
機械学習の文字式・記号お約束のまとめ
 山崎講師
山崎講師こんにちは。ゆうせいです。
数式のアルファベットは怖くない!
数学の記号が並んでいるのを見ると、どうしても身構えてしまいませんか?
機械学習の世界には、まるでお約束のように何度も登場する文字があります。
これらの文字は、いわば機械学習というドラマの主要キャストです。
役柄さえ覚えてしまえば、複雑そうに見える数式も驚くほどスッキリ理解できるようになりますよ。
あなたは、コンピューターがどうやって物事を判断しているか不思議に思ったことはありませんか?
実は、今回ご紹介するアルファベットたちが、その判断の基準を支えているのです。
機械学習の主役たち
機械学習の学習ステップで頻繁に使われる、重要な文字について解説します。
1. 重みを表す w
機械学習において最も重要なのが w です。
これは Weight の頭文字で、日本語では「重み」と呼びます。
例えば、美味しいカレーを判定する AI を作ると想像してみてください。
具材の肉、野菜、スパイスのどれが味に大きな影響を与えるでしょうか?
スパイスが最も重要なら、スパイスという項目に大きな数値を掛け合わせます。
この「どの情報をどれくらい重視するか」という影響度の強さを表すのが w です。
2. バイアスを表す b
次に登場するのが b です。
これは Bias の頭文字で、日本語では「バイアス」や「切片」と表現されます。
重みの w が「こだわり」なら、b は「下駄を履かせる」ような調整役です。
どんなに具材が良くても、ベースとなる出汁がなければ味は決まりませんよね。
全体的な底上げや微調整を担うのが、この b の役割だと覚えてください。
3. 損失関数を表す L
忘れてはならないのが L です。
L は Loss(損失)を表すことが多く、
AI の予測と正解のズレを数値として表す関数です。
機械学習では、この L の値をできるだけ小さくすることが目的になります。
なお、統計学では L が Likelihood(尤度)を表すこともあります。
その場合は「データがどれくらいもっともらしいか」を示す値で、
機械学習ではこの尤度を最大化することが目標になります。
実際には、
損失 = − log(尤度)
という関係になることが多く、「損失を最小にする」ことと「尤度を最大にする」ことは対応しています。
4. 入力データを表す x
機械学習の主役の一人、それが x です。 これは数学でもおなじみですが、機械学習では「AIに教える材料」を指します。
例えば、家賃を予想する AI を作るとしましょう。 駅から徒歩何分か、部屋の広さはどれくらいか、築年数は何年か。 こうしたバラバラの情報をひとまとめにして x と呼びます。 材料がなければ料理ができないように、x がなければ AI は何も学習を始められません。
5. 正解のラベルを表す y
次に大切なのが y です。 これは「答え」や「ターゲット」を意味します。
先ほどの家賃予想なら、実際にその条件で貸し出されている「家賃の金額」そのものが y です。 AI は x (部屋の情報)を見て一生懸命に答えを出し、それが y (本当の家賃)と合っているかを答え合わせします。 学校のテストで、問題が x なら解答用紙の赤ペンが y だとイメージしてください。
6. 学習率を表す η(イータ)
少し特殊な記号として η(イータ)が登場することがあります。 これは「学習率」と呼ばれる、学習の歩幅を決める数値です。
AI が w (重み)を調整するとき、一気に大きく変えすぎると正解を通り過ぎてしまいます。 逆に、慎重になりすぎて少しずつしか変えないと、いつまで経っても学習が終わりません。 この「一歩の大きさ」をコントロールするのが η の役割です。 自転車のブレーキ加減や、アクセルの踏み込み具合を調整するようなものですね。
7. データの個数を表す n や m
機械学習では、膨大なデータを扱います。
その「データの総数」を表すのが n や m です。
Number(数)の頭文字と覚えると分かりやすいですよ。
例えば、1000人分の身長データを AI に学習させるとします。
このとき、データの数 

料理で言えば、「何人分の材料を用意するか」という全体量を指す数字ですね。
8. 予測値を表す y-hat(ワイ・ハット)
これは少し特殊な記号です。
文字の上に小さな山のような記号がついた 
読み方は「ワイ・ハット」。帽子をかぶっているみたいで可愛いですよね!
