
決定版!機械学習の数式記号マスター・ロードマップ
 山崎講師
山崎講師こんにちは。ゆうせいです。
機械学習の数式を読み解くための「記号の読み方ガイド」、いよいよ総まとめの時間がやってきました!これまでの連載で紹介してきた記号たちは、AIという複雑なパズルを組み立てるためのピースそのものです。
今回は、研修講師として皆さんの頭の中を整理するために、これまで登場したすべての記号を一気に振り返ります。これを読めば、数式アレルギーも完全に克服できるはずですよ!
数学の記号は、一見すると冷たくて難しそうに見えます。しかし、その実態は「思考のショートカット」です。長ったらしい日本語を、たった一文字で表現してくれる便利な道具だと考えてみてください。
それでは、役割ごとにグループ分けして復習していきましょう!
セッション1:数式の文法を司る5つの記号
機械学習の数式をパッと見たとき、どこで区切って読めばいいか迷ったことはありませんか?グループ1の記号たちは、数式という文章の中にある「句読点」や「強調マーク」の役割を果たしています。
1. カンマ  とセミコロン
とセミコロン  の使い分け
の使い分け
この2つは特によく似ていますが、込められた意味は全く違います。
- カンマ
これは「変数
と
の両方が主役ですよ」という合図です。
- セミコロン
機械学習では、
がモデルのパラメータ(設定)を表します。
例えば、スマートフォンのカメラアプリを想像してください。写る景色が
2. コロン  で新しいルールを作る
で新しいルールを作る
数式で 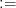

これは「これから『ロス(誤差)』という言葉が出てきたら、この計算式のことを指すと決めるよ!」という宣言です。
普通のイコール 
3. ハット  が教える「AIの予想」
が教える「AIの予想」
文字の上にチョコンと乗った
これは「予測値(ハット)」と呼びます。
帽子を被っていない 
テストの点数で例えるなら、
4. 縦棒  が作る「もしも」の世界
が作る「もしも」の世界
確率の式でよく登場する

これは「 

例えば、「今日が月曜日である
セッション2:データの形を整え、集計する5つの記号
プログラミングでいえば「配列」や「ループ処理」にあたる部分を、数学ではたった一文字の記号で表現してしまいます。
1. ギリシャ文字の王様、シグマ 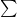
数式の中で最も目立つこの大きな記号は、総和(すべて足すこと)を意味します。

これは「 

クラス全員のテストの合計点を出すとき、一人ずつ順番に足していきますよね?その「全員分足す」という面倒な指示を、この一文字でスマートに伝えているのです。
2. 所属を示すエのような記号 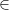
この記号は、あるデータがどのグループ(集合)の一員であるかを示します。

これは「 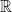
例えば、パーティーの招待客リスト 
3. 右上の  でデータの向きを変える「転置」
でデータの向きを変える「転置」
アルファベットの右上に小さく書かれた

これは、データの「縦と横」を入れ替える、いわばデータの衣替えです。
機械学習の計算では、パズルのピースをはめるように、データの向きをピタッと合わせる必要があります。例えば、縦に並んだデータを横向きに寝かせることで、次の計算ができるように準備を整えてあげる「気遣い」の記号だと思ってください。
4. データを一つに凝縮するドット 
数式の真ん中に置かれるドット

これは、2つのデータの集まりを掛け合わせ、最終的にたった一つの「数字」にまとめ上げる集計ボタンです。
スーパーのレジで、「商品の単価リスト」と「買った個数リスト」をそれぞれ掛け算して、最後に「合計金額」という一つの数字を出すイメージですね!
5. データの掛け算のパレード、プロダクト 
パイのような形をした記号がプロダクト

シグマ
「1番目から
機械学習では、複数の確率を掛け合わせるシーンでよく登場します。
例えば、「今日晴れる確率」 
セッション3:変化と最適化を司る4つの記号
AIが試行錯誤して正解に近づくプロセスは、まるで山を下って一番低い場所にある「ゴール」を探すようなものです。
1. 坂道の向きを教えるナブラ 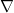
逆三角形の形をした

これは、関数の値が「どの方向に動けば一番大きく増えるか」という、坂道の傾き具合を示す方位磁石です。
AIの学習では、このナブラと逆の方向、つまり「一番急に値が下がる方向」へ少しずつ進むことで、誤差(ミス)を最小限にしていきます。これがいわゆる「勾配降下法」の正体です!
2. 最高の結果を指名する 
この記号は、結果そのものではなく「結果を出した原因」に注目します。

普通の 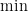
例えるなら、テストの最低点を探すのが
3. おおらかなイコール、近似 
波打つイコールの

