
Tanh(ハイパボリックタンジェント)関数
 山崎講師
山崎講師こんにちは。ゆうせいです。
ディープラーニングの世界へようこそ!AIが人間の脳のように学習する仕組み、ワクワクしませんか?
今日は、AIの頭脳の中で「情報の勢い」を調節する大切な部品、Tanh(ハイパボリックタンジェント)関数についてお話しします。
以前学んだかもしれないsigmoid関数と何が違うのか、どちらが優秀なのか、一緒に紐解いていきましょう!
AIのやる気スイッチ?活性化関数とは
ニューラルネットワークを理解する上で避けて通れないのが、活性化関数です。
これは、前の細胞から伝わってきた電気信号を、次の細胞にどれくらいの強さで伝えるかを決めるフィルターのような役割を担っています。
例えば、あなたが友達から「明日のテスト、めちゃくちゃ難しいらしいよ!」と聞いたとします。
その情報を聞いて、「よし、徹夜で勉強するぞ!」と気合を入れるのか、「まあ、なんとかなるでしょ」と受け流すのか。
この情報の変換処理を行っているのが活性化関数です。
Tanh関数の正体と計算式
Tanh関数は、日本語では正接(タンジェント)の親戚で、双曲線正接関数と呼ばれます。
この関数の最大の特徴は、出力される値が必ず -1 から 1 の間に収まるという点です。
ここで、計算式の形を確認してみましょう。
Tanh関数は、ネイピア数 
Tanh(x) = ( 
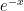
少し難しそうに見えますか?
要するに、どんなに大きな数字(ポジティブなニュース)が入力されても 1 に近づき、どんなに小さな数字(ネガティブなニュース)が入力されても -1 に近づく仕組みなのです。
Tanh関数の覚え方
■計算式は「引き算が上」
数式で迷ったら、分子(上側)に注目です。

「マイナスを作るために、上が引き算」と理屈で押さえるのが近道です。
また、この形から1よりも大きくなることはありません。
Sigmoid関数との決定的な違い
初心者の方が最初に出会う活性化関数は、おそらくSigmoid(シグモイド)関数でしょう。
では、Tanh関数とSigmoid関数は何が違うのでしょうか?
主な違いを以下の表にまとめました。
| 特徴 | Sigmoid関数 | Tanh関数 |
| 出力範囲 | 0 から 1 | -1 から 1 |
| 中心値 | 0.5 | 0 |
| データの偏り | 正の方向に偏りやすい | 0を中心にバランスが良い |
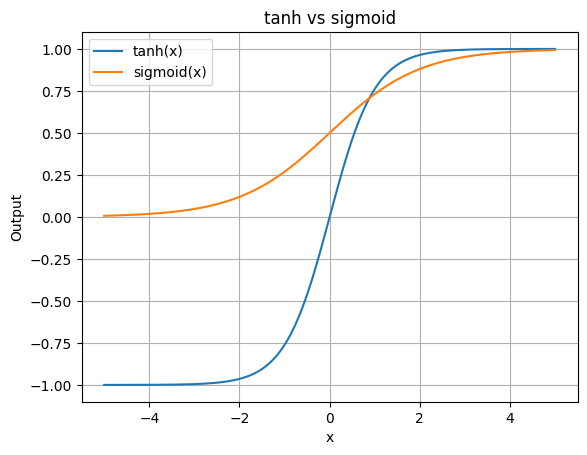
ゼロ中心であることのメリット
Tanh関数の最大の強みは、出力の平均が 0 に近い、つまり「ゼロ中心」であることです。
Sigmoid関数の場合、出力が常にプラス(0から1)なので、学習が進むにつれてデータの重みが一方向に偏ってしまう問題が発生しやすくなります。
想像してみてください。
常に「YES」か「たぶんYES」しか言わないYESマンばかりの会議よりも、「YES(1)」も「NO(-1)」もしっかり言える会議の方が、バランス良く正しい判断ができそうですよね?
これが、Tanh関数がSigmoid関数よりも学習がスムーズに進みやすい理由です。
Tanh関数のメリットとデメリット
どんなに便利な道具にも、良い面と悪い面があります。
メリット
- 学習の効率が良い:前述の通りゼロ中心であるため、ネットワーク全体の学習スピードがSigmoid関数よりも速くなる傾向があります。
- 表現力が豊か:マイナスの値を扱えるため、データの「負の側面」を直接次の層に伝えることができます。
デメリット
- 勾配消失問題:入力値が極端に大きかったり小さかったりすると、関数の傾きがほとんど 0 になってしまいます。これにより、AIが「これ以上何を学べばいいかわからない」とフリーズしてしまうことがあります。
- 計算コスト:指数関数
実際にどう使い分けるのか
あなたは今、「結局どっちを使えばいいの?」と思っているかもしれません。
現代のディープラーニングでは、隠れ層(ネットワークの中間部分)には ReLU関数 という別の関数が使われるのが一般的です。
しかし、データの値を一定の範囲にギュッと凝縮したい場合や、古いネットワークの改善、あるいは特定の時系列データを扱うモデル(RNNなど)では、今でも Tanh関数 が現役で活躍しています。
結論として、Sigmoid関数を使うくらいなら、まずは Tanh関数 を試してみるのがセオリーと言えるでしょう。
まとめと次のステップ
今回は Tanh関数 について学びました。
Sigmoid関数よりも出力のバランスが良く、学習を加速させてくれる頼もしい存在であることを理解していただけたでしょうか?
AIの世界は、こうした小さな部品の積み重ねでできています。
一つひとつの数式がどんな「役割」を持っているのかをイメージできるようになると、プログラミングもぐっと楽しくなりますよ!
今後の学習指針
- PythonとPyTorchやTensorFlowを使って、実際に Tanh関数 を動かしてみましょう。
- なぜ最近は Tanh関数 よりも ReLU関数 が好まれるのか、その理由を調べてみてください。
- 勾配消失問題という言葉を深掘りすると、ディープラーニングの歴史が見えてきます。
セイ・コンサルティング・グループでは新人エンジニア研修のアシスタント講師を募集しています。
投稿者プロフィール
- 代表取締役
-
セイ・コンサルティング・グループ株式会社代表取締役。
岐阜県出身。
海外放浪の末、2000年創業、2004年会社設立。
IT企業向け人材育成研修歴業界歴20年以上。
すべての無駄を省いた費用対効果の高い「筋肉質」な研修を提供します!
この記事に間違い等ありましたらぜひお知らせください。
学生時代は趣味と実益を兼ねてリゾートバイトにいそしむ。長野県白馬村に始まり、志賀高原でのスキーインストラクター、沖縄石垣島、北海道トマム。高じてオーストラリアのゴールドコーストでツアーガイドなど。現在は野菜作りにはまっている。
最新の投稿
 山崎講師2026年8月1日コンピューターが数値計算の誤差に対処する仕組みと精度管理の方法
山崎講師2026年8月1日コンピューターが数値計算の誤差に対処する仕組みと精度管理の方法- 山崎講師2026年8月1日0乗が1になる理由を2乗の計算式から解説する指数法則の基礎
- 山崎講師2026年8月1日機械学習モデルの予測理由を解釈するSHAPとシャープレイ値の基礎
- 山崎講師2026年8月1日適合率と再現率の概念と初心者向けのわかりやすい再翻訳案
