救ったのが、今回紹介する論文たちです。
1. GoogLeNet:幅と効率の「Inception」
VGGが「深く」することにこだわったのに対し、Googleのチームは「幅」と「効率」に注目しました。
- 論文名: Going Deeper with Convolutions
- URL: https://arxiv.org/abs/1409.4842
- 著者: Szegedy et al. (2014)
この論文で登場する Inceptionモジュール は、ひとつの層の中で 
1 × 1 畳み込みによる魔法(次元削減)
ここで最も重要なのが
畳み込みです。大きなフィルタで計算する前に、これを使ってデータの「厚み(チャネル数)」をギュッと絞り込みます。
例えば、チャネルを 256 から 32 に減らしてから計算すると、全体の計算量を 1/10 近くまで減らせることもあるんです。この「ボトルネック構造」の計算は、E資格で本当によく狙われますよ!
2. ResNet:100層の壁を壊した「近道」
GoogLeNetよりもさらに衝撃的だったのが、2015年に登場したResNetです。
- 論文名: Deep Residual Learning for Image Recognition
- URL: https://arxiv.org/abs/1512.03385
- 著者: He et al. (2015)
それまでの研究では、層を深くしすぎると、かえって学習が進まなくなる 劣化問題 に悩まされていました。これを解決したのが スキップ接続(残差学習) です。
数理的エッセンス:なぜ「+1」が最強なのか
通常の層が
を学習するのに対し、ResNetは入力をそのまま足し合わせて
とします。
逆伝播(答え合わせの信号を送る時)を想像してください。足し算の微分は 1 なので、どれだけ層が深くても、信号が「 1 」という係数によって薄まることなく下層まで届くんです!

この「 +1 」という安全装置のおかげで、人類は152層、さらには1000層を超える超深層ネットワークを手にすることができました。
論文の比較:革新的な構造の違い
| モデル | GoogLeNet (2014) | ResNet (2015) |
| キーワード | Inceptionモジュール | 残差学習(スキップ接続) |
| 主な発明 | 畳み込みによる次元削減 | 劣化問題の解決(勾配のハイウェイ) |
| 最終層の工夫 | Global Average Pooling (GAP) | GAPを標準採用 |
| E資格のポイント | ボトルネック構造の計算量削減 | の数式理解 |
まとめ
「計算量を減らすための工夫」と「信号を消さないための工夫」。この2つのアプローチが合流したことで、今のAIのパワーが支えられていることがわかりますね。
あなたは、何か大きな目標に向かっているとき、遠回りだと思って避けている「近道(スキップ接続)」はありませんか?時には最短距離で信号を伝えることも大切ですよ!
今後の学習の指針:
GoogLeNetの「
さて、次回はさらに世界が広がります。
「画像の中に何があるか」だけでなく、「どこにあるか」を特定する 物体検出 と セグメンテーション の論文たちをご紹介します。
第4回:物体検出とセグメンテーションの革命〜「どこにあるか」を射抜く〜
自動運転車が歩行者を見つけたり、医療AIがガンの患部を特定したり。そんな魔法のような技術を支えているのが、今回紹介する論文たちです。
1. Faster R-CNN:領域提案の自動化
画像から物体の候補を探すとき、昔は外部のプログラムに頼っていました。それを「全部AIの中でやればいいじゃない!」と解決したのがこの論文です。
- 論文名: Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
- URL: https://arxiv.org/abs/1506.01497
- 著者: Ren et al. (2015)
Faster R-CNNは、画像の中から「ここらへんに何かありそう!」という場所を見つけ出す RPN (Region Proposal Network) を導入しました。
アンカーボックスの知恵
RPNでは、あらかじめ決められた様々な大きさや形の四角(アンカーボックス)を画像にばらまき、それを微調整することで物体を囲みます。
「候補を探すネットワーク」と「中身を当てるネットワーク」が力を合わせる 2段階検出 の王者です。
2. YOLO:一瞬で全てを見抜く「一撃」
Faster R-CNNが丁寧な2段構えなら、こちらは「1回見るだけで全部当てるぜ!」というスピード狂の論文です。
- 論文名: You Only Look Once: Unified, Real-Time Object Detection
- URL: https://arxiv.org/abs/1506.02640
- 著者: Redmon et al. (2016)
YOLOは画像をグリッド(格子)に分割し、各マス目が「俺の担当エリアに物体はあるか?」「あるなら形は?」を一斉に予測します。
