
データ分析の効率が劇的に変わる!NumPyの初心者でも一歩踏み出せる!データの「ご近所さん」から答えを導くK近傍法の応用術
 山崎講師
山崎講師こんにちは。ゆうせいです。
データ分析の世界へようこそ!今日は、機械学習の中でも直感的で分かりやすい手法の一つ、K近傍法(けいきんぼうほう)についてお話しします。
皆さんは、新しい街に引っ越したとき、どこのスーパーが安いか知りたくなったらどうしますか?おそらく、近所に住んでいる数人に話を聞いてみるのではないでしょうか。実は、K近傍法の考え方はこれと全く同じです。
K近傍法とは何か?
K近傍法は、英語で K-Nearest Neighbor と呼ばれます。略して KNN と表現されることも多いですね。
この手法を高校生にも分かるように例えるなら、クラスメイトの好みを当てるクイズのようなものです。例えば、ある生徒が「きのこの山」派か「たけのこの里」派かを知りたいとします。その生徒の近くに座っている5人にアンケートを取り、3人が「たけのこ」と言えば、その生徒も「たけのこ」派だと予測します。
この「近くの5人」の「5」にあたる数字を、専門用語で k と呼びます。
重要なキーワード:距離の計算
データの世界で「近い」かどうかを判断するには、ものさしが必要です。ここで使われるのが、ユークリッド距離という概念です。
数式で表すと少し難しく感じるかもしれませんが、安心してください。基本はピタゴラスの定理です。2つのデータの差を計算する際、以下のような形に整えます。
距離 

このように、それぞれの要素の差を2乗して足し合わせ、ルートをつけることで、データ同士の直線距離を導き出します。
K近傍法が活躍する具体的なシーン
このシンプルな仕組みは、私たちの身の回りでどのように役立っているのでしょうか。代表的な応用例を見ていきましょう。
1. レコメンドシステム
ショッピングサイトで「この商品を買った人はこんな商品も見ています」という表示を目にしたことはありませんか?これは、あなたの購買傾向と似ているユーザーを「ご近所さん」として探し出し、その人たちが選んでいるものを提案しているのです。
2. 手書き文字の認識
郵便番号の読み取りなど、画像の中にある数字を判別する際にも使われます。未知の数字データが入力されたとき、過去の膨大なデータの中から、形が最も似ている(=距離が近い)数字を特定し、これは 7 です、と判断を下します。
K近傍法のメリットとデメリット
どんなに優れた手法にも、得意と苦手があります。
メリット
- 仕組みが単純明快:アルゴリズムの構造がシンプルなので、なぜその結果になったのかを人間に説明しやすいのが特徴です。
- 事前の学習が不要:データが与えられてから計算を始めるため、複雑な準備が必要ありません。
デメリット
- 計算に時間がかかる:データ量が増えれば増えるほど、全てのデータとの距離を計算し直さなければならないため、動作が重くなります。
- 外れ値に弱い:たまたま近くに特殊なデータ(ノイズ)が紛れ込んでいると、予測が大きく外れてしまうことがあります。
ここで皆さんに質問です。もしクラス全員の意見を聞こうとしたら、計算はどうなるでしょうか?膨大な時間がかかってしまいますよね。だからこそ、適切な k の値を選ぶことが非常に重要になるのです。
K近傍法のバリエーションと注意点
標準的な手法以外にも、工夫を凝らした応用形が存在します。
重み付きK近傍法
単純な多数決ではなく、より距離が近いデータの意見を重視する方法です。
重み 
このように計算することで、遠くの親戚より近くの他人、といった具合に、距離に反比例した影響力を与えることができます。
データの正規化
K近傍法を使う上で絶対に忘れてはいけないのが、単位の統一です。例えば、身長(cm)と体重(kg)を同じグラフに並べると、数値の大きい身長の方が距離に与える影響が強くなってしまいます。
そこで、データの値を 

Pythonで実装
Pythonの標準的なライブラリである scikit-learn を使って、K近傍法がどのようにデータを分類しているのかを可視化してみましょう。
準備するもの
まずは、グラフを描くためのライブラリを準備してください。
- numpy:数値計算を効率よく行うための道具です。
- matplotlib:グラフを描画するためのメインツールです。
- scikit-learn:機械学習のアルゴリズムが詰まった宝箱です。
可視化のプログラムコード