さきほど登場した y は「本当の正解」でした。
それに対して、この
テストで言えば、問題集の巻末にある答えが y で、あなたが答案用紙に書いた予想が
この2つの差が小さければ小さいほど、優秀な AI ということになります。
9. 特徴量の数を表す d
dは Dimension(次元)の頭文字で、データの「項目の数」を表します。
家賃予想の例で言えば、「広さ」「駅からの距離」「築年数」の3つの情報を使うなら、次元 
情報の種類が多ければ多いほど、この d の数字は大きくなっていきます。
10. 合計を表す Σ(シグマ)
数学の授業で見かけたことがあるかもしれませんが、機械学習では欠かせない存在です。 これは Sum(合計)の頭文字 S に対応するギリシャ文字です。
例えば、100人分のテストの点数の合計を出したいとき、一人ずつ足していく式を書くのは大変ですよね。 そんなとき、Σ を使えば「1番目から 100 番目まで全部足してね!」という命令を一文字で出せます。 AI が L (損失)を計算するとき、全データのズレを合計するためにこの記号がよく使われます。
11. データの集まりを表す X や Y(大文字)
これまでは小文字の x や y を見てきましたが、大文字の X や Y が出てくることもあります。 これは「行列(マトリックス)」といって、個別のデータではなく、データ全体の「表」を指します。
小文字の x が「一人の生徒の情報」なら、大文字の X は「クラス全員分の名簿」のようなイメージです。 機械学習では、一人ひとりを計算するよりも、クラス全員分をまとめて一気に計算する方が効率が良いのです。 そのため、数式ではドッシリとした大文字が主役になることが多いんですよ。
12. 関数を表す f や h
最後は f や h です。 これは Function(関数)や Hypothesis(仮説)の頭文字です。
AI は、入力 x を受け取って、何らかの計算をして予測値を出しますよね。 この「計算の仕組みそのもの」を f と呼びます。 自動販売機に例えると、お金(x)を入れてボタンを押すと、飲み物(予測値)が出てくる。 この「自動販売機の中のメカニズム」が f です。
13. 変化量を表す Δ(デルタ)
三角形の形をしたこの記号は、ギリシャ文字の Δ(デルタ)です。
数学や物理の世界では「変化した量」や「差分」を意味します。
例えば、AIが学習をして重み w を少しだけ書き換えたとします。
書き換える前の w と、書き換えた後の w の「差」が 
ダイエットで「体重が 3キロ減った」というときの「3キロ」にあたるのが、このデルタの役割ですね。
14. ほんの少しの動きを表す ∂(ラウンド・ディー)
これは少しおしゃれな形をしていますが、読み方は「ラウンド」や「デル」と呼びます。
「偏微分(へんびぶん)」という計算をするときに登場する記号です。
機械学習の目的は、L(間違い)を最小にすることでしたよね。
「w をほんの少し右に動かしたら、L はどれくらい減るかな?」という、ごくわずかな変化の影響力を調べるときにこの ∂ を使います。
山登りで、足元の傾斜を確かめながら一歩踏み出すような、慎重な動きを表現する記号だと考えてください。
15. 勾配(ベクトル)を表す ∇(ナブラ)
逆三角形の形をしたこの記号は、∇(ナブラ)といいます。
これは「勾配(こうばい)」、つまり坂道の向きと急さを表す記号です。
AIは、L(間違い)という谷の底を目指して進んでいきます。
「どの方向に進めば一番早く間違いが減るか?」というコンパスのような役割を果たすのが ∇ です。
この記号が出てきたら、「あ、AIが進むべき道を探しているんだな」と思って間違いありません!
16. データの番号を指定する i や j
数式の下の方に小さく書かれている i や j を見たことはありませんか?
これは「添え字(そえじ)」といって、データの「出席番号」のようなものです。
100人分のデータがあるとき、
i が 1 なら出席番号 1 番の人、2 なら 2 番の人。
このように、大量にあるデータの中から特定のひとつを指し示すための、大切な目印なのです。
17. 自然対数の底を表す e
機械学習、特に「分類(猫か犬か当てるなど)」の計算で突然現れるのが e です。
これは「ネイピア数」と呼ばれる特別な数字で、およそ 2.718... という決まった値を持っています。
なぜこんな中途半端な数字を使うのでしょうか?
