
【初心者必見】情報の「驚き」を数値化する?平均情報量とエントロピーの基礎を完全攻略
 山崎講師
山崎講師こんにちは。ゆうせいです。
みなさんは、普段扱っている「情報」に重さや大きさがあると考えたことはありますか。ファイルサイズのバイト数のことではありません。情報そのものが持つ「意味の大きさ」のことです。
たとえば、「明日は朝が来るでしょう」と言われたときと、「明日は隕石が落ちてくるでしょう」と言われたとき、どちらが驚きますか。間違いなく後者ですよね。私たちは、珍しい出来事ほど「情報としての価値が高い」と直感的に感じています。
今日は、そんなふんわりとした「驚き」や「あいまいさ」を、数学の力でカッチリと数字にする方法を学びましょう。新人エンジニアのみなさんが機械学習やデータ分析の世界へ足を踏み入れるとき、この知識は強力な武器になりますよ。
数学アレルギーの方も安心してください。高校生でもわかるように、じっくりと紐解いていきます。
情報量とエントロピーってなに
まずは基本となる 平均情報量 という言葉から入ります。これは別名 エントロピー とも呼ばれます。
エントロピーを一言で表すなら、物事の「予測のしにくさ」や「不確実性」を測る尺度 です。ある事象Xが起こったと分かった時に得られる情報量の期待値です。
想像してみてください。あなたは今、コイン投げをしています。
表と裏が出る確率はそれぞれ50パーセントですね。このとき、どちらが出るかは投げてみないとわかりません。つまり、結果はとてもあいまいで、予測がつきにくい状態です。この状態を「エントロピーが高い」と言います。
一方で、両面とも「表」のイカサマコインがあったとしましょう。
これなら投げる前から結果は「表」だとわかっていますよね。予測が完璧にできるため、驚きはゼロです。この状態を「エントロピーが低い(ゼロ)」と言います。
これを数式で表してみましょう。少し記号が出てきますが、逃げないでくださいね。
ある事象のエントロピー 

エントロピー

ここで登場する 

なぜ 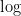
これは、情報を「はい」か「いいえ」の2択で質問して特定するゲームに似ているからです。答えにたどり着くまでに必要な質問の回数の平均値、それがエントロピーの正体だと思ってください。
2つの出来事を同時に考える同時エントロピー
では次に、2つのことが同時に起こる場合を考えてみましょう。これを 同時エントロピー と呼びます。
たとえば、「今日の天気」という事象 

数式ではこのように表します。
同時エントロピー

少し複雑に見えますが、やっていることは単純です。「天気」と「電車」のすべての組み合わせ(晴れで遅延なし、雨で遅延あり、など)について、その確率と驚き具合を計算して合計しているだけなのです。
もし、この2つの事象がまったく無関係なら、それぞれの単独のエントロピーを足し算すれば同時エントロピーになります。
しかし、現実世界では「雨が降ると電車が遅れやすい」といった関係性があることが多いですよね。そのため、単純な足し算よりも少し値が小さくなることがあります。情報が重複しているからです。
片方がわかるとどうなる条件付きエントロピー
ここからが面白いところです。もし、片方の情報がすでにわかっていたら、もう片方の予測のしにくさはどう変わるでしょうか。
これを表すのが 条件付きエントロピー です。
先ほどの例で、「今日は大雨だ」ということがわかったとしましょう。
すると、「電車が遅れるかどうか」の予測は、何も知らないときより少し立てやすくなりませんか。「きっと遅れるだろうな」と予想がつきますよね。
つまり、ある情報
数式での表現を見てみましょう。
条件付きエントロピー
または、確率を使って定義通りに書くとこうなります。
条件付きエントロピー

この式が教えてくれるのは、「ヒントをもらった後の残りの謎の量」です。
もし
逆に、全く無関係なら、ヒントは何の役にも立たないので、エントロピーは減りません。
練習問題の設定:エラーログを分析せよ
あなたはサーバー管理者として、システムのエラーログを分析しています。
発生したエラーには、エラーの種類(
過去のデータを集計したところ、それぞれの組み合わせでエラーが発生する確率(同時確率)は以下の表のようになりました。
| 種類 latexX \ サーバー latexY | サーバーA | サーバーB |
| ネットワークエラー | 1/8 (12.5%) | 1/8 (12.5%) |
| データベースエラー | 1/4 (25.0%) | 1/2 (50.0%) |
この表を見てわかるように、サーバーBでデータベースエラーが起きる確率が一番高い(全体の半分)ですね。
では、この状況をエントロピーを使って分析してみましょう。
問題1:エラーの種類だけを見たときのエントロピーは?
まずは、発生したサーバーのことは忘れて、「エラーの種類
「ネットワークエラー」と「データベースエラー」、それぞれの発生確率を求めてから、エラー種類
問題2:種類とサーバー、両方を考慮した同時エントロピーは?
次に、表の中の4つの事象(マスの確率)をすべて使って、同時エントロピー 
問題3:エラーの種類がわかった後の条件付きエントロピーは?
最後に、条件付きエントロピー 
「エラーの種類
ヒント:前回紹介した引き算の公式 
解答と解説
計算お疲れさまでした。数字が合っているかどうかよりも、計算の過程で「確率が低いほど値が大きくなるんだな」といった感覚を掴むことが大切です。それでは解説していきます。
問題1の解説: の計算
まず、それぞれの行の合計を計算して、
ネットワークエラーの確率 