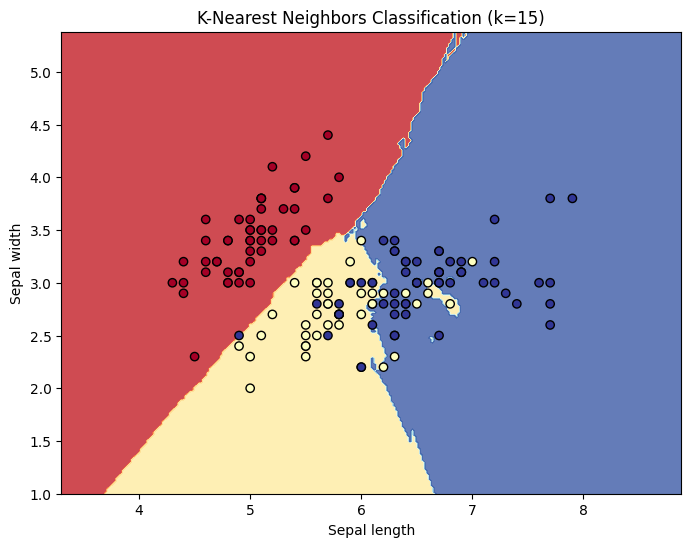
以下のコードをコピーして実行してみてください。アヤメの花のデータセット(Iris dataset)を使って、3つの種類をどのように色分けするかを表示します。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import load_iris
# データの読み込み
iris = load_iris()
# 2つの特徴量(がくの長さと幅)だけを取り出します
X = iris.data[:, :2]
y = iris.target
# K近傍法のモデルを作成(k=15とします)
k = 15
clf = KNeighborsClassifier(n_neighbors=k)
clf.fit(X, y)
# 描画範囲を決定するためのメッシュグリッドを作成
h = .02
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
# 領域全体の予測を行います
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
# グラフの描画
plt.figure(figsize=(8, 6))
plt.contourf(xx, yy, Z, alpha=0.8, cmap=plt.cm.RdYlBu)
plt.scatter(X[:, 0], X[:, 1], c=y, edgecolors='k', cmap=plt.cm.RdYlBu)
plt.xlabel('Sepal length')
plt.ylabel('Sepal width')
plt.title(f'K-Nearest Neighbors Classification (k={k})')
plt.show()コードの注目ポイント
1. KNeighborsClassifier の設定
ここで 
2. メッシュグリッド(網の目)
np.meshgrid という命令を使っています。これは、グラフ上のあらゆる地点に対して「ここは何色(どの種類)に分類されるか?」を計算させるための、細かい網の目を作る作業です。
3. predict メソッド
学習したモデルにデータを渡し、答えを予測させています。
予測 clf.predict(データ)
この一文字で、先ほど説明した「距離の計算」を裏側で一瞬にして終わらせてくれるのです!
グラフを見て考えてみよう
実行すると、色が綺麗に分かれた地図のようなグラフが表示されたはずです。この「色の境界線」を専門用語で決定境界(けっていきょうかい)と呼びます。
ここで皆さんに試してほしいことがあります!
コード内の k = 15 という数字を k = 1 に変えて再実行してみてください。境界線がガタガタになりませんでしたか?
逆に k = 100 など大きな数字にするとどうなるでしょうか。境界線がなめらかになりすぎて、大雑把な分類になってしまいますよね。
このように、パラメータを調整して「ちょうど良い塩梅」を見つける作業をチューニングと呼びます。
まとめと今後の学習指針
K近傍法は、データ分析の第一歩として非常に優れた手法です。まずは以下のステップで学習を進めてみてはいかがでしょうか。
- まずは小さなデータセットで、手計算をして距離を求めてみる。
- プログラミング言語のPythonなどを使って、実際に予測モデルを動かしてみる。
- k の値を変えることで、予測結果がどう変化するかを観察する。
身近な「似ているもの探し」から、データサイエンスの奥深い世界へと足を踏み入れてみてください。
セイ・コンサルティング・グループでは新人エンジニア研修のアシスタント講師を募集しています。
投稿者プロフィール
- 代表取締役
-
セイ・コンサルティング・グループ株式会社代表取締役。
岐阜県出身。
海外放浪の末、2000年創業、2004年会社設立。
IT企業向け人材育成研修歴業界歴20年以上。
すべての無駄を省いた費用対効果の高い「筋肉質」な研修を提供します!
この記事に間違い等ありましたらぜひお知らせください。
学生時代は趣味と実益を兼ねてリゾートバイトにいそしむ。長野県白馬村に始まり、志賀高原でのスキーインストラクター、沖縄石垣島、北海道トマム。高じてオーストラリアのゴールドコーストでツアーガイドなど。現在は野菜作りにはまっている。