実は e を使った計算(指数関数)は、AIが「確率」を計算するのにとっても都合が良いのです。
「これは 80% の確率で猫だ!」と AI が自信満々に答える裏側では、この e という数字が一生懸命働いています。
18. 合成関数を表す ∘(白丸)
たまに文字と文字の間に小さな白丸 
これは「合成(ごうせい)」を意味する記号です。
例えば、データを入れてから「計算 A」をして、その結果にさらに「計算 B」をさせるという流れがあるとします。
これをバラバラに書かずに、
ディープラーニングのように、何層もの計算を重ねる仕組みでは、この「セットメニュー」の書き方がよく使われます。
19. 誤差やノイズを表す ε(エプシロン)
数式の末尾にポツンと置かれている 
これは「誤差」や「ノイズ」を意味します。
現実の世界のデータは、完璧な直線や曲線には乗りません。
例えば、同じ広さの部屋でも、日当たりや大家さんの気分で家賃は微妙に変わりますよね。
AIが計算しきれない「どうしても発生してしまう小さなズレ」を、この ε が一手に引き受けてくれているのです。
完璧主義になりすぎない、心の余裕のような記号ですね。
20. パラメータをまとめる θ(シータ)
これまで w(重み)や b(バイアス)を個別に紹介してきましたが、これらをひとまとめにして 
AIが学習すべき「設定値」の総称だと考えてください。
テレビの画質調整で、明るさ、コントラスト、色合いなどを全部ひっくるめて「画質設定」と呼ぶのに似ています。
数式で
21. 分散や標準偏差を表す σ(シグマ)
大文字の Σ は「合計」でしたが、小文字の 
テストの平均点が 60 点だったとき、全員が 60 点に近いのか、0 点と 100 点に分かれているのかで意味が変わりますよね。
この「データの散らばり具合」を数値化したものが
AIがデータの個性を把握するために、このバラつき具合はとても重要な情報になります。
なぜ σ を使うのか?
では、なぜわざわざ σ という記号でバラつきを表すのでしょうか。
まず、「平均からどれだけ離れているか」を考えてみます。
それぞれの点数から平均を引いた値を 偏差 といいます。
しかし、この偏差をそのまま足し合わせると、
プラスとマイナスが打ち消し合って、必ず 0 になってしまいます。
そこで考えられたのが、偏差を2乗する 方法です。
(これを偏差平方といいます)
偏差を2乗してすべて足し合わせたものを
偏差平方和(Σ(x − μ)²)
といいます。
これをデータの個数で割ったものが 分散 です。
そして、その平方根をとったものが
標準偏差 σ になります。
つまり σ は、
「平均からどれくらい離れているか」を
打ち消し合わない形で測った指標なのです。
22. データの居場所を表す R(アール)
白抜き文字や太字で書かれた 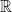
これは「実数全体の集合」を意味します。
機械学習のデータ(x や y)が、どんな範囲の数字なのかを示すために使われます。
例えば「x は
いわば、AIが活躍する「舞台の広さ」を決めている記号ですね。
23. 「定義する」を意味する :=(コロン・イコール)
普通の
これは「左辺を右辺の内容で定義する」という意味です。
数学的な「等しい」という状態ではなく、「今からこれをこう呼ぶことに決めた!」という宣言です。
例えば、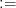

ルールブックの最初のページによく登場する、頼もしい記号ですね。
24. 最適な値を示す *(アスタリスク)

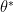
これは「最適値(オプティマル)」を意味します。
AIが一生懸命学習して、L(間違い)を最小にできた時の、いわば「正解の重み」です。
「ゴール地点の w」と言い換えてもいいでしょう。
数式の中にこの星を見つけたら、それは AI が目指すべき「理想の姿」を指しているんだと理解してください。
25. 「かつ」や「条件」を表す |(バー)
数式の途中にスッと引かれた縦棒 
これは「条件付き」であることを意味します。
例えば、確率の式などで「雨が降ったという条件(条件 A)のもとで、傘が売れる確率(事象 B)」を表現したいときに使います。
機械学習では「あるデータ x が与えられたときに、その正解が y である確率」といった具合に、背景情報を整理するために欠かせない記号です。
26. 「〜に従う」を意味する 〜(チルダ)
文字と文字の間に波線 
これは「このデータはある規則(分布)に従って現れるよ」という意味です。
例えば、サイコロを振ったときの出目や、人々の身長のバラつきなど、データには一定の「偏り」がありますよね。
「データ x は、正規分布というルールに従って発生している」ということを、この波線一文字で表現できるのです。
