
【Python実践】ワインの味を「2つの数字」で表現?scikit-learnで主成分分析(PCA)をやってみよう
 山崎講師
山崎講師こんにちは。ゆうせいです。
前回は、主成分分析(PCA)のことを「データの写真撮影」に例えて解説しました。
「情報をなるべく落とさずに、ベストな角度からパシャリと撮って、次元を減らす」
このイメージ、なんとなく掴んでいただけたでしょうか。
今回は、いよいよ実践編です。
Pythonの機械学習ライブラリ「scikit-learn(サイキット・ラーン)」を使って、実際に主成分分析を行うプログラムを書いてみましょう。
題材にするのは、データ分析の勉強で必ずと言っていいほど登場する有名な 「ワインデータセット」 です。
アルコール度数や色味など、13種類もの成分データを持つワインたちを、たった「2つの数値」に要約して、その特徴を可視化してみます。
プログラミング初心者の方も、コピペして動かせるコードを用意しましたので、ぜひ一緒に手を動かしてみてください。
今回扱うデータ:ワインデータセット
scikit-learnには、練習用のデータセットがいくつか内蔵されています。その一つがワインデータセットです。
ここには、3種類の異なるワイン(ラベル0, 1, 2)について、以下の13個の特徴が記録されています。
- アルコール度数
- リンゴ酸
- 灰分
- (中略)
- 色の濃さ
- 色相...などなど。
つまり、このデータは 「13次元」 の空間に広がっています。
私たち人間は、13次元のグラフを描くことも、想像することもできませんよね。
そこでPCAの出番です。この13個の数字を、ギュギュッと 「2個(第1主成分と第2主成分)」 に圧縮して、散布図として描けるようにしましょう。
実装の前に:一番大事な「前処理」
コードを書く前に、一つだけ絶対に覚えておいてほしい注意点があります。
それは、 「標準化(スケーリング)」 という作業です。
ワインのデータを見てみると、
- アルコール度数: 13.0 くらい
- プロリン(アミノ酸の一種): 1000.0 くらい
と、桁が全然違います。
もしこのままPCAにかけると、数値が桁違いに大きい「プロリン」の影響力が強すぎて、アルコール度数などの小さな変化が無視されてしまいます。
これを防ぐために、すべての項目を 「平均 0 、分散 1」 に揃える処理(標準化)が必須なのです。
数式で書くとこうなります。
変換後の値 


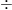

Pythonによる実装コード
それでは、コードを見ていきましょう。
やっていることはシンプルで、「データを読み込む」→「標準化する」→「PCAで圧縮する」→「グラフにする」の4ステップです。
Google Colabなどの環境に貼り付けて実行してみてください。
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_wine
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
# 1. データの読み込み
wine = load_wine()
# わかりやすくするためにDataFrame形式にします
df = pd.DataFrame(wine.data, columns=wine.feature_names)
# 正解ラベル(0:品種A, 1:品種B, 2:品種C)
labels = wine.target
print("--- 元のデータの大きさ ---")
print(df.shape)
# 出力例: (178, 13) -> 178本のワイン、13個の特徴量
# 2. データの標準化(超重要!)
# 平均0, 分散1になるように変換します
scaler = StandardScaler()
df_scaled = scaler.fit_transform(df)
# 3. PCA(主成分分析)の実行
# 13次元を「2次元」に圧縮するように設定
pca = PCA(n_components=2)
X_pca = pca.fit_transform(df_scaled)
print("\n--- 圧縮後のデータの大きさ ---")
print(X_pca.shape)
# 出力例: (178, 2) -> 13個あった特徴が2個になった!
# 4. 結果の可視化
plt.figure(figsize=(8, 6))
# 品種ごとに色を変えて散布図を描く
colors = ['red', 'blue', 'green']
for i in range(3):
plt.scatter(X_pca[labels == i, 0], # 第1主成分(横軸)
X_pca[labels == i, 1], # 第2主成分(縦軸)
c=colors[i],
label=f'Class {i}')
plt.xlabel('PC1') # 第1主成分
plt.ylabel('PC2') # 第2主成分
plt.title('PCA of Wine Dataset')
plt.legend()
plt.grid()
plt.show()
# おまけ:どれくらい情報を維持できたか(寄与率)を確認
print("\n--- 情報の維持率(寄与率) ---")
print(pca.explained_variance_ratio_)
print(f"合計: {sum(pca.explained_variance_ratio_):.2f}")
結果の解説
実行すると、赤・青・緑の3色の点がきれいに分かれた散布図が表示されたはずです。
1. グラフからわかること
たった2つの軸(PC1, PC2)を見るだけで、3種類のワインがそれぞれ別の場所に固まっていることがわかります。
これは、13個の成分をうまく要約できた証拠です。「成分分析の結果、これらは明らかに違うタイプのワインだ」と一目で言えるようになったわけです。
2. 寄与率(きよりつ)の意味
コードの最後に表示された「寄与率」を見てください。
例えば [0.36..., 0.19...] のようになっていれば、合計で約0.55(55%)です。
これは、「元の13次元が持っていた情報の55%を、この2次元だけで表現できています」 という意味です。
逆に言えば、45%の情報は捨てられました。それでも、グラフであれだけきれいに分類できているなら、この要約は大成功と言えるでしょう。
今後の学習の指針
いかがでしたでしょうか。
「13個の数字の羅列」だったデータが、PCAを通すことで「目に見える地図」に変わる瞬間、ワクワクしませんか。
今回はデータの可視化に使いましたが、この圧縮されたデータ(X_pca)をそのままAIの学習データとして使えば、計算が高速になったり、過学習を防いだりする効果も期待できます。
さて、ここまで「教師なし学習(PCA)」について学んできましたが、データ分析にはもう一つ重要なアプローチがあります。
それは、データをグループ分けする 「クラスタリング(k-means法など)」 です。
今回のPCAのグラフでも、データが自然と3つの塊になっていましたよね。あれをAIに自動で見つけさせる技術です。
セイ・コンサルティング・グループでは新人エンジニア研修のアシスタント講師を募集しています。
投稿者プロフィール
- 代表取締役
-
セイ・コンサルティング・グループ株式会社代表取締役。
岐阜県出身。
海外放浪の末、2000年創業、2004年会社設立。
IT企業向け人材育成研修歴業界歴20年以上。
すべての無駄を省いた費用対効果の高い「筋肉質」な研修を提供します!
この記事に間違い等ありましたらぜひお知らせください。
学生時代は趣味と実益を兼ねてリゾートバイトにいそしむ。長野県白馬村に始まり、志賀高原でのスキーインストラクター、沖縄石垣島、北海道トマム。高じてオーストラリアのゴールドコーストでツアーガイドなど。現在は野菜作りにはまっている。

