
初心者のためのNormalization(正規化)入門!AIの学習をスムーズにする魔法の調整役
 山崎講師
山崎講師こんにちは。ゆうせいです。
みなさんは、AIが学習する際、データの中に極端な数字が混ざっていると、途端に機嫌を損ねてしまうことを知っていますか。例えば、あるデータは1から10までの範囲なのに、別のデータが0から1,000,000という巨大な数字だった場合、AIは混乱してしまいます。
そこで登場するのが、Normalization層、日本語で「正規化層」と呼ばれる技術です。今回は、AIが効率よく賢くなるための必須テクニックを、世界一分かりやすく解説します。準備はいいですか。
Normalization層とは?データの個性を活かしたまま整列させる技術
Normalization層の役割を一言で言えば、バラバラな尺度(スケール)で入力されるデータを、扱いやすい一定のルールの中に収めることです。
想像してみてください。身長が150センチから190センチのグループと、体重が40キロから100キロのグループを比較したいとき、そのままの数字を扱うと「190」という数字の方が「100」よりも大きいから重要だ、とAIが勘違いしてしまうかもしれません。
これを防ぐために、すべてのデータを 0 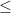
専門用語を攻略しよう:平均と標準偏差
ここで、高校の数学で登場する「平均」と「標準偏差」という言葉を思い出しましょう。
- 平均(
):データの合計を個数で割った、いわゆる「真ん中」の値です。
- 標準偏差(
):データが平均からどれくらい「バラついているか」を表す指標です。
Normalization層では、個々のデータから平均を引き、それを標準偏差で割るという計算を頻繁に行います。
数式で表すと、元のデータを 
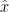
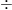
という形になります。
これを行うことで、どんなに大きな数字も、平均を中心としたコンパクトな範囲に収まってしまうのです。魔法のようではありませんか。
なぜNormalizationが必要なのか?そのメリット
Normalization層を導入することで、AIの学習には劇的な変化が起こります。
学習速度が飛躍的にアップする
AIの学習は、いわば「暗闇の中で山の頂上からふもとにあるゴールを目指す」ような作業です。データがバラバラだと、地面がデコボコで足元をすくわれ、なかなか進めません。しかし、正規化によってデータが整うと、地面が綺麗に舗装された滑走路のようになり、ゴールまで最短距離で突っ走ることができるようになります。
初期値の影響を受けにくくなる
AIが学習を始めるとき、最初はランダムな数字(初期値)を持っています。この初期値が少しズレているだけで、以前は学習が失敗することもありました。Normalization層は、データが極端に大きくならないよう常にブレーキをかけてくれるため、多少の初期値のズレを物ともせずに学習を安定させてくれます。
Normalization層にも弱点はある?デメリットの理解
完璧に見えるNormalization層ですが、いくつか注意点があります。
計算コストが増える
当たり前ですが、データを一つひとつ計算し直すため、コンピューターの計算量が増えます。非常に巨大なAIを動かす場合、このわずかな計算の積み重ねが、全体の処理時間を延ばす原因になることがあります。
データの「生の迫力」が失われることがある
データのバラツキそのものに重要な意味がある場合、無理やり平均 0 に押し込めることで、その重要な特徴が消えてしまうリスクがあります。繊細な変化を読み取る必要があるAIを作るときは、この層をどこに入れるか、設計者のセンスが問われます。
Normalization層の種類
一言に正規化と言っても、実はいくつか種類があります。代表的なものを表にまとめました。
| 種類 | 特徴 | 活用シーン |
| Batch Normalization | データのまとまり(バッチ)ごとに平均を計算する | 画像認識など、標準的なAIで最も一般的 |
| Layer Normalization | 1つのデータ内のすべての項目で平均を計算する | 文章を理解するAI(ChatGPTなど)でよく使われる |
| Instance Normalization | 1つの画像のチャンネルごとに平均を計算する | 画像のスタイル変換(画風を変えるなど)に強い |
みなさんは、どの正規化が自分の作ってみたいAIに合っていると思いますか。
まとめと今後のステップ
Normalization層は、AIが迷わずに最短ルートで賢くなるための「道路整備」のような存在です。これがなければ、現代の高度なAIの発展はなかったと言っても過言ではありません。
この記事を読んで、正規化のイメージは掴めたでしょうか。もし興味が湧いてきたら、次は以下のステップに進んでみてください。
- Pythonのライブラリ(PyTorchやTensorFlow)を使って、実際にNormalization層を一行書いて動かしてみる。
- 「バッチサイズ」を変えたときに、Batch Normalizationの結果がどう変わるか実験してみる。
- 学習の推移をグラフにして、Normalization層があるときとないときで、どれだけ正解率の上がりが違うかを確認する。
理論が分かったら、次はぜひ手を動かして「AIを育てる感覚」を味わってみてください。
もっと深く知りたい特定の正規化手法はありますか。もしあれば、いつでも教えてくださいね。
セイ・コンサルティング・グループでは新人エンジニア研修のアシスタント講師を募集しています。
投稿者プロフィール
- 代表取締役
-
セイ・コンサルティング・グループ株式会社代表取締役。
岐阜県出身。
海外放浪の末、2000年創業、2004年会社設立。
IT企業向け人材育成研修歴業界歴20年以上。
すべての無駄を省いた費用対効果の高い「筋肉質」な研修を提供します!
この記事に間違い等ありましたらぜひお知らせください。
学生時代は趣味と実益を兼ねてリゾートバイトにいそしむ。長野県白馬村に始まり、志賀高原でのスキーインストラクター、沖縄石垣島、北海道トマム。高じてオーストラリアのゴールドコーストでツアーガイドなど。現在は野菜作りにはまっている。
最新の投稿
 山崎講師2026年8月2日匿名加工情報とは:最も保護レベルが低い情報形式を理解する
山崎講師2026年8月2日匿名加工情報とは:最も保護レベルが低い情報形式を理解する- 山崎講師2026年8月2日仮名加工情報の役割を理解する:個人情報から一歩進んだデータ活用
- 山崎講師2026年8月2日個人情報の種類を理解する:要配慮個人情報とは何か
- 山崎講師2026年8月2日オプトインとオプトアウト:Webサービスでの同意の仕組みを理解する