27. 転置を表す T(ティー)
文字の右上に小さく書かれた 
これは Transpose(転置)の頭文字です。
機械学習では、データの「縦」と「横」を入れ替えたい場面がよくあります。
例えば、横に並んだ具材リストを、縦に並べ替えて計算しやすくするようなイメージです。
数式の中で 
28. 近似を表す ≈ (アプロクシメイト)
≈(アプロクシメイト)は、「ほぼ等しい」という意味です。
現実の世界では、すべてをピッタリ同じにすることはほとんどありません。
そこで、「厳密に=ではないけれど、かなり近い」というときに ≈ を使います。
例えば、
π ≈ 3.14
というように、「正確にはもっと続くけれど、実用上はこのくらいで十分」という場面で登場します。
29. 分布を表す~(チルダ)
は「〜に従う」や「同じくらいの規模」という意味で使われます。
例えば、
x ~ N(0,1)
と書かれていたら、「x は平均0、分散1の正規分布に従う」という意味です。
また、
f(n) ~ n²
のように書かれていれば、「増え方がだいたい n² と同じくらい」という意味になります。
30. ノルム(大きさ)を表す ||(二重線)
文字を二重の縦棒で挟んだ 
これは「ノルム」と呼び、ベクトルの「長さ」や「大きさ」を意味します。
「重み w がどれくらい巨大になっているか?」を測るための物差しです。
AIが特定の情報にこだわりすぎて(重みが大きくなりすぎて)、極端な判断をしないように見張るときに使われます。
ダイエットで言うところの「ウエストのサイズ」を測って、太りすぎをチェックしているようなものですね。
31. 正則化の強さを決める λ(ラムダ)
ギリシャ文字の λ(ラムダ)は、機械学習では正則化の強さを表す係数としてよく使われます。
損失関数は次のように書かれます。
損失 = 誤差 + λ × 正則化項
λ が大きいほど、重みを小さく保つためのペナルティが強くなります。
その結果、
- モデルの重みが小さく抑えられる
- モデルが単純になる
- 過学習が起きにくくなる
という効果があります。
なお、数学では λ は固有値(eigenvalue)を表す記号としても使われますが、機械学習の正則化では「ペナルティの強さ」を意味します。
32. 確率分布のパラメータを表す α(アルファ)と β(ベータ)
これらはセットで登場することが多いです。
特に「ベイズ統計」という、AIに「自信のなさ」や「事前の知識」を持たせる手法でよく使われます。
例えば、AIが「このコインは表が出やすいはずだ」という事前の予想を持っているとき、その予想の強さを 

「AIの性格の初期設定」を決める値、とイメージしてください。
33. 報酬や減衰率を表す γ(ガンマ)
この記号は、主に「強化学習」という分野で主役級の活躍をします。
強化学習とは、ロボットが試行錯誤して歩き方を覚えるような学習方法です。

「目先の利益」を取るか「将来の大きな幸せ」を狙うか。そのバランスを司る、いわば「慎重さのパラメータ」ですね。
34. 行列を表す大文字の Φ(ファイ)と Ψ(プサイ)
小文字の 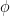

特に「デザイン行列」という名前で呼ばれ、計算の舞台装置として数式の中心にドッシリと構えていることが多いです。
これが出てきたら、「変身させたデータの集合体だな」と解釈しましょう。
35. 活性化関数を表す σ(シグマ)
小文字の
AIが「YESかNOか」を判断するとき、極端な判断を避けて「0から1の間」でなめらかに答えを出すためのフィルターのような役割です。
数式で 
36. 確率密度を表す π(パイ)

強化学習での
AIの「意思」そのものを表す、とっても重要な記号なんですよ。
37. 収束の度合いを表す ζ(ゼータ)や ξ(クサイ)
これらは少しマニアックですが、AIの学習がどれくらい「安定」しているか、あるいは「どれくらい目標からズレることを許容するか」を表すときに出てきます。
特に SVM(サポートベクターマシン)という手法では、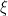
完璧主義になりすぎて学習が止まらないよう、ほどよく手を抜くための記号だとイメージしてください。
38. は「データの変身」を司る魔法使い
機械学習における
これだけ聞くと難しそうですが、要するに「データを計算しやすいように加工して、別の次元に飛ばす」という役割を持っています。
例えば、平面(2次元)にバラバラに置かれたデータがあって、どうしても一本の直線ではきれいに分類できないとしましょう。
そんなとき、
このように、元のデータ 
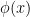
具体的な使われ方の例
1. 基底関数(きていかんすう)として