データベースエラーの確率 

この2つの確率を使ってエントロピーを計算します。
情報量の計算式は 
ネットワーク部分:

データベース部分:


合計:

答えは 約0.815ビット です。
もし両方のエラーが半々(50%ずつ)ならエントロピーは最大値の「1」になりますが、今回はデータベースエラーに偏っているため、1より少し小さい値になりました。「少し予想しやすい」ということです。
問題2の解説: の計算
同時エントロピーは、表の中の4つの確率をそれぞれ計算して足し合わせます。
- ネット・A (確率
):
- ネット・B (確率
- DB・A (確率
):
- DB・B (確率
):



これらをすべて合計します。

答えは 1.75ビット です。
問題3の解説: の計算
定義通りに条件付き確率から計算する方法もありますが、ここでは前回学んだ便利な関係式を使います。
これに先ほど求めた値を代入するだけです。

答えは 約0.935ビット です。
この数字は何を意味しているのでしょうか。
もしエラーの種類が何もわかっていない状態で「どのサーバーで起きたか?」を当てようとすると、サーバーのエントロピー 

しかし、「エラーの種類」というヒントをもらうことで、不確実性がほんの少しだけ減りました。
「えっ、0.95から0.935って、ほとんど減ってないじゃないか!」と思いましたか。鋭いですね。
実は今回のデータでは、ネットワークエラーならAとBが半々、データベースエラーでもAとBの比率は1:2程度です。「エラーの種類がわかっても、どっちのサーバーか結局よくわからない(決定打にならない)」という状況なのです。だからエントロピーがあまり減らなかったんですね。
これがもし「ネットワークエラーは必ずサーバーAで起きる」という状況なら、もっと劇的に値が下がります。
練習問題のまとめ
計算を通じて、エントロピーの正体が少し見えてきたでしょうか。
- 確率は偏っているほどエントロピー(予測のしにくさ)は下がる
- ヒント(条件)と結果に関連性が薄いと、条件付きエントロピーはあまり下がらない
この感覚を持っておくと、機械学習で「どのデータを使えば精度が上がるか」を考えるときに、「エントロピーを大きく下げるような(=情報利得が大きい)特徴量を探そう」という発想ができるようになります。
この理論を学ぶメリットとデメリット
ここまで見てきて、「なんでこんな面倒な計算をするの」と思ったかもしれません。実務におけるメリットとデメリットを整理しましょう。
メリット
最大のメリットは、「情報の価値」を客観的な数値で比較できることです。
例えば、機械学習の「決定木」という手法では、データを分類するときに「どの質問(特徴量)を使えば一番効率よく分けられるか」を判断するために、このエントロピーの概念を使います。
「年齢で分けるべきか、性別で分けるべきか」と迷ったとき、エントロピーがより小さくなる(=不確実性が減る)方を選べば良いのです。あやふやな勘に頼らず、論理的にモデルを構築できるようになります。
デメリット
一方で、デメリットは直感的な理解が難しく、計算コストがかかることです。
今後の学習の指針
いかがでしたでしょうか。
「情報」という目に見えないものを、「確率」と「対数」を使って測量する感覚がなんとなく掴めたなら大成功です。
今日学んだエントロピーは、情報理論の入り口に過ぎません。ですが、ここさえ押さえておけば、AIやデータサイエンスの専門書を読んだときに、「あ、これはあの時の不確実性の話だな」と点と点がつながる瞬間が必ず来ます。
次は、実際にこのエントロピーを使ってデータを綺麗に分類する手法、「決定木分析」や「情報利得(インフォメーション・ゲイン)」について調べてみてください。今日の知識がそのままコードを書く力に変わりますよ。
セイ・コンサルティング・グループでは新人エンジニア研修のアシスタント講師を募集しています。
投稿者プロフィール
- 代表取締役
-
セイ・コンサルティング・グループ株式会社代表取締役。
岐阜県出身。
海外放浪の末、2000年創業、2004年会社設立。
IT企業向け人材育成研修歴業界歴20年以上。
すべての無駄を省いた費用対効果の高い「筋肉質」な研修を提供します!
この記事に間違い等ありましたらぜひお知らせください。
学生時代は趣味と実益を兼ねてリゾートバイトにいそしむ。長野県白馬村に始まり、志賀高原でのスキーインストラクター、沖縄石垣島、北海道トマム。高じてオーストラリアのゴールドコーストでツアーガイドなど。現在は野菜作りにはまっている。

