勾配降下法を使わない機械学習の世界へようこそ
 山崎講師
山崎講師こんにちは。ゆうせいです。
機械学習というと、多くの人が「勾配降下法」のように、山の頂上からふもとを目指して少しずつ降りていくような計算をイメージします。でも、実はそんな難しい「坂道歩き」をしなくても、パッと答えを出せる手法があることを知っていますか?
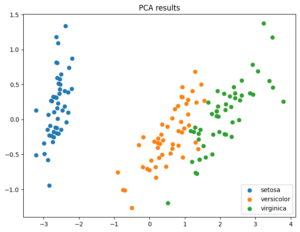
今回は、勾配降下法を使わずに、もっとシンプルで人間らしい判断基準で動く2つのベーシックな手法、決定木とk近傍法についてお話しします。
YESかNOで道を切り拓く「決定木(けっていぎ)」
決定木は、まるで「YES/NO診断」のような仕組みでデータを分類する手法です。複雑な数式の傾きを計算する代わりに、データを最も効率よく分けられる「質問」を自動で作っていきます。
専門用語を攻略しよう:不純度(ふじゅんど)
決定木が賢い質問を作るために使う基準が不純度です。
これを高校の「クラス替え」で例えてみましょう。
1つの教室に、野球部と吹奏楽部がバラバラに座っている状態は、中身が混ざっていて不純度が高いと言えます。ここで「運動部ですか?」という質問をして、野球部と吹奏楽部をきれいに2つの教室に分けることができれば、不純度は一気に下がります。
決定木は、この不純度を最も下げてくれる質問を順番に見つけ出し、木のような形に組み上げていくのです。
- メリット:判断のプロセスが目に見えるので、なぜその結論になったのかを人間に説明しやすいです。
- デメリット:あまりに細かく枝分かれさせると、手元のデータにだけ詳しすぎて、新しいデータに対応できない「過学習」という状態に陥ります。
似た者同士でグループを作る「k近傍法(けいきんぼうほう)」
k近傍法は、新しいデータがやってきたときに「君の近くにいる人たちは誰?」と周りを見渡して、その正体を決める手法です。勾配を下るどころか、学習というステップすらほとんどありません。
専門用語を攻略しよう:ユークリッド距離
「近くにいる」ことを正確に測るために使うのがユークリッド距離です。
これは、数学の授業で習う「2点間の直線距離」のことです。
例えば、あるデータの位置を 

距離

この距離を計算して、近い順に 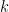
- メリット:仕組みがシンプルで、データが増えても柔軟に対応できます。
- デメリット:判定するたびに周りの全データとの距離を計算するため、データの数が増えるほど計算に時間がかかってしまいます。
どちらの武器が使いやすそう?
決定木とk近傍法、どちらも「勾配(傾き)」を使わずに答えを出せる非常に強力なツールです。
| 比較項目 | 決定木 | k近傍法 |
| 判断のルール | 条件分岐の積み重ね | 近くにいるデータの多数決 |
| 計算のタイミング | 事前に「木」を作る時 | 答えを出す「その瞬間」 |
| 向いていること | 理由をはっきりさせたい時 | 直感的に分類したい時 |
今後の学習の指針
まずは、この2つの手法が「計算の坂道」を必要としない理由をイメージしてみてください。
これらが理解できたら、次は「たくさんの決定木を集めて、みんなで多数決をとる」という、アンサンブル学習(ランダムフォレストなど)に挑戦してみるのがおすすめです。1人(1本の木)では間違えることもありますが、チーム(たくさんの木)になれば、より正確な判断ができるようになる、という面白い進化を体験できますよ。
次は、実際にこれらの手法をプログラミングで動かしてみる方法について、一緒に調べてみませんか?
セイ・コンサルティング・グループでは新人エンジニア研修のアシスタント講師を募集しています。
投稿者プロフィール
- 代表取締役
-
セイ・コンサルティング・グループ株式会社代表取締役。
岐阜県出身。
海外放浪の末、2000年創業、2004年会社設立。
IT企業向け人材育成研修歴業界歴20年以上。
すべての無駄を省いた費用対効果の高い「筋肉質」な研修を提供します!
この記事に間違い等ありましたらぜひお知らせください。
学生時代は趣味と実益を兼ねてリゾートバイトにいそしむ。長野県白馬村に始まり、志賀高原でのスキーインストラクター、沖縄石垣島、北海道トマム。高じてオーストラリアのゴールドコーストでツアーガイドなど。現在は野菜作りにはまっている。
最新の投稿
 山崎講師2026年8月1日コンピューターが数値計算の誤差に対処する仕組みと精度管理の方法
山崎講師2026年8月1日コンピューターが数値計算の誤差に対処する仕組みと精度管理の方法- 山崎講師2026年8月1日0乗が1になる理由を2乗の計算式から解説する指数法則の基礎
- 山崎講師2026年8月1日機械学習モデルの予測理由を解釈するSHAPとシャープレイ値の基礎
- 山崎講師2026年8月1日適合率と再現率の概念と初心者向けのわかりやすい再翻訳案