数学の世界は厳密ですが、機械学習の実践では「計算が複雑すぎるから、だいたいこの値として扱おう」という場面がよくあります。
「完璧に一致はしていないけれど、実用的にはこれで十分!」という、エンジニアらしい合理的な妥協を表現している記号です。
4. 運命共同体を示す比例 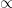
魚のような形をした

これは「
機械学習の理論では、非常に複雑な計算式のなかで「結局、どの変数を動かせば結果に影響するのか」というエッセンスだけを抜き出すために、この記号を使って式をスッキリさせることがあります。
セッション4:データの個性と影響力を測る4つの記号
データの中には、大きな値もあれば小さな値もあります。それらを公平に、あるいは戦略的に評価するためのツールを紹介します。
1. データの「大きさ」を測るノルム 
変数を縦の二重線で囲んだ

これは、データの「原点からの距離」や「長さ」を表す物差しです。
機械学習では、モデルの「重み」が大きくなりすぎないように制限をかける場面でよく登場します。重みが大きすぎるのは、いわば「特定のデータにこだわりすぎている(過学習)」状態です。ノルムを使ってその大きさをチェックし、「重くなりすぎないように!」とブレーキをかける役割を担っています。
2. 平均的な振る舞いを予言する期待値 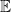
白抜きの特殊な字体で書かれた
![\mathbb{E} [ x ]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D+%5B+x+%5D&bg=ffffff&fg=000&s=0&c=20201002)
これは、何度も実験を繰り返したときに得られる「平均的な結果」のことです。
AIは個々のデータに一喜一憂するのではなく、この期待値を見て「全体として誤差が最小になるか」を判断します。いわば、一時的な流行に惑わされず、長期的な平均点を見据える「賢者の視点」の記号ですね。
3. 微細な変化を捉える偏微分 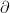
少し丸まった

機械学習には、たくさんの変数(スイッチ)が登場します。この記号は、「他のスイッチには触れず、 
どのスイッチを回せば一番効率よく誤差が減るか。それを探るための「精密な調査」の記号だと考えてください。
4. 変化のステップを示すデルタ 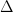
三角形の

これは「今の状態からこれだけ動かしました」という、ビフォーアフターの差を表します。
偏微分
記号をマスターすることのメリットとデメリット
メリット
- 専門書や最新の論文が、まるで物語のように読めるようになります。
- プログラミングで「なぜこの計算が必要なのか」という理由が明確になります。
- 複雑な仕組みを、他人にスマートに説明できるようになります。
デメリット
- 記号に慣れすぎると、つい普通の会話でも専門用語を使ってしまい、周囲をポカンとさせてしまうかもしれません(笑)。
- 数学的な厳密さにこだわりすぎると、全体像を見失うことがあります。
まとめと今後の学習指針
ここまで、本当にお疲れ様でした!これだけの記号を理解できたなら、あなたはもう機械学習の初心者ではありません。
これからの学習では、ぜひ以下のステップに挑戦してみてください。
- 数式の写経:有名なアルゴリズムの数式を、手書きでノートに書き写してみましょう。
- コードとの対応付け:数式の一部分が、Pythonのコードのどの行に対応しているかを探してみましょう。
- 人に教える:今回学んだ例え話を使って、友人に記号の意味を説明してみてください。
記号は言葉です。使えば使うほど、あなたの血肉となって馴染んでいきます。
セイ・コンサルティング・グループでは新人エンジニア研修のアシスタント講師を募集しています。
投稿者プロフィール
- 代表取締役
-
セイ・コンサルティング・グループ株式会社代表取締役。
岐阜県出身。
海外放浪の末、2000年創業、2004年会社設立。
IT企業向け人材育成研修歴業界歴20年以上。
すべての無駄を省いた費用対効果の高い「筋肉質」な研修を提供します!
この記事に間違い等ありましたらぜひお知らせください。
学生時代は趣味と実益を兼ねてリゾートバイトにいそしむ。長野県白馬村に始まり、志賀高原でのスキーインストラクター、沖縄石垣島、北海道トマム。高じてオーストラリアのゴールドコーストでツアーガイドなど。現在は野菜作りにはまっている。
最新の投稿
 山崎講師2026年8月2日匿名加工情報とは:最も保護レベルが低い情報形式を理解する
山崎講師2026年8月2日匿名加工情報とは:最も保護レベルが低い情報形式を理解する- 山崎講師2026年8月2日仮名加工情報の役割を理解する:個人情報から一歩進んだデータ活用
- 山崎講師2026年8月2日個人情報の種類を理解する:要配慮個人情報とは何か
- 山崎講師2026年8月2日オプトインとオプトアウト:Webサービスでの同意の仕組みを理解する
