
「なぜ分散は p(1-p) なのか?」数式の意味が直感でわかる!新人エンジニアのための確率統計教室
 山崎講師
山崎講師こんにちは。ゆうせいです。
前回の記事では、ベルヌーイ分布の確率の式が「実はただのスイッチだ」というお話をしました。
今回はその続き、少しレベルアップして「分散(ぶんさん)」の話をしましょう。
統計学の教科書を開くと、ベルヌーイ分布の分散の公式はこう書かれています。
非常にシンプルですよね。
でも、ふと疑問に思いませんか。
「なんで確率 
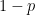
通常の分散の計算といえば、平均を引いて、二乗して、また平均して…と、もっと面倒な手順が必要なはずです。
実はこのシンプルな数式には、「予測のしにくさ」を表す深い意味が込められているのです。
今日は、この数式がなぜこうなるのか、そしてこの数式が何を物語っているのかを、数式アレルギーの方にもわかるように解説します。

そもそも「分散」って何だっけ?
数式に入る前に、言葉の定義をおさらいしておきましょう。
分散とは、データの「ばらつき具合」を表す指標です。
エンジニアの言葉で言えば、「結果の読めなさ」あるいは「ギャンブル性の高さ」と言い換えてもいいでしょう。
分散が大きい 
分散が小さい
これを頭の片隅に置いておいてください。
数式を解剖する(意外と簡単!)
では、なぜ 
数学的な証明は、実は驚くほどあっさりしています。
ここでは、「分散 
ついてきてくださいね。3ステップで終わります。
ステップ1:平均(期待値)を求める
ベルヌーイ分布は、確率 

平均値(期待値 ![E[X]](https://s0.wp.com/latex.php?latex=E%5BX%5D&bg=ffffff&fg=000&s=0&c=20201002)

つまり、平均は
ステップ2:2乗の平均を求める
ここがマジックの種明かしです。
分散を求めるために、出る数を「2乗」して平均を取ります。
でも考えてみてください。
そう、ベルヌーイ分布の世界では「2乗しても値が変わらない」のです!
だから、計算式はステップ1と全く同じになります。

「2乗の平均」も
ステップ3:公式に当てはめる
最後に、便利公式「(2乗の平均)

これを
はい、完成です!
あの面倒な分散の計算が、こんなにシンプルになる理由は、「0と1しか出ないから、2乗しても計算結果が変わらない」というベルヌーイ分布特有の性質のおかげだったのです。
エンジニアの直感で理解する「グラフの山」
数式の導出はわかりましたが、もっと大事なのは「意味」です。
この
二次関数のグラフをイメージしてみてください。

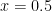
これを確率の話に戻しましょう。
ケースA:確率 

分散は「最大」になります。
これは直感と合っていますか?
半々の確率というのは、表が出るか裏が出るか、もっとも「予想がしにくい」状態ですよね。つまり、ばらつき(不確実性)がMAXなのです。
ケースB:確率 

分散は「小さく」なりました。
9割表が出るとわかっているなら、「次は表だろう」と予想しやすいですよね。つまり、ばらつきは小さいのです。
ケースC:確率 

分散は「ゼロ」です。
結果が完全に決まっているので、ばらつきようがありません。
いかがですか。
メリットとデメリット
この公式を理解しておくと、機械学習やデータ分析でどんな良いことがあるのでしょうか。
メリット
モデルの「自信」を測れる
機械学習の分類問題(例えば、この画像は猫か犬か)では、予測確率
このとき、 
計算コストが激安
平均値を引いて2乗して…というループ処理を回さなくても、確率
デメリット(注意点)
あくまで「2択」の世界限定
この公式が使えるのは、結果が0か1のときだけです。サイコロ(1〜6)のように値自体に大きさがある場合は使えません。
標準偏差と混同しやすい
分散は「2乗された単位」を持っています。実際のばらつきの幅を知りたいときは、ルート(平方根)をとって標準偏差 
今後の学習の指針
ベルヌーイ分布の分散
それは、「2乗しても変わらない」という数字のマジックと、「五分五分が一番読めない」という直感が組み合わさった、とても美しい数式でした。
もし現場で「このシステムのバグ発生率は 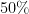
これからの学習の指針として、次は「ポアソン分布」の分散を調べてみてください。
なんと、ポアソン分布では「平均」と「分散」が全く同じ値になるという、さらに不思議な性質を持っています。
なぜそんなことが起きるのか、その謎解きもきっと面白いですよ。
それでは、また次回の講義でお会いしましょう!
セイ・コンサルティング・グループでは新人エンジニア研修のアシスタント講師を募集しています。
投稿者プロフィール
- 代表取締役
-
セイ・コンサルティング・グループ株式会社代表取締役。
岐阜県出身。
海外放浪の末、2000年創業、2004年会社設立。
IT企業向け人材育成研修歴業界歴20年以上。
すべての無駄を省いた費用対効果の高い「筋肉質」な研修を提供します!
この記事に間違い等ありましたらぜひお知らせください。
学生時代は趣味と実益を兼ねてリゾートバイトにいそしむ。長野県白馬村に始まり、志賀高原でのスキーインストラクター、沖縄石垣島、北海道トマム。高じてオーストラリアのゴールドコーストでツアーガイドなど。現在は野菜作りにはまっている。
最新の投稿
 山崎講師2026年8月2日匿名加工情報とは:最も保護レベルが低い情報形式を理解する
山崎講師2026年8月2日匿名加工情報とは:最も保護レベルが低い情報形式を理解する- 山崎講師2026年8月2日仮名加工情報の役割を理解する:個人情報から一歩進んだデータ活用
- 山崎講師2026年8月2日個人情報の種類を理解する:要配慮個人情報とは何か
- 山崎講師2026年8月2日オプトインとオプトアウト:Webサービスでの同意の仕組みを理解する