速度と精度のトレードオフ
YOLOは圧倒的に速いため、動画のリアルタイム解析に向いています。ただし、初期のモデルは小さな物体がひしめき合っている場所は少し苦手でした。この「速いけど小回りが苦手」という特徴は、エンジニアとして覚えておきたいポイントですね。
3. U-Net:ピクセル単位の精密な切り出し
「四角で囲む」だけじゃ足りない。そんな時に使われるのが、ピクセル単位で塗り分けるセグメンテーション技術です。
- 論文名: U-Net: Convolutional Networks for Biomedical Image Segmentation
- URL: https://arxiv.org/abs/1505.04597
- 著者: Ronneberger et al. (2015)
U-Netはその名の通り、ネットワークの形が「Uの字」をしています。左側で画像をギュッと圧縮して意味を理解し、右側で元の大きさに復元(アップサンプリング)していきます。
スキップ接続の再登場
ここでもResNetに似た「近道」が活躍します。左側で持っていた「細かい位置情報」を、右側の復元している層に直接合体(結合)させます。
これにより、輪郭がぼやけることなく、非常に精密な切り出しが可能になりました。元は医療用ですが、今やセグメンテーションのデファクトスタンダードです!
検出手法の比較:あなたならどれを選ぶ?
| 手法 | アプローチ | 速度 | 得意なこと |
| Faster R-CNN | 2段階(候補探し → 分類) | 低(丁寧) | 小さな物体の正確な検出 |
| YOLO | 1段階(一括回帰) | 極高(爆速) | リアルタイム監視、動体検知 |
| U-Net | Encoder-Decoder構造 | 中 | 境界線まで含めた精密な領域分割 |
まとめ
「丁寧に探す」「一気に当てる」「細かく塗り分ける」。目的に合わせて、先人たちがどれほど知恵を絞ってきたかが伝わってきますね。
あなたは今日、自分の周りにあるものを「物体検出」してみましたか?「これはコーヒー、これはスマホ」と認識できる裏側で、こんな数式たちが働いていると思うと、世界が少し違って見えませんか?
今後の学習の指針:
E資格では IoU (Intersection over Union) という「重なり具合」を示す指標の計算が必須です。

この公式を使って、予測がどれだけ当たっているか判定する練習をしてみてください!
さて、次回はさらにエキサイティングな領域へ。
画像の世界を飛び出し、言葉や時間の流れを扱う 自然言語処理(NLP) の革命児、TransformerとBERTの論文を徹底解説します!
AIが「文脈」を理解できるようになった魔法の数式の秘密、知りたくありませんか?準備はいいですか?
第5回:自然言語処理のパラダイムシフト〜文脈を操るAttentionの魔法〜
以前のAIは、長い文章を最後まで読むと最初の方を忘れてしまう「物忘れ」に悩まされていました。その弱点を克服し、今のChatGPTなどの基盤を作った革命的な論文たちをご紹介します!
1. LSTM:長期記憶を可能にした「水門」の知恵
言葉は時間の流れに沿って並んでいます。これを扱うのがRNN(リカレントニューラルネットワーク)ですが、普通のRNNは過去の情報をどんどん忘れてしまいます。それを救ったのがLSTMです。
- 論文名: Long Short-Term Memory
- URL: http://www.bioinf.jku.at/publications/older/2604.pdf
- 著者: Hochreiter & Schmidhuber (1997)
LSTMは、情報をどれくらい残すか、どれくらい捨てるかを「ゲート(門)」でコントロールします。
CEC(Constant Error Carousel)の凄さ
従来のRNNが「掛け算」で過去を振り返っていたのに対し、LSTMは「足し算」で情報を保持します。
この足し算のおかげで、答え合わせの信号が消えることなく、100ステップ以上前の情報まで届くようになったのです。

2. Transformer:Attentionこそがすべて
2017年、NLPの世界に地殻変動が起きました。「もうRNNはいらない。必要なのは注意(Attention)だけだ!」と言い切った伝説の論文です。
- 論文名: Attention Is All You Need
- URL: https://arxiv.org/abs/1706.03762
- 著者: Vaswani et al. (2017)
Transformerは、文章の単語を順番に処理するのをやめ、すべての単語を同時に見て「どの単語とどの単語が関係深いか」を計算します。
暗記必須!Scaled Dot-Product Attention
ここで
で割っているのはなぜでしょう?実は、次元が大きくなると計算結果が巨大になりすぎて、学習が止まってしまうのを防ぐための「スケーリング」なんです。E資格で理由を問われる定番問題ですよ!