単純な直線ではなく、ぐにゃぐにゃと曲がった複雑なグラフ(曲線)を描きたいとき、元の
2. カーネル法
SVM(サポートベクターマシン)などの手法で、データを高次元の空間にマッピングする際に使われます。
3. ニューラルネットワークの層
ディープラーニングにおいて、ある層から次の層へデータが渡されるときの「加工」を表現する際にも
機械学習の文字式・記号お約束【まとめ】
| 記号カテゴリ | 記号 | 読み方 | 意味・役割 | 例え・イメージ |
| 基本の重み | w | ダブリュー | 重み (Weight) | どの情報を重視するかという「こだわり」 |
| b | ビー | バイアス (Bias) | 全体的な底上げをする「下駄」 | |
| データと正解 | x | エックス | 入力データ | AIに与える「料理の材料」 |
| y | ワイ | 正解ラベル | 教科書の巻末にある「正しい答え」 | |
| ŷ | ワイ・ハット | 予測値 | AIが一生懸命ひねり出した「予想」 | |
| X / Y | 大文字 | 行列(データの塊) | 一人分ではなく「クラス全員分の名簿」 | |
| 学習の評価 | L | エル | 損失関数 (Loss) | 正解とのズレ。これが小さいほど優秀! |
| η | イータ | 学習率 | 学習を進める時の「一歩の歩幅」 | |
| ε | エプシロン | 誤差・ノイズ | 避けられない「運や測定のズレ」 | |
| 数学的な操作 | Σ | シグマ | 合計 | バラバラの数値を「全部足す」命令 |
| Δ | デルタ | 変化量 | 前回の学習からの「成長した差分」 | |
| ∂ | ラウンド | 偏微分 | 坂道の「一歩先の傾斜」を調べる | |
| ∇ | ナブラ | 勾配 | 谷底(正解)へ向かう「コンパス」 | |
| T | ティー | 転置 | 行列を「縦横クルッと入れ替える」 | |
| ≈ | アプロクシメイト | ほぼ等しい(近似) | 「だいたい同じくらい」 | |
| ~ | チルダ | 〜に従う / 同程度 | 「このグループに属する」「このくらいの規模」 | |
| 個数と場所 | n / m | エヌ / エム | データの総数 | 用意した材料の「全体のボリューム」 |
| d | ディー | 特徴量の数 | データの「項目の種類(次元)」 | |
| i / j | アイ / ジェイ | 添え字 | データの「出席番号」 | |
| ℝ | アール | 実数全体 | AIが活躍する「無限の舞台」 | |
| 高度な加工 | φ | ファイ | 特徴写像 | データを別の次元へ飛ばす「変身魔法」 |
| σ | シグマ | 活性化関数 / 標準偏差 | 状況に応じて意味が変わる重要記号 | |
| ‖·‖ | ノルム | データの大きさ | データの「長さやウエストサイズ」 | |
| 特別な設定 | θ | シータ | パラメータ全体 | AIの「設定メニュー」の総称 |
| λ | ラムダ | 正則化係数 | 学習のしすぎを抑える「コーチの厳しさ」 | |
| γ | ガンマ | 割引率 | 「将来の価値」をどれだけ重視するか | |
| π | パイ | 方策 (Policy) | AIが次にどう動くかの「行動指針」 | |
| その他 | e | イー | ネイピア数 | 確率計算で大活躍する「不思議な定数」 |
| ξ | クサイ | スラック変数 | 「少しのミスなら許す」という余裕 | |
| w* | スター | 最適値 | 辿り着いた「ゴール地点の重み」 |
セイ・コンサルティング・グループでは新人エンジニア研修のアシスタント講師を募集しています。
投稿者プロフィール
- 代表取締役
-
セイ・コンサルティング・グループ株式会社代表取締役。
岐阜県出身。
海外放浪の末、2000年創業、2004年会社設立。
IT企業向け人材育成研修歴業界歴20年以上。
すべての無駄を省いた費用対効果の高い「筋肉質」な研修を提供します!
この記事に間違い等ありましたらぜひお知らせください。
学生時代は趣味と実益を兼ねてリゾートバイトにいそしむ。長野県白馬村に始まり、志賀高原でのスキーインストラクター、沖縄石垣島、北海道トマム。高じてオーストラリアのゴールドコーストでツアーガイドなど。現在は野菜作りにはまっている。
最新の投稿
 山崎講師2026年8月2日指数と対数は何が違うのか:逆の関係を理解する
山崎講師2026年8月2日指数と対数は何が違うのか:逆の関係を理解する- 山崎講師2026年8月2日自然対数eはどこから生まれたのか:歴史から理解する定数の意味
- 山崎講師2026年8月2日片側検定と両側検定の使い分け方を具体例から学ぶ
- 山崎講師2026年8月1日コンピューターが数値計算の誤差に対処する仕組みと精度管理の方法
