検索結果を操る魔法?AI時代の必須知識「相互情報量」を世界一わかりやすく解説
 山崎講師
山崎講師こんにちは。ゆうせいです。
検索結果を操る魔法?AI時代の必須知識「相互情報量」を世界一わかりやすく解説
相互情報量とは何か
みなさんは、ある言葉を聞いたときに、次に続く言葉をパッと予想できたことはありませんか。
例えば「明日の天気は」と言われれば、「晴れ」や「雨」といった言葉が頭に浮かびますよね。
このように、一つの情報がわかったときに、もう一方の情報がどれくらい予測しやすくなるかを表す指標を、専門用語で相互情報量と呼びます。
相互情報量は、二つの出来事がどれだけ密接に関係しているかを測る物差しだと考えてください。
全く関係のない二つの出来事であれば、この物差しは 0 を指します。
逆に、片方を知ればもう片方が手に取るようにわかる関係なら、この数値は大きくなります。
Theとdog、dogとbarkingを比較してみよう
言葉の結びつきの強さを、具体的な英単語の例で考えてみましょう。
今回は「The」と「dog」、そして「dog」と「barking(吠える)」という二つの組み合わせを比較します。
Theとdogの関係
英語の文章を読んでいると、「The」という言葉には数え切れないほど出会います。
あまりに頻繁に登場するため、「The」の次に「dog」が来る確率は、実はそれほど高くありません。
「The cat」かもしれないし、「The apple」かもしれません。
「The」が出たからといって、次に「dog」が来ると確信を持つのは難しいですよね。
この場合、二つの言葉が持っている相互情報量は小さくなります。
まるで、誰にでも愛想を振りまく人気者のように、特定の相手との絆が薄い状態と言えるでしょう。
dogとbarkingの関係
一方で、「dog」と「barking」はどうでしょうか。
「barking(吠える)」という言葉は、ほとんどの場合、犬に関連して使われます。
「吠えている」という情報があれば、その主語が「犬」である可能性は極めて高いと言えます。
このように、一方が現れたときにもう一方が強く連想される関係は、相互情報量が非常に大きくなります。
これは、まるでお互いがいなければ成立しない、相思相愛のカップルのような関係です。
実際に計算してみよう
それでは、この関係性を数式で表してみましょう。
相互情報量を計算するには、それぞれの単語が出る確率と、セットで出る確率を比べます。
計算式のルール
相互情報量を求める基本の式は、以下の通りです。
相互情報量 = 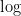
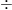

もし A と B が全く無関係なら、分子と分母が同じ値になり、全体は
関係が深ければ深いほど、この数値はプラスに増えていきます。
具体的な数値例
仮に、10,000語の文章データがあると想定して計算してみましょう。
| 単語の組み合わせ | 単語Aの出現数 | 単語Bの出現数 | 同時に出る回数 |
| The と dog | 1,000回 | 100回 | 50回 |
| dog と barking | 100回 | 20回 | 15回 |
まずは、The と dog の相互情報量を計算します。
- 二つが同時に出る確率は 50
- Theが出る確率は 1,000
- dogが出る確率は 100
式に当てはめると、 0.005
この 5 という数字に
次に、dog と barking を計算してみましょう。
- 二つが同時に出る確率は 15
- dogが出る確率は 100
- barkingが出る確率は 20
式に当てはめると、 0.0015
結果を見て驚きませんか。
dog と barking の組み合わせの方が、数値が圧倒的に大きくなりましたね。
これは、barking という言葉が dog といかに強く結びついているかを数字が証明しているのです。
相互情報量を学ぶメリットとデメリット
この技術を理解すると、どんな良いことがあるのでしょうか。
メリット
- 検索エンジンの精度向上:ユーザーが調べたい内容を予測しやすくなります。
- 翻訳の質:不自然な言葉の組み合わせを排除し、滑らかな文章を作れます。
- データの整理:大量の情報から、本当に意味のある関連性だけを抽出できます。
デメリット
- 計算コスト:膨大なデータの組み合わせを計算するには、高いマシン性能が必要です。
- データの偏り:たまたま一緒に使われただけの言葉を、強い関係があると誤解する場合があります。
まとめとこれからの学習
相互情報量は、私たちが普段無意識に行っている連想ゲームを、数学の力で客観的に見える化したものです。
機械が人間の言葉を理解しようとする際、この概念は欠かせない土台となっています。
まずは、身近な言葉のペアを見つけて、どちらの結びつきが強そうか予想してみてください。
次のステップとしては、情報のバラツキ具合を表すエントロピーという概念を学んでみるのがおすすめです。
確率や統計の世界は、知れば知るほど世の中の仕組みがクリアに見えてきますよ。
セイ・コンサルティング・グループでは新人エンジニア研修のアシスタント講師を募集しています。
投稿者プロフィール
- 代表取締役
-
セイ・コンサルティング・グループ株式会社代表取締役。
岐阜県出身。
海外放浪の末、2000年創業、2004年会社設立。
IT企業向け人材育成研修歴業界歴20年以上。
すべての無駄を省いた費用対効果の高い「筋肉質」な研修を提供します!
この記事に間違い等ありましたらぜひお知らせください。
学生時代は趣味と実益を兼ねてリゾートバイトにいそしむ。長野県白馬村に始まり、志賀高原でのスキーインストラクター、沖縄石垣島、北海道トマム。高じてオーストラリアのゴールドコーストでツアーガイドなど。現在は野菜作りにはまっている。
最新の投稿
 山崎講師2026年8月2日指数と対数は何が違うのか:逆の関係を理解する
山崎講師2026年8月2日指数と対数は何が違うのか:逆の関係を理解する- 山崎講師2026年8月2日自然対数eはどこから生まれたのか:歴史から理解する定数の意味
- 山崎講師2026年8月2日片側検定と両側検定の使い分け方を具体例から学ぶ
- 山崎講師2026年8月1日コンピューターが数値計算の誤差に対処する仕組みと精度管理の方法