
AIが賢くなる秘密の鍵!勾配策定定理を世界一わかりやすく解説
 山崎講師
山崎講師こんにちは。ゆうせいです。
最近、AIがチェスで人間に勝ったり、複雑な絵を描いたりするニュースをよく耳にしますよね。どうやってAIは「正解」を見つけているのでしょうか?
その核心にあるのが「勾配策定定理(こうばいさくていていり)」、英語では Policy Gradient Theorem(ポリシー・グラディエント・セオリー)と呼ばれる理論です。名前は難しそうですが、実は私たちが日常で行っている「反省と改善」を数学にしたものなんです。
AIの「性格」を決める Policy とは?
まず、AI(エージェント)がどう行動するかを決める「ルールブック」のことを専門用語で Policy(方策)と呼びます。
例えば、迷路で右に行くか左に行くか、その確率を決めているのがこの Policy です。高校生の方なら、テストで「わからなかったら3番に丸をつける」という自分なりの作戦を持っているかもしれません。それも立派な Policy ですね。
AIはこの Policy をどんどん書き換えて、より良い結果(報酬)が得られるように成長していきます。
勾配策定定理の役割
では、どうやって Policy を書き換えればいいのでしょうか?適当に変えても上手くいきませんよね。
ここで登場するのが勾配策定定理です。この定理は「報酬を最大にするためには、Policy をどの方向に、どれくらい修正すればよいか」を計算で導き出すための指針になります。
数学的には、報酬の期待値 
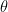
![\nabla_{\theta} J(\theta) = E [ \nabla_{\theta} \log \pi_{\theta}(a|s) Q(s, a) ]](https://s0.wp.com/latex.php?latex=%5Cnabla_%7B%5Ctheta%7D+J%28%5Ctheta%29+%3D+E+%5B+%5Cnabla_%7B%5Ctheta%7D+%5Clog+%5Cpi_%7B%5Ctheta%7D%28a%7Cs%29+Q%28s%2C+a%29+%5D+&bg=ffffff&fg=000&s=0&c=20201002)
この式は一見複雑ですが、中身はとてもシンプルです。
「良い結果( 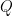

重要な専門用語をマスターしよう
この定理を支える2つの柱について、身近な例えで解説しますね。
1. 期待値(Expected Value)
期待値とは、何度も繰り返したときに平均してどれくらいの報酬が得られるか、という「見込み」のことです。
お祭りのくじ引きで、1等が出る確率と金額を掛け合わせて計算する「平均的にもらえる金額」をイメージしてください。AIはこの期待値を最大にすることを目指します。
2. 勾配(Gradient)
勾配とは、関数の値が最も急激に増える「方向」のことです。
霧の中、山の頂上を目指している自分を想像してください。足元の地面の傾き(勾配)を感じて、より高い方へ一歩踏み出しますよね。この「どっちが高いか」を教えてくれるのが勾配です。
勾配策定定理のメリットとデメリット
この手法は非常に強力ですが、完璧というわけではありません。
| 項目 | 内容 |
| メリット | 複雑な計算が必要な場面でも、シミュレーション(試行錯誤)の結果から直接学習できる。 |
| デメリット | 学習が不安定になりやすく、同じことをしても結果がバラつく「分散」が大きくなりやすい。 |
今後の学習の指針
勾配策定定理は、強化学習という分野の大きな扉です。ここから先、もっと詳しくなりたい方は以下のステップを進んでみてください。
- 基本的な強化学習の仕組み(報酬と罰)について学ぶ
- 「REINFORCEアルゴリズム」という、この定理を使った一番シンプルな手法を調べてみる
- 実際にAIがゲームを攻略する動画などを見て、学習の様子を観察する
AIが「次はこうしよう!」と自ら学習していく姿は、まるで生き物を見ているようで感動しますよ。
セイ・コンサルティング・グループでは新人エンジニア研修のアシスタント講師を募集しています。
投稿者プロフィール

