
f(x, y) とf(x; y) って何が違うの?
 山崎講師
山崎講師こんにちは。ゆうせいです。
数学や機械学習を学んでいると、似たような記号がたくさん出てきて頭が混乱してしまいますよね。特に、関数のカッコの中にあるカンマやセミコロンの使い分けは、パッと見では違いが分かりにくいものです。
「 

そんな疑問を抱いているあなたのために、今回はこの「数学の文法」をスッキリ整理して解説します。これが分かると、数式が何を伝えようとしているのか、その「意図」が読めるようになりますよ!
カンマとセミコロンの決定的な違い
結論からお伝えしましょう。この二つの違いは、登場人物たちの「役割分担」にあります。
:
と
は対等なライバル(変数)
セミコロンは、いわば「ここから先は裏方さんですよ」という区切り線なのです。
1. カンマでつながる F(x, y) の世界
これは普通の 2変数関数 です。例えば、 
ここでは、
2. セミコロンで区切る f(x; y) の世界
一方で、セミコロンが出てくると話が変わります。 
「今は
つまり、
機械学習でよく見る典型例:尤度と確率
この使い分けが最も威力を発揮するのが機械学習の世界です。特に混乱しやすい3つのパターンを整理してみましょう。
確率分布 p(x; θ)
これは「 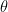
例えば、正規分布なら
尤度(ゆうど) L(θ; X)
「尤度」という言葉は日常では使いませんが、一言で言えば「もっともらしさ」のことです。先ほどの確率分布と式自体は同じなのですが、主役が入れ替わります。
: すでに手元にあるデータ(固定)
「データ
条件付き確率 p(y | x) との違い
ここで「縦棒( 
:
セミコロンは「関数の役割」を示すための記号ですが、縦棒は「条件」を示す論理的な記号です。機械学習では「原因
なぜ尤度は積分しても 1 にならないのか?
最後に、少し踏み込んだお話をしましょう。確率は全部足す(積分する)と 

それは、尤度が「分布」ではなく、ただの「スコア」だからです。
| 種類 | 式の形 | 何を動かす? | 積分した結果 |
| 確率 |  | データ | になる |
| 尤度 |  | 設定 | になるとは限らない |
確率は「起こりうるすべてのケース」を足し合わせるので
コイン投げで「表が出る確率 
まとめと今後の学習指針
いかがでしたか?セミコロン一つに、これほど深い「主役と脇役」のドラマが隠されていたのですね。
今回のポイントを復習しましょう。
- カンマは「みんな動く」対等な関係。
- セミコロンは「前が主役、後ろは固定」の合図。
- 機械学習では「最適化したいもの(動かしたいもの)」を前に書く。
今後は、新しい数式に出会ったとき、まず「セミコロンはどこにあるかな?」と探してみてください。それだけで、その数式が何を主役として扱っているのかが瞬時に見抜けるようになります。
次は、この知識を使って「最大尤度推定(最尤推定)」の具体的な計算にチャレンジしてみるのがおすすめです。主役である
セイ・コンサルティング・グループでは新人エンジニア研修のアシスタント講師を募集しています。
投稿者プロフィール
- 代表取締役
-
セイ・コンサルティング・グループ株式会社代表取締役。
岐阜県出身。
2000年創業、2004年会社設立。
IT企業向け人材育成研修歴業界歴20年以上。
すべての無駄を省いた費用対効果の高い「筋肉質」な研修を提供します!
この記事に間違い等ありましたらぜひお知らせください。
学生時代は趣味と実益を兼ねてリゾートバイトにいそしむ。長野県白馬村に始まり、志賀高原でのスキーインストラクター、沖縄石垣島、北海道トマム。高じてオーストラリアのゴールドコーストでツアーガイドなど。現在は野菜作りにはまっている。
最新の投稿
 新人エンジニア研修講師2026年6月22日ソリューション営業と御用聞き営業の違い|IT営業担当者が提案型営業へ成長するための考え方
新人エンジニア研修講師2026年6月22日ソリューション営業と御用聞き営業の違い|IT営業担当者が提案型営業へ成長するための考え方- 新人エンジニア研修講師2026年6月22日ITソリューション営業でよくある反論への対応方法|お金・時期・権限・必要性・不安を商談につなげる考え方
- 新人エンジニア研修講師2026年6月19日Spring BootでセッションIDがアドレスバーに表示される理由と対策|新人エンジニア向けにJSESSIONIDを解説
- 新人エンジニア研修講師2026年6月18日JavaのOptionalでnullを安全に扱う方法|NullPointerExceptionを防ぎ、DAOの戻り値をわかりやすくする