3. BERT:双方向から文脈を深く読み解く
Transformerをさらに進化させ、「文の前後両方」を同時に読み込むことで圧倒的な理解力を手にしたのがBERTです。
- 論文名: BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- URL: https://arxiv.org/abs/1810.04805
- 著者: Devlin et al. (2018)
BERTは、文章の一部を虫食い状態にして、そこに入る言葉を当てる訓練(Masked Language Model)を行います。
双方向性のメリット
例えば「あのお店のパンは( )しい」という文があったとき、後ろの「しい」まで見ることで、カッコ内が「おい」である確率が高いと判断できます。この「先読み」と「振り返り」を同時に行うのがBERTの強みです。
論文の変遷:言葉をどう捉えるか?
| モデル | 登場年 | 核心的なアイデア | 最大のメリット |
| LSTM | 1997 | ゲート機構とCEC | 長い文章の情報を保持できる |
| Transformer | 2017 | Self-Attention | 並列計算が可能で、学習が爆速 |
| BERT | 2018 | 双方向Encoder | 単語の意味を文脈から深く理解できる |
まとめ
「Attention(注意)」という仕組みは、人間が文章を読むときに「大事なキーワードを無意識に追っている」動作によく似ています。数式が人間の知能を模倣していく過程は、本当に美しいですよね。
あなたは今、この記事のどの単語に「Attention」を向けていますか?その集中力があれば、E資格合格も目の前です!
今後の学習の指針:
Transformerの「 
さて、いよいよ連載も最終回。
次回は、画像生成でおなじみの GAN や VAE 、そして囲碁AIなどで有名な 強化学習 の論文たちを解説します!
AIが「自ら考え、創り出す」領域の原典、最後まで一緒に走り抜けましょう。準備はいいですか?
第6回:生成モデルと深層強化学習の真髄〜創造と自律のフロンティア〜
AIが本物そっくりの画像を描いたり、人間を超えたゲームプレイを見せたり。その裏側にある、数学的に最も美しい「駆け引き」の物語を解き明かしましょう!
1. VAE:確率で「空間」を埋める
データをただ圧縮するのではなく、その背後にある「特徴の分布」を学習しようとしたのがこの論文です。
- 論文名: Auto-Encoding Variational Bayes
- URL: https://arxiv.org/abs/1312.6114
- 著者: Kingma & Welling (2013)
VAE(変分オートエンコーダ )は、画像を「潜在変数 
Reparameterization Trick(再パラメータ化トリック)
確率分布から値をランダムに選ぶ操作は、そのままでは微分(学習)ができません。
そこで、
(
はノイズ)という式に変換することで、確率的な要素を切り離し、数学的に正しく学習できるようにしました。この「賢いすり替え」がVAEの核です!
2. GAN:偽物師と鑑定士の命懸けの勝負
21世紀で最も面白いアイデアの一つと言われるのが、この「敵対的生成ネットワーク」です。
- 論文名: Generative Adversarial Nets
- URL: https://arxiv.org/abs/1406.2661
- 著者: Goodfellow et al. (2014)
生成器(G)と識別器(D)という2つのAIを戦わせることで、お互いを高め合わせます。
ミニマックス問題の数式
Dは「本物か偽物か」を見破る確率を最大にしようとし、GはDが「間違える」確率を最大にしようとします。このスリリングな追いかけっこの末に、本物と見分けがつかない画像が生まれるのです!
