
【初心者向け】条件分岐と自己参照をもつER図の読み解き方とは?
 山崎講師
山崎講師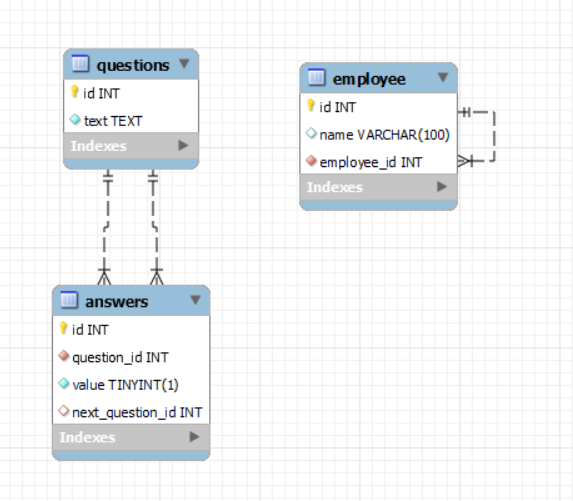
こんにちは。ゆうせいです。
今回は、上記のような少し変わったER図(エンティティ・リレーションシップ図)について、新人エンジニアの方にも分かりやすく丁寧に解説していきます。
このER図は、普通の「質問・回答」システムに見えますが、実は条件分岐(質問の流れが回答によって変わる)を取り扱う仕組みが隠れています。
はじめに、登場する3つのテーブルの役割から見ていきましょう!
各テーブルの役割と構造
1. questions テーブル(質問のリスト)
このテーブルは、すべての「質問文」を管理しています。
| カラム名 | データ型 | 説明 |
|---|---|---|
| id | INT | 質問の一意なID |
| text | TEXT | 質問の本文(テキスト) |
たとえば、「今の気分はどうですか?」のような質問がこのテーブルに保存されます。
2. answers テーブル(回答の記録と次の質問)
このテーブルが最も特徴的です。回答だけでなく、「次に進む質問のID」も保持しているのです!
| カラム名 | データ型 | 説明 |
|---|---|---|
| id | INT | 回答の一意なID |
| question_id | INT | この回答が属する質問のID(外部キー) |
| value | TINYINT(1) | 回答の選択肢(0 or 1など) |
| next_question_id | INT | この回答の後に表示される質問のID |
ポイント:この next_question_id によって、回答によって次の質問が変わるという分岐ロジックが実現されています。
例え話:
質問:「朝ごはんは食べましたか?」
- はい(value = 1)→ 「何を食べましたか?」(ID=5)
- いいえ(value = 0)→ 「なぜ食べなかったのですか?」(ID=6)
このように、answers テーブルの next_question_id により、ストーリーが分岐していく構造です。
自己参照(Self-Reference)とは?
「あるテーブルが、自分自身を参照している状態」のことです。
つまり、同じテーブルの中の1つの行が、別の行を指している、という構造です。
「えっ、自分で自分を参照するの?」と少し混乱するかもしれませんが、心配いりません。身近な例を交えて分かりやすく説明していきます!
自己参照の代表的な例
1. 上司と部下の関係(社員テーブル)
たとえば「従業員(employee)」というテーブルに、次のようなカラムがあったとしましょう。
| id | name | manager_id |
|---|---|---|
| 1 | 佐藤 | NULL |
| 2 | 鈴木 | 1 |
| 3 | 高橋 | 1 |
この場合、manager_id が同じ employee.id を参照していることになります。
つまり:
- 佐藤さん(id=1)が、鈴木さんと高橋さんの上司。
manager_idは「上司のID」を指していて、同じテーブルのID列とつながっている。
これが「自己参照」です。
質問フロー(今回のER図)
添付のER図では、answers テーブルの next_question_id が questions.id を参照しています。
このように、違うテーブルを参照しているように見えても、参照先が同じ役割(質問)を持つなら、それも実質「自己参照的」です。
図にすると、以下のようになります:
<answers>
| id | question_id | value | next_question_id |
| 1 | 1 | 0 | 3 |
| 2 | 1 | 1 | 2 |
<questions>
| id | text |
| 1 | 朝食を食べた? |
| 2 | 何を食べた? |
| 3 | なぜ食べなかった? |
ここで next_question_id が questions.id を参照することで、回答によって次の質問が変わる、という分岐構造が可能になります。
自己参照を使うメリット・デメリット
メリット
- 柔軟な階層構造やフロー設計ができる
- 例:組織図、コメントのスレッド構造、条件分岐フロー
- テーブルの数を増やさず、1つのテーブル内で完結する
デメリット
- SQLのクエリが少し複雑
- 親を取得したり、子をたどったりするのに
JOINが必要
- 親を取得したり、子をたどったりするのに
- 自己参照が多重になると混乱しやすい
- 再帰的な構造になると、表示やロジックの管理が難しい
SQLでの自己参照の書き方(例)
上司と部下の名前を一覧にするSQL
SELECT
e1.name AS employee_name,
e2.name AS manager_name
FROM
employee e1
LEFT JOIN
employee e2 ON e1.manager_id = e2.id;
解説:
employeeテーブルを2回使って、自分自身をJOINしています。e1:部下の側、e2:上司の側。- こうすることで、1つのテーブルで親子関係を表現できるのです。
まとめ:自己参照は「関係性を表現する武器」
自己参照は一見複雑に思えますが、「同じ種類のデータ同士に関係がある」という場面では非常に強力です。
たとえば:
- フォルダとサブフォルダ
- 上司と部下
- コメントと返信
- 質問と次の質問(今回のケース)
次に学ぶべきテーマ
自己参照が理解できたら、次のステップとして以下を学ぶとよいでしょう。
- 再帰SQL(Common Table Expressions:CTE)
- 階層構造データの表示ロジック
- Graph構造とツリー構造の違い
- NoSQLとの比較(特にツリー構造に強い)
セイ・コンサルティング・グループの新人エンジニア研修のメニューへのリンク
投稿者プロフィール
- 代表取締役
-
セイ・コンサルティング・グループ株式会社代表取締役。
岐阜県出身。
海外放浪の末、2000年創業、2004年会社設立。
IT企業向け人材育成研修歴業界歴20年以上。
すべての無駄を省いた費用対効果の高い「筋肉質」な研修を提供します!
この記事に間違い等ありましたらぜひお知らせください。
学生時代は趣味と実益を兼ねてリゾートバイトにいそしむ。長野県白馬村に始まり、志賀高原でのスキーインストラクター、沖縄石垣島、北海道トマム。高じてオーストラリアのゴールドコーストでツアーガイドなど。現在は野菜作りにはまっている。