![\min_{G} \max_{D} V(D, G) = \mathbb{E}[\log D(x)] + \mathbb{E}[\log (1 - D(G(z)))]](https://s0.wp.com/latex.php?latex=%5Cmin_%7BG%7D+%5Cmax_%7BD%7D+V%28D%2C+G%29+%3D+%5Cmathbb%7BE%7D%5B%5Clog+D%28x%29%5D+%2B+%5Cmathbb%7BE%7D%5B%5Clog+%281+-+D%28G%28z%29%29%29%5D+&bg=ffffff&fg=000&s=0&c=20201002)
3. DQN:ビデオゲームを攻略するAI
最後に紹介するのは、深層学習と強化学習を組み合わせ、AIが自ら試行錯誤して目標を達成する仕組みです。
- 論文名: Playing Atari with Deep Reinforcement Learning
- URL: https://arxiv.org/abs/1312.5602
- 著者: Mnih et al. (2013)
強化学習にCNN(画像認識)を組み込み、ゲーム画面を見るだけで最適な操作(Q値)を判断できるようにしました。
安定させる2つの工夫
- Experience Replay: 過去の経験をメモリに保存し、ランダムに取り出して復習する。
- Target Network: 答え合わせ用の手本を一時的に固定し、学習がフラフラしないようにする。
この安定化技術は、E資格の強化学習分野で最も狙われるポイントです!
生成と行動:技術の比較
| 分野 | 代表論文 | 目的 | キーワード |
| 生成(確率) | VAE | データの分布を捉える | 潜在変数、ELBO、再パラメータ化 |
| 生成(対抗) | GAN | 究極の偽物を作る | 敵対的学習、ナッシュ均衡 |
| 強化学習 | DQN | 行動の最適化 | Q学習、経験リプレイ |
まとめ
こうして振り返ってみると、一つひとつの技術は、前の世代が残した課題への「回答」になっていることがわかります。
E資格の勉強は、単なる暗記ではありません。研究者たちが「もっと良くしたい!」と願った情熱の足跡を辿る旅なのです。その旅路で出会った数式たちは、あなたがエンジニアとして壁にぶつかったとき、必ず助けになってくれますよ。
今後の学習の指針:
最後の仕上げとして、各論文の「タイトル・著者・解決した課題」をセットで整理した自分だけのリストを作ってみてください。また、VAEの損失関数の意味や、GANの目的関数の符号(なぜプラスなのかマイナスなのか)を論理的に説明できるようにしておけば、合格はもう目の前です!
このガイドが、あなたの挑戦の力強い味方になれたなら、これほど嬉しいことはありません。
さあ、次はあなたが新しい「原典」を作る番かもしれませんね。応援しています!
セイ・コンサルティング・グループでは新人エンジニア研修のアシスタント講師を募集しています。
投稿者プロフィール
- 代表取締役
-
セイ・コンサルティング・グループ株式会社代表取締役。
岐阜県出身。
海外放浪の末、2000年創業、2004年会社設立。
IT企業向け人材育成研修歴業界歴20年以上。
すべての無駄を省いた費用対効果の高い「筋肉質」な研修を提供します!
この記事に間違い等ありましたらぜひお知らせください。
学生時代は趣味と実益を兼ねてリゾートバイトにいそしむ。長野県白馬村に始まり、志賀高原でのスキーインストラクター、沖縄石垣島、北海道トマム。高じてオーストラリアのゴールドコーストでツアーガイドなど。現在は野菜作りにはまっている。
最新の投稿
 山崎講師2026年8月2日指数と対数は何が違うのか:逆の関係を理解する
山崎講師2026年8月2日指数と対数は何が違うのか:逆の関係を理解する- 山崎講師2026年8月2日自然対数eはどこから生まれたのか:歴史から理解する定数の意味
- 山崎講師2026年8月2日片側検定と両側検定の使い分け方を具体例から学ぶ
- 山崎講師2026年8月1日コンピューターが数値計算の誤差に対処する仕組みと精度管理の方法